
基本概念
向量處理器系統(Vector Processor System,VPS),是面向向量型並行計算,以流水線結構為主的並行處理計算機系統。 採用先行控制和重疊操作技術、運算流水線、交叉訪問的並行存儲器等並行處理結構,對提高運算速度有重要作用。但在實際運行時還不能充分發揮並行處理潛力。向量運算很適合於流水線計算機的結構特點。向量型並行計算與流水線結構相結合,能在很大程度上克服通常流水線計算機中指令處理量太大、存儲訪問不均勻、相關等待嚴重、流水不暢等缺點,並可充分發揮並行處理結構的潛力,顯著提高運算速度。
向量運算是一種較簡單的並行計算,適用面很廣,機器實現比較容易,使用也比較方便,因此向量處理機(向量機)獲得了迅速發展。TI ASC(1972年)和CDC STAR-100 (1973年)是世界上第一批向量巨型計算機(巨型機)。到1982年底,世界上約有60台巨型機,其中大多數是向量機。中國於1983年研製成功的每秒千萬次的757機和億次的“銀河”機也都是向量機。
向量機適用於線性規劃、傅立葉變換、濾波計算以及矩陣、線性代數、偏微分方程、積分等數學問題的求解,主要解決氣象研究與天氣預報、航空航天飛行器設計、原子能與核反應研究、地球物理研究、地震分析、大型工程設計,以及社會和經濟現象大規模模擬等領域的大型計算問題。
向量運算
在普通計算機中,機器指令的基本操作對象是標量,而向量機除了有標量處理功能外還具有功能齊全的向量運算指令系統。
對一個向量的各分量執行同一運算,或對同樣維數的兩個向量的對應分量執行同一運算,或一個向量的各分量都與同一標量執行同一運算,均可產生一個新的向量,這些是基本的向量運算。此外,尚可在一個向量的各分量間執行某種運算,如連加、連乘或連續比較等操作,使之綜合成一個標量。為了提高向量處理能力,基本型向量運算在執行中可以有某種靈活性,如在位向量控制下使某些分量不執行操作 ,或增加其他特殊向量操作,如兩個維數不等的單調上升整數向量的邏輯合併、向量的壓縮和還原。
基本結構
一個向量處理器通常由一個普通的流水化的標量單元加上一個向量單元組成。在這個向量單元里的所有功能部件都有幾個時鐘周期的延遲。這使得能夠使用較短的時鐘周期,並且與複雜的需要深度流水化來避免數據 hazard的向量運算兼容。大多數的向量處理器所允許的向量運算包括浮點運算,整型運算或者邏輯運算。這裡我們重點關注浮點運算。實際上商用的向量處理器裡面都同時包含了亂序的標量單元(NEC SX/5)和VLIW的標量單元(Fujitsu VPP5000)。
向量處理器主要有兩種類型:向量-暫存器(vector-register)處理器和記憶體-記憶體(memory-memory)處理器。在vector-register類的處理器中,所有的向量操作,除了load和store都是在向量暫存器(vector register)裡面進行的。這類的處理器就和我們在標量處理器裡面談過的load-store體系結構相對應。在80 年代後期發布的幾乎所有向量計算機都採用了這個結構,這其中包括Cray Research的處理器(Cray-1,Cray-2,X-MP,YMP,C90,T90,SV1 和 X1),日本的超級計算機(從NEC SX/2 到 SX/8,Fujitsu VP200到VPP5000,以及Hitachi S820 和 S-8300)以及迷你超級計算機(從 Convex C-1 到 C-4)。在 memory-memory 類的向量處理器中,所有的向量運算都是從記憶體到記憶體的。第一個向量處理器就是這種類型,CDC 系列的亦是如此。
下圖是Fujitsu VP2000系列系統結構圖:
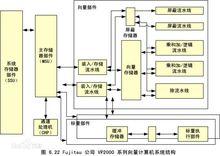 向量處理器系統
向量處理器系統結構的優勢
