
分散式系統的類型
根據分散式系統的套用類型,可劃分出3種分散式系統。
分散式計算系統:可以進行高性能科學計算
分散式信息系統:主要負責信息管理和事務處理
分散式普適系統:在嵌入式套用領域套用廣泛。
由此可見分散式計算系統是分散式系統的一種類型。
分散式計算系統的類型
分散式計算系統通常根據計算方式的不同,分為計算機集群系統和計算機格線系統。
計算機集群系統
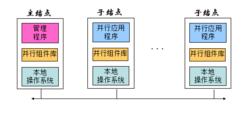 分散式計算系統
分散式計算系統計算機集群系統的結構如右圖所示。主結點是管理結點,負責管理程式、並行組件庫和本地作業系統。從結點是計算結點,使用並行應用程式、並行組件庫和作業系統進行計算。
其中,管理程式負責系統管理和配置、作業管理;並行組件庫是基於訊息的通信工具;本地作業系統為標準的通用OS;並行應用程式就是並行執行的應用程式。
計算機集群系統之間是同構的。主要採用集群計算。
計算機格線系統
計算機格線系統之間是異構的,是因為,在單個計算內部,各個之間的工作是分層次的,形似osi的七層模型,各層之間提供api相互進行鄰層的調用,但是各層內部的構成是地外透明的;
格線協定建立在網際網路協定之上,以網際網路協定中的通信、路由、名字解析為基礎。五層協定的格線體系結構分為光纖層、連線層、資源層、匯集層和套用層共五層。每層都可以有自己的服務、API和SDK,或者服務、APl和SDK中的部分。在這種層次結構中,上層協定的實現調用下層提供的功能。格線內的全局套用都通過協定提供的結構調用格線管理軟體的功能。
光纖層(Fabric),又叫做構造層。控制局部的資源,提供所需的接口。
連線層(Connectivity),由通信協定組成,支持格線事物的處理,延伸多個資源的使用。
資源層(Resource),管理、共享單一資源。
匯集層(Collective),匯集層負責對多個資源的訪問,協調各種資源。
套用層(Application)為格線上用戶的應用程式層,在虛擬組織環境中存在。
沙漏形狀的五層結構
五層沙漏結構是一個抽象層次結構,它的一個重要特點就是構成一個“沙漏”形狀。在沙漏結構中,資源層和連線層共同組成沙漏的瓶頸部分,為格線計算提供底層的通信、安全以及局部的資源管理。不同的高層(沙漏的頂部)行為映射到它們的上面,它們自身也能被映射到不同的基本技術之上(沙漏的底部),顯然瓶頸部分的核心協定的數量較少。較少的核心協定有利於移植,也比較容易地實現和得到支持。
格線計算與集群計算的區別
(1)簡單地,格線與傳統集群的主要差別是格線是連線一組相關並不信任的計算機,它的運作更像一個計算公共設施而不是一個獨立的計算機。格線通常比集群支持更多不同類型的計算機集合。
(2)格線本質上就是動態的,集群包含的處理器和資源的數量通常都是靜態的。在格線上,資源則可以動態出現,資源可以根據需要添加到格線中或從格線中刪除。
(3) 格線天生就是在本地網、城域網或廣域網上進行分布的。格線可以分布在任何地方。而集群物理上都包含在一個位置的相同地方,通常只是區域網路互連。集群互連技 術可以產生非常低的網路延時,如果集群距離很遠,這可能會導致產生很多問題。物理臨近和網路延時限制了集群地域分布的能力,而格線由於動態特性,可以提供 很好的高可擴展性。
(4)集群僅僅通過增加伺服器滿足增長的需求。然而,集群的伺服器數量、以及由此導致的集群性能是有限的:互連網路容量。也就是說如果一味地想通過擴大規模來提高集群計算機的性能,它的性價比會相應下降,這意味著我們不可能無限制地擴大集群的規模。 而格線虛擬出空前的超級計算機,不受規模的限制,成為下一代Internet的發展方向。
