
簡介
模型的名稱——“VGG”代表了牛津大學的Oxford Visual Geometry Group,該小組隸屬於1985年成立的Robotics Research Group,該Group研究範圍包括了機器學習到移動機器人。下面是一段來自網路對同年GoogLeNet和VGG的描述:
“GoogLeNet和VGG的Classification模型從原理上並沒有與傳統的CNN模型有太大不同。大家所用的Pipeline也都是:訓練時候:各種數據Augmentation(剪裁,不同大小,調亮度,飽和度,對比度,偏色),剪裁送入CNN模型,Softmax,Backprop。測試時候:儘量把測試數據又各種Augmenting(剪裁,不同大小),把測試數據各種Augmenting後在訓練的不同模型上的結果再繼續Averaging出最後的結果。”
需要注意的是,在VGGNet的6組實驗中,後面的4個網路均使用了pre-trained model A的某些層來做參數初始化。雖然提出者沒有提該方法帶來的性能增益。先來看看VGG的特點:
•小卷積核。作者將卷積核全部替換為3x3(極少用了1x1);
•小池化核。相比AlexNet的3x3的池化核,VGG全部為2x2的池化核;
•層數更深特徵圖更寬。基於前兩點外,由於卷積核專注於擴大通道數、池化專注於縮小寬和高,使得模型架構上更深更寬的同時,計算量的增加放緩;
•全連線轉卷積。網路測試階段將訓練階段的三個全連線替換為三個卷積,測試重用訓練時的參數,使得測試得到的全卷積網路因為沒有全連線的限制,因而可以接收任意寬或高為的輸入。
具體介紹
小卷積核
說到網路深度,這裡就不得不提到卷積,雖然AlexNet有使用了11x11和5x5的大卷積,但大多數還是3x3卷積,對於stride=4的11x11的大卷積核,一開始原圖的尺寸很大因而冗餘,最為原始的紋理細節的特徵變化用大卷積核儘早捕捉到,後面的更深的層數害怕會丟失掉較大局部範圍內的特徵相關性,後面轉而使用更多3x3的小卷積核(和一個5x5卷積)去捕捉細節變化。
而VGGNet則清一色使用3x3卷積。因為卷積不僅涉及到計算量,還影響到感受野。前者關係到是否方便部署到移動端、是否能滿足實時處理、是否易於訓練等,後者關係到參數更新、特徵圖的大小、特徵是否提取的足夠多、模型的複雜度和參數量等等。
計算量
在計算量這裡,為了突出小卷積核的優勢,用同樣conv3x3、conv5x5、conv7x7、conv9x9和conv11x11,在224x224x3的RGB圖上(設定pad=1,stride=4,output_channel=96)做卷積,卷積層的參數規模和得到的feature map的大小如下圖一:
 圖一
圖一從上圖一可以看出,大卷積核帶來的特徵圖和卷積核得參數量並不大,無論是單獨去看卷積核參數或者特徵圖參數,不同kernel大小下這二者加和的結構都是30萬的參數量,也就是說,無論大的卷積核還是小的,對參數量來說影響不大甚至持平。
增大的反而是卷積的計算量,在表格中列出了計算量的公式,最後要乘以2,代表乘加操作。為了儘可能證一致,這裡所有卷積核使用的stride均為4,可以看到,conv3x3、conv5x5、conv7x7、conv9x9、conv11x11的計算規模依次為:1600萬,4500萬,1.4億、2億,這種規模下的卷積,雖然參數量增長不大,但是計算量是驚人的。
總結一下,可以得出兩個結論:
•同樣stride下,不同卷積核大小的特徵圖和卷積參數差別不大;
•越大的卷積核計算量越大。
其實對比參數量,卷積核參數的量級在十萬,一般都不會超過百萬。相比全連線的參數規模是上一層的feature map和全連線的神經元個數相乘,這個計算量也就更大了。其實一個關鍵的點——多個小卷積核的堆疊比單一大卷積核帶來了精度提升,這也是最重要的一點。
感受野
說完了計算量再來說感受野。這裡給出一張VGG作者的PPT,作者在VGGNet的實驗中只用了兩種卷積核大小:1x1和3x3。作者認為兩個3x3的卷積堆疊獲得的感受野大小,相當一個5x5的卷積;而3個3x3卷積的堆疊獲取到的感受野相當於一個7x7的卷積。
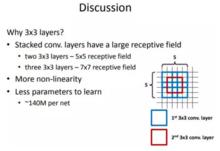 圖三
圖三見下圖三,輸入的8個元素可以視為feature map的寬或者高,當輸入為8個神經元經過三層conv3x3的卷積得到2個神經元。三個網路分別對應stride=1,pad=0的conv3x3、conv5x5和conv7x7的卷積核在3層、1層、1層時的結果。因為這三個網路的輸入都是8,也可看出2個3x3的卷積堆疊獲得的感受野大小,相當1層5x5的卷積;而3層的3x3卷積堆疊獲取到的感受野相當於一個7x7的卷積。
•input=8,3層conv3x3後,output=2,等同於1層conv7x7的結果;
•input=8,2層conv3x3後,output=2,等同於2層conv5x5的結果。
 圖三
圖三或者也可以說,三層的conv3x3的網路,最後兩個輸出中的一個神經元,可以看到的感受野相當於上一層是3,上上一層是5,上上上一層(也就是輸入)是7。