向量超級計算機的市場已經非常小了,但是向量超級計算機所使用的向量指令體系結構(Vector Instruction Set Architecture VISA)和它的向量指令集是依然很有優勢的。隨著集成度的提高,我們很快將達到“延時極限”,而向量指令系統結構提供了提高性能的一種途徑。
VISA相對於標量以及VLISW ISA的優勢可以從三個方面來歸納。其一:語義優勢,也就是說用VISA來書寫程式能更簡潔更有效。其二:向量指令可以更容易實現並行化的編碼,利於高度並行化的實現。其三:向量指令工整而且它有利於並行化,這使得向量指令有利於提高設計處理器技術,比如深度流水線的設計,資源重複的實現,以及縮短時鐘周期。以下幾點充分地體現了向量指令集的優勢:
(1)向量程式精簡,所需操作步數少
向量指令和標量指令最大的差別在於一條向量指令包含了很多操作。因此,執行一個給定的任務,向量指令比標量指令組成的程式要少得多。而且標量程式要計算地址,循環變數和分支地址,而這些都是隱含在向量指令里的。執行代碼量的減少帶來了很多有益的結果,首先,指令數量減少使得主存和處理器之間的數據交換量也隨著減少;其次,向量操作中分支指令的執行被隱含起來,這樣也就減少了大部分由於分支預測失誤帶來的延時;再次,僅需一個很簡單的控制單元,在每個周期取一條指令解碼執行,可以得到很高的運算效率。所以,向量指令集在執行的時候只需要很簡單的控制器,避免了在運行的時候花費過多的時鐘周期。
(2)存儲系統的性能高,利用充分
以向量的方式來訪問記憶體有很多好處。首先:處理機所需的每個數據項都是真正所要用到的數據,而不是由Cache來支持的所謂的預取。其次:訪存的信息直接由硬體來傳輸,這些信息能夠通過很多方法來提高存儲系統的性能。當遇到存儲器延時,對記憶體操作的向量指令能夠把一段長的延時劃分為很多小的時間段。一些研究已經表明在向量處理器上使用類似於超標量流水線的技術,即使是上百個周期的主存延時,也不會造成太大的性能損失。
(3)向量處理器具有低功耗和高實時性的特徵
針對未來的套用系統,低功耗和高實時性會成為計算機設計中一個很重要的因素。而在這方面,向量體系結構的系統具有相當的優勢。
向量指令具有“局部計算”的特性,也就是說,當一條向量指令開始執行,只有對應的功能單元和暫存器內聯匯流排需要加電。取指部件,取指緩衝暫存器等其它大功耗部件可以處於休眠狀態,直到當前向量指令執行完成才恢復狀態重新工作。使用了向量ISA的系統可以方便地工作於低功耗狀態。例如,某運算需要兩條向量指令並行執行,或同一條指令需要執行兩次,僅需要最少的功能部件和匯流排部件工作,而不象超標量處理機那樣重複取相同的循環指令來執行,從而可以很方便的減小功耗。針對實時應用程式,向量計算機可以被設計為具有高度可預測、高度自主決策的系統。提高實時性能時,令設計者頭疼的Cache失效和分支預測的問題將不再需要考慮,向量體系結構高度結構化的特徵使得向量體系結構簡單、可決策化,具有高實時性的潛力 。
套用
向量機一般配有向量彙編和向量高級語言,供用戶編制能發揮具體向量機速度潛力的向量程式。只有研製和採用向量型並行算法,使程式中包含的向量 運算越多、向量越長,運算速度才會越高。面向各種套用領域的向量程式庫的建立,能方便用戶使用和提高向量機的解題效率。向量識別程式是編譯程式中新開發的一部分,用於編譯時自動識別採用通常串列算法的源程式中的向量運算成分,並編譯成相應的向量運算目標程式,以提高向量機計算大量現存非向量程式的計算速度。向量識別技術還有待進一步發展和完善,以提高識別水平。
向量處理機的發展方向是多向量機系統或細胞結構向量機。實現前者須在軟體和算法上取得進展,解決如任務劃分和分派等許多難題;後者則須採用適當的互連網路,用硬體自動解決因用戶將分散的主存當作集中式的共存使用而帶來的矛盾,才能構成虛共存的細胞結構向量機。它既具有陣列機在結構上易於擴大並行台數以提高速度的優點,又有向量機使用方便的優點。