(5)集群和格線計算是相互補充的。很多格線都在自己管理的資源中採用了集群。實際上,格線用戶可能並不清楚他的工作負載是在一個遠程的集群上執行的。
儘管格線與集群之間存在很多區別,但是這些區別使它們構成了一個非常重要的關係,因為集群在格線中總有一席之地—— 特定的問題通常都需要一些緊耦合的處理器來解決。然而,隨著網路功能和頻寬的發展,以前採用集群計算很難解決的問題現在可以使用格線計算技術解決了。
並行計算與分散式計算的區別
(1)並行計算藉助並行算法和並行程式語言能夠實現進程級並行(如MPI)和執行緒級並行(如openMP)。而分散式計算只是將任務分成小塊到各個計算機分別計算各自執行。
(2)粒度方面,並行計算中,處理器間的互動一般很頻繁,往往具有細粒度和低開銷的特徵,並且被認為是可靠的。而在分散式計算中,處理器間的互動不頻繁,互動特徵是粗粒度,並且被認為是不可靠的。並行計算注重短的執行時間,分散式計算則注重長的正常運行時間。
(3)聯繫,並行計算和分散式計算兩者是密切相關的。某些特徵與程度(處理器間互動頻率)有關,而我們還未對這種交叉點(crossover point)進行解釋。另一些特徵則與側重點有關(速度與可靠性),而且我們知道這兩個特性對並行和分布兩類系統都很重要。
(4)總之,這兩種不同類型的計算在一個多維空間中代表不同但又相鄰的點。
主流的三大分散式計算系統
目前得到廣泛使用的三大分散式計算系統是Hadoop,Spark和Storm。
由於Google沒有開源Google分散式計算模型的技術實現,所以其他網際網路公司只能根據Google三篇技術論文中的相關原理,搭建自己的分散式計算系統。
Yahoo的工程師Doug Cutting和Mike Cafarella在2005年合作開發了分散式計算系統Hadoop。後來,Hadoop被貢獻給了Apache基金會,成為了Apache基金會的開源項目。Doug Cutting也成為Apache基金會的主席,主持Hadoop的開發工作。
Hadoop採用MapReduce分散式計算框架,並根據GFS開發了HDFS分散式檔案系統,根據BigTable開發了HBase數據存儲系統。儘管和Google內部使用的分散式計算系統原理相同,但是Hadoop在運算速度上依然達不到Google論文中的標準。
不過,Hadoop的開源特性使其成為分散式計算系統的事實上的國際標準。Yahoo,Facebook,Amazon以及國內的百度,阿里巴巴等眾多網際網路公司都以Hadoop為基礎搭建自己的分散式計算系統。
Spark也是Apache基金會的開源項目,它由加州大學伯克利分校的實驗室開發,是另外一種重要的分散式計算系統。它在Hadoop的基礎上進行了一些架構上的改良。Spark與Hadoop最大的不同點在於,Hadoop使用硬碟來存儲數據,而Spark使用記憶體來存儲數據,因此Spark可以提供超過Hadoop100倍的運算速度。但是,由於記憶體斷電後會丟失數據,Spark不能用於處理需要長期保存的數據。
Storm是Twitter主推的分散式計算系統,它由BackType團隊開發,是Apache基金會的孵化項目。它在Hadoop的基礎上提供了實時運算的特性,可以實時的處理大數據流。不同於Hadoop和Spark,Storm不進行數據的收集和存儲工作,它直接通過網路實時的接受數據並且實時的處理數據,然後直接通過網路實時的傳回結果。
Hadoop,Spark和Storm是目前最重要的三大分散式計算系統,Hadoop常用於離線的複雜的大數據分析處理,Spark常用於離線的快速的大數據處理,而Storm常用於線上的實時的大數據處理。
