
簡介
SPP-Net是出自論文《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》。
在此之前,所有的神經網路都是需要輸入固定尺寸的圖片,比如224*224(ImageNet)、32*32(LenNet)、96*96等。這樣對於我們希望檢測各種大小的圖片的時候,需要經過crop,或者warp等一系列操作,這都在一定程度上導致圖片信息的丟失和變形,限制了識別精確度。而且,從生理學角度出發,人眼看到一個圖片時,大腦會首先認為這是一個整體,而不會進行crop和warp,所以更有可能的是,我們的大腦通過蒐集一些淺層的信息,在更深層才識別出這些任意形狀的目標。
SPP-Net對這些網路中存在的缺點進行了改進,基本思想是,輸入整張圖像,提取出整張圖像的特徵圖,然後利用空間關係從整張圖像的特徵圖中,在spatial pyramid pooling layer提取各個region proposal的特徵。
 crop和warp
crop和warp一個正常的深度網路由兩部分組成,卷積部分和全連線部分,要求輸入圖像需要固定size的原因並不是卷積部分而是全連線部分。所以SPP層就作用在最後一層卷積之後,SPP層的輸出就是固定大小。
SPP-net不僅允許測試的時候輸入不同大小的圖片,訓練的時候也允許輸入不同大小的圖片,通過不同尺度的圖片同時可以防止overfit。
相比於R-CNN提取2000個proposal,SPP-net只需要將整個圖扔進去獲取特徵,這樣操作速度提升了100倍左右。
SPP Layer介紹
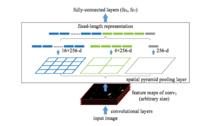 圖二
圖二卷積層的參數和輸入大小無關,它僅僅是一個卷積核在圖像上滑動,不管輸入圖像多大都沒關係,只是對不同大小的圖片卷積出不同大小的特徵圖,但是全連線層的參數就和輸入圖像大小有關,因為它要把輸入的所有像素點連線起來,需要指定輸入層神經元個數和輸出層神經元個數,所以需要規定輸入的feature的大小。因此,固定長度的約束僅限於全連線層。 SPP-Net在最後一個卷積層後,接入了金字塔池化層,使用這種方式,可以讓網路輸入任意的圖片,而且還會生成固定大小的輸出。
從整體過程來看,就是如圖二所示。黑色圖片代表卷積之後的特徵圖,接著我們以不同大小的塊來提取特徵,分別是4*4,2*2,1*1,將這三張格線放到下面這張特徵圖上,就可以得到16+4+1=21種不同的塊(Spatial bins),我們從這21個塊中,每個塊提取出一個特徵,這樣剛好就是我們要提取的21維特徵向量。這種以不同的大小格子的組合方式來池化的過程就是空間金字塔池化(SPP)。比如,要進行空間金字塔最大池化,其實就是從這21個圖片塊中,分別計算每個塊的最大值,從而得到一個輸出單元,最終得到一個21維特徵的輸出。所以Conv5計算出的feature map也是任意大小的,經過SPP之後,就可以變成固定大小的輸出了,以上圖為例,一共可以輸出(16+4+1)*256的特徵。
總結而言,當網路輸入的是一張任意大小的圖片,這個時候我們可以一直進行卷積、池化,直到網路的倒數幾層的時候,也就是我們即將與全連線層連線的時候,就要使用金字塔池化,使得任意大小的特徵圖都能夠轉換成固定大小的特徵向量,這就是空間金字塔池化的意義(多尺度特徵提取出固定大小的特徵向量)。
訓練過程
作者提出兩種訓練方式:一種是single-size,一種是Multi-size。
single-size
理論上說,SPP-net支持直接以多尺度的原始圖片作為輸入後直接BP即可。實際上,caffe等實現中,為了計算的方便,GPU,CUDA等比較適合固定尺寸的輸入,所以訓練的時候輸入是固定了尺度了的。以224*224的輸入為例:在conv5之後的特徵圖為:13x13(a*a),金字塔層bins:n*n,將pooling層作為slidingwindow pooling。