此外,倒著看網路,也就是backprop的過程,每個神經元相對於前一層甚至輸入層的感受野大小也就意味著參數更新會影響到的神經元數目。在分割問題中卷積核的大小對結果有一定的影響,在上圖三層的conv3x3中,最後一個神經元的計算是基於第一層輸入的7個神經元,換句話說,反向傳播時,該層會影響到第一層conv3x3的前7個參數。從輸出層往回forward同樣的層數下,大卷積影響(做參數更新時)到的前面的輸入神經元越多。
全連線
VGG最後三個全連線層在形式上完全平移AlexNet的最後三層,VGGNet後面三層(三個全連線層)為:
•FC4096-ReLU6-Drop0.5,FC為高斯分布初始化(std=0.005),bias常數初始化(0.1)
•FC4096-ReLU7-Drop0.5,FC為高斯分布初始化(std=0.005),bias常數初始化(0.1)
•FC1000(最後接SoftMax1000分類),FC為高斯分布初始化(std=0.005),bias常數初始化(0.1)
超參數上只有最後一層fc有變化:bias的初始值,由AlexNet的0變為0.1,該層初始化高斯分布的標準差,由AlexNet的0.01變為0.005。超參數的變化,提出者自己的感性理解指導認為,以貢獻bias來降低標準差,相當於標準差和bias間trade-off,或許提出者者實驗validate發現這個值比之前AlexNet設定的(std=0.01,bias=0)要更好。
特徵圖
網路在隨層數遞增的過程中,通過池化也逐漸忽略局部信息,特徵圖的寬度高度隨著每個池化操作縮小50%,5個池化l操作使得寬或者高度變化過程為:224->112->56->28->14->7,但是深度depth(或說是channel數),隨著5組卷積在每次增大一倍:3->64->128->256->512->512。特徵信息從一開始輸入的224x224x3被變換到7x7x512,從原本較為local的信息逐漸分攤到不同channel上,隨著每次的conv和pool操作打散到channel層級上。
特徵圖的寬高從512後開始進入全連線層,因為全連線層相比卷積層更考慮全局信息,將原本有局部信息的特徵圖(既有width,height還有channel)全部映射到4096維度。也就是說全連線層前是7x7x512維度的特徵圖,估算大概是25000,這個全連線過程要將25000映射到4096,大概是5000,換句話說全連線要將信息壓縮到原來的五分之一。VGGNet有三個全連線,我的理解是作者認為這個映射過程的學習要慢點來,太快不易於捕捉特徵映射來去之間的細微變化,讓backprop學的更慢更細一些(更逐漸)。
換句話說,維度在最後一個卷積後達到7x7x512,即大概25000,緊接著壓縮到4096維,可能是作者認為這個過程太急,又接一個fc4096作為緩衝,同時兩個fc4096後的relu又接dropout0.5去過渡這個過程,因為最後即將給1k-way softmax,所以又接了一個fc1000去降低softmax的學習壓力。
feature map維度的整體變化過程是:先將local信息壓縮,並分攤到channel層級,然後無視channel和local,通過fc這個變換再進一步壓縮為稠密的feature map,這樣對於分類器而言有好處也有壞處,好處是將local信息隱藏於/壓縮到feature map中,壞處是信息壓縮都是有損失的,相當於local信息被破壞了(分類器沒有考慮到,其實對於圖像任務而言,單張feature map上的local信息還是有用的)。
但其實不難發現,卷積只增加feature map的通道數,而池化只減少feature map的寬高。如今也有不少做法用大stride卷積去替代池化,未來可能沒有池化。
全連線轉卷積
VGG比較神奇的一個特點就是“全連線轉卷積”,下面是提出者原文test小節中的一句:
Namely, the fully-connected layers are first converted to convolutional layers (the first FC layer to a 7 × 7 conv. layer, the last two FC layers to 1 × 1 conv. layers).
也就是說,作者在測試階段把網路中原本的三個全連線層依次變為1個conv7x7,2個conv1x1,也就是三個卷積層。改變之後,整個網路由於沒有了全連線層,網路中間的feature map不會固定,所以網路對任意大小的輸入都可以處理,因而作者在緊接著的後一句說到: The resulting fully-convolutional net is then applied to the whole (uncropped) image。
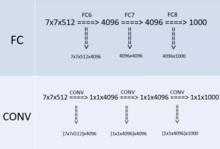 圖四
圖四圖四是VGG網路最後三層的替換過程,上半部分是訓練階段,此時最後三層都是全連線層(輸出分別是4096、4096、1000),下半部分是測試階段(輸出分別是1x1x4096、1x1x4096、1x1x1000),最後三層都是卷積層。
1x1卷積
VGG在最後的三個階段都用到了1x1卷積核,選用1x1卷積核的最直接原因是在維度上繼承全連線,然而作者首先認為1x1卷積可以增加決策函式(decision function,這裡的決策函式就是softmax)的非線性能力,非線性是由激活函式ReLU決定的,本身1x1卷積則是線性映射,即將輸入的feature map映射到同樣維度的feature map。
