
簡介
T. Stricker於1997年在其論文中介紹了存儲器山的思想,利用它對存儲器系統進行全面描述,並在後來的工作中提出了術語“存儲器山”。卡耐基梅隆大學教授Randal Bryant的著作《深入理解計算機系統》一書亦提出了存儲器山的概念,並進行了詳細分析。
理論上,每台計算機都有一個唯一的存儲器山。通過運行一段測試程式,可以得到它的存儲器山。了解存儲器山,對應用程式的最佳化能起到指導作用。
下圖展示了一個基於Intel Core 2 Duo 處理器的存儲器山。
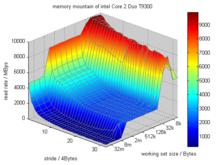 存儲器山
存儲器山存儲器山測試原理
為了說明存儲器山的測試程式的原理,首先簡要介紹局部性和存儲器層次結構這兩個重要概念,然後介紹存儲器山的定義和測試程式的原理模型 。
局部性
通常,一個編寫良好的(最佳化的)程式具有良好的局部性,主要表現在兩個方面。
1)時間局部性(Temporal locality):
如果被訪問過的存儲器地址在較短時間內被再次訪問,則程式具有良好的時間局部性。
在一定的時間內,重複訪問同一個地址的次數越多,時間局部性越好。
換句話說,對同一個地址的兩次訪問間隔時間越短,時間局部性越好。
2)空間局部性(Spatial locality):
如果程式訪問某個存儲器地址後,又在較短時間內訪問臨近的存儲器地址,則程式具有良好的空間局部性。兩次訪問的地址越接近,空間局部性越好。
局部性在程式中普遍存在。好的程式通常具有好的局部性,是一個普適的原理。
存儲器層次結構
不同類型的存儲設備,其訪問速率相差很大。
其基本規律為:訪問速率越高的設備,單位容量的成本越高,於是越不容易做得很大。計算機系統的設計者需要在控制成本的同時,儘量提高存儲器系統的速率。
受益於局部性的概念,計算機的存儲器系統通常設計成一個層次結構,CPU內部的暫存器為該層次結構的最高層----它的容量最小,但速率最高。往下依次為各級cache,主存,磁碟等等。
該層次結構的運行策略是:
儘量讓當前被頻繁訪問的存儲區的內容駐留在較高層存儲器,作為代價,把不常訪問的存儲區的內容置換到較低層存儲器。同時,儘量讓當前被訪問的元素附近的元素也駐留在較高層存儲器。一個具有良好的局部性的程式,幾乎能總是訪問高層的存儲器,享受到最高的訪問速率。
從程式設計師的角度來看,要儘量編寫具有良好的局部性的程式,以適應層次結構,提高程式運行速率。
存儲器山測試程式
具有不同的時間局部性和空間局部性的程式,對存儲器層次結構的利用效率是不同的。局部性較好,則能得到較快的訪問速率。構造一個存儲器測試程式,以不同的時間局部性和空間局部性對存儲器進行訪問,就能得到存儲器系統在不同的局部性下的性能(即訪問速率)。以控制時間局部性的變數為x軸,控制空間局部性的變數為y軸,存儲器訪問速率為z軸,就能得到一個三維圖形,它看起來像一座有著山峰,山脊和山坡的小山,即 存儲器山。
通過存儲器山,可以直觀地看到具有不同的時間局部性和空間局部性的程式對存儲器的訪問速率的巨大差別。可作為程式設計師最佳化程式的參考。
更加有趣的是,通過分析存儲器山的數據,還可以看出存儲器系統的部分硬體參數。包括L1數據cache(簡稱為L1-Dcache)、L2-cache和主存(物理介質通常為SDRAM)各自的最高平均速率,L1-Dcache和L2-cache的容量,甚至L1-Dcache的行尺寸。
不過,存儲器山並非萬能工具。從中無法看出cache的相聯度、訪問延遲等參數(這些參數可以用其他測試程式間接得出,但無法從存儲器山測試程式中得出)。由於連續密集訪問,cache預取(Prefetching)也會被阻塞從而無法體現其效果。
存儲器山測試程式的核心就是這樣一個循環:
其中,data是一個整形數組(整形元素單位為4位元組),result是一個暫存器變數。Kernel_loop所做的事情,就是將data數組的內容依次讀取到CPU的暫存器中。參數elems表示data數組的尺寸,即工作集(working set)尺寸。參數stride表示訪問時的步長,即相鄰兩次訪問的元素的地址間隔。
用Get_readrate()函式來獲取特定參數下Kernel_loop的讀速率:
main()函式改變elems和stride參數的大小,記錄Kernel_loop在各個參數下的讀速率:
以elems為x軸,stride為y軸,readrate為z軸,即可得到一座存儲器山。這裡,elems控制時間局部性。因為當stride固定時,elems越小,對同一個地址的兩次訪問(cache預熱時一次,真正測試時一次)間隔的時間越短。而stride控制空間局部性。因為stride越小,相鄰兩次訪問的地址間隔越小。readrate即是不同時空局部性下對存儲器的讀速率。MINELEMS、MAXELEMS、MAXSTRIDE等常量的具體數值根據測試平台的參數來選擇。
簡要分析
固定步長不變,可以明顯看到,當工作集尺寸不大於32Kbytes時,讀速率最高。當工作集尺寸介於32Kbytes與8Mbytes之間時,讀速率明顯降低。當工作集尺寸大於8Mbytes時,讀速率最低。這是由於工作集的尺寸決定了由哪一層存儲器來提供待讀取的數據。小於32KBytes的工作集可以完全存放在L1-Dcache中,介於32Kbytes與8Mbytes之間的工作集不能完全存放在L1-Dcache中,但可以完全存放在L2-cache中(準確地說,6Mbytes以上的工作集就不能完全存放在L2-cache中了,但由於工作集尺寸呈指數增長,圖中無法準確反映6Mbytes時的情況)。
當工作集尺寸小於32Kbyte時,讀速率有明顯的下降。看起來似乎違背了時間局部性的原理----越小的工作集,性能反而越低。事實上這是Kernel_loop()的額外開銷造成的----在該區域,工作集越小,步長越大,則Kernel_loop()的循環次數越少,該額外開銷占總開銷的比例就越大,導致最終換算出來的讀速率越小。所以這個區域不能反映L1-Dcache的真實性能。
而當工作集尺寸固定時,不同的步長也會導致不同的讀速率。例如,固定工作集尺寸為512Kbytes,由於工作集尺寸大於L1-Dcache容量,此時測試程式Kernel_loop()的讀操作會遇到L1-Dcache缺失,需要從L2-cache中讀取數據。隨著步長從1個字增加到16個字,讀速率逐漸下降。步長位於16個字和32個字之間時,讀速率不變,保持在一個較低的值(約2100MBps)上。
這是由於L1-Dcache的每次缺失,都會從L2-cache中讀回一行數據(行尺寸64bytes,即16個字),隨後對這一行的其他部分的讀取,就都能由L1-Dcache服務,得到較高的讀速率。所以,當步長小於16個字的時候,L1-Dcache的服務會提高讀速率。當步長大於16個字的時候,每一次讀操作都會缺失,所有的數據都需要從L2-cache中讀取,讀速率就穩定等於L2-cache的讀速率了。