windows_size=[a/n]向上取整 ,stride_size=[a/n]向下取整。
Multi-size training
使用兩個尺度進行訓練:224*224 和180*180。訓練的時候,224x224的圖片通過crop得到,180x180的圖片通過縮放224x224的圖片得到。之後,疊代訓練,即用224的圖片訓練一個epoch,之後180的圖片訓練一個epoch,交替地進行。
兩種尺度下,在SSP後,輸出的特徵維度都是(9+4+1)x256,參數是共享的,之後接全連線層即可。
SPP層代碼分析
代碼中存放的是spp layer中的目標輸出大小,代碼中bins=[1,2,3],經過處理之後就可以得到對應的(1*1+2*2+3*3)*256=14*256=3584個神經元,即無論前面的feature map是多大的,經過spp layer處理之後得到固定大小的神經元,然後就可以和全連線層進行矩陣運算了。
測試階段
作者將SPP-Net測試效果與R-CNN對比。
對於R-CNN,整個過程是:
首先通過選擇性搜尋,對待檢測的圖片進行搜尋出~2000個候選視窗。
把這2k個候選視窗的圖片都縮放到227*227,然後分別輸入CNN中,每個proposal提取出一個特徵向量,也就是說利用CNN對每個proposal進行提取特徵向量。
把上面每個候選視窗的對應特徵向量,利用SVM算法進行分類識別。
1.首先通過選擇性搜尋,對待檢測的圖片進行搜尋出~2000個候選視窗。
2.把這2k個候選視窗的圖片都縮放到227*227,然後分別輸入CNN中,每個proposal提取出一個特徵向量,也就是說利用CNN對每個proposal進行提取特徵向量。
3.把上面每個候選視窗的對應特徵向量,利用SVM算法進行分類識別。
可以看出R-CNN的計算量是非常大的,因為2k個候選視窗都要輸入到CNN中,分別進行特徵提取。
而對於SPP-Net,整個過程是:
首先通過選擇性搜尋,對待檢測的圖片進行搜尋出2000個候選視窗。這一步和R-CNN一樣。
特徵提取階段。這一步就是和R-CNN最大的區別了,這一步驟的具體操作如下:把整張待檢測的圖片,輸入CNN中,進行一次性特徵提取,得到feature maps,然後在feature maps中找到各個候選框的區域,再對各個候選框採用金字塔空間池化,提取出固定長度的特徵向量。而R-CNN輸入的是每個候選框,然後在進入CNN,因為SPP-Net只需要一次對整張圖片進行特徵提取,速度會大大提升。
最後一步也是和R-CNN一樣,採用SVM算法進行特徵向量分類識別。
1.首先通過選擇性搜尋,對待檢測的圖片進行搜尋出2000個候選視窗。這一步和R-CNN一樣。
2.特徵提取階段。這一步就是和R-CNN最大的區別了,這一步驟的具體操作如下:把整張待檢測的圖片,輸入CNN中,進行一次性特徵提取,得到feature maps,然後在feature maps中找到各個候選框的區域,再對各個候選框採用金字塔空間池化,提取出固定長度的特徵向量。而R-CNN輸入的是每個候選框,然後在進入CNN,因為SPP-Net只需要一次對整張圖片進行特徵提取,速度會大大提升。
3.最後一步也是和R-CNN一樣,採用SVM算法進行特徵向量分類識別。
檢測算法
 SPP-Net
SPP-Net對於檢測算法,論文中是這樣做到:使用ss生成~2k個候選框,縮放圖像之後提取特徵,每個候選框使用一個4層的空間金字塔池化特徵,網路使用的是ZF-5的SPPNet形式。之後將12800d的特徵輸入全連線層,SVM的輸入為全連線層的輸出。
這個算法可以套用到多尺度的特徵提取:先將圖片resize到五個尺度:480,576,688,864,1200,加自己6個。然後在map window to feature map一步中,選擇ROI框尺度在{6個尺度}中大小最接近224x224的那個尺度下的feature maps中提取對應的roi feature。這樣做可以提高系統的準確率。
