GTX690

該GPU由n企在2012年4月29日推出。在GeForce GTX 690採用2顆完整的代號為GK104的顯示核心(GK104-355-A2),核心時鐘頻率915MHz,4GB容量的512位位寬GDDR5顯示存儲器,外接雙8Pin輔助供電。GTX690的優越性能獲得了ZOL好評。其獨有的BOOST技術使得其可以為4路SLI。
基本信息
- 中文名:GTX690顯示卡
- 英文名:Geforce GTX 690
- 名稱:GTX690
- 英文名:Geforce GTX 690
- 其他外文名:戰術核顯示卡
- 別稱:GTX690顯示卡
- 用途:發燒級
- 生產商:NVIDIA
- 發布日期:2012年4月29日
- 核心構架:GK104-355-A2
相關事件
在上海英偉達遊戲群英匯現場一位戴眼鏡的現場觀眾獲得了世界第一塊由影馳公司出品的公版GTX690,該現場觀眾是影馳7級會員。英偉達CEO黃仁勛先生親自為該現場觀眾簽名顯示卡,觀眾們激動萬分。規格參數
附註:以下規格為該 GPU 納入 NVIDIA 參考繪圖卡設計中的規格。繪圖卡規格可能會因為附加卡製造商而有所不同。請參考附加卡製造商的網站,以取得實際出貨規格資訊。GPU引擎規格爆炸單元數量:3072基礎頻率(MHz):915提升頻率(MHz):1019紋理填充速率(billion/sec):234顯存規格顯存頻率 (Gbps):6.0GDDR5標準顯存組態:4096 MB (2048 MB per GPU)顯存介面寬度:512-bit (256-bit per GPU)顯存位寬(GB/sec):384特性支持OpenGL:4.2匯流排支持:PCI Express 3.0Windows 7 認證:支持支持的技術:3D Vision, 3D Vision Surround, CUDA, DirectX 11, PhysX, SLI, TXAA, Adaptive VSync, GPU Boost, FXAASLI選項:Quad顯示器支持Multi Monitor:4 displays最大數字解析度:4096x2160最大VGA解析度:2048x1536高位寬數字內容保護(HDCP):支持(轉接器)高清多媒體介面(HDMI):支持Standard Display Connectors:兩個雙鏈路 DVI-I,一個雙鏈路 DVI-D ,一個Mini-Displayport 1.2針對HDMI的音訊輸出:內部標準繪圖卡尺寸長度:11.0 英寸 高度:4.376 英寸寬度:雙槽散熱和功率規格GPU最高溫度(攝氏):98 C供電接口:兩個 8 針連線器(3D Vision) Ready:3D 立體幻境3D藍光:支持3D 遊戲:支持3D Vision Live (照片與視頻):支持散熱方式:水冷或風冷
高度:4.376 英寸寬度:雙槽散熱和功率規格GPU最高溫度(攝氏):98 C供電接口:兩個 8 針連線器(3D Vision) Ready:3D 立體幻境3D藍光:支持3D 遊戲:支持3D Vision Live (照片與視頻):支持散熱方式:水冷或風冷價格
Nvida承諾GTX 690將開始小範圍供應,之後將由各核心合作夥伴將開始進行更廣泛的銷售,該產品售價為999美元。在市場方面,GTX690將會把AMD給甩下一大截。據說,兩塊GTX680雙SLI的效果就和GTX690一樣。由此可見,這塊顯示卡的性能比現在AMD最好的顯示卡——HD7970超越了許多。詳細信息
架構
流處理器暴增之謎基於效能和計算能力方面的考慮,NVIDIA與AMD不約而同的改變了架構,NVIDIA雖然還是採用SIMT架構, 但也借鑑了AMD“較老”的SIMD架構之作法,降低控制邏輯單元和指令發射器的比例,用較少的邏輯單元去控制更多的CUDA核心。於是一組SM當中容納了192個核心的壯舉就變成了現實!通過右面這個示意圖就看的很清楚了,CUDA核心的縮小主要歸功於28nm工藝的使用,而如此之多的CUDA核心,與之搭配的控制邏輯單元面積反而縮小了,NVIDIA強化運算單元削減控制單元的意圖就很明顯了。此時相信有人會問,降低控制單元的比例那是不是意味著NVIDIA賴以成名的高效率架構將會一去不復返了?理論上來說效率肯定會有損失,但實際上並沒有想像中的那么嚴重。NVIDIA發現執行緒的調度有一定的規律性,編譯器所發出的條件指令可以被預測到,此前這部分工作是由專門的硬體單元來完成的,如今可以用簡單的程式來取代,這樣就能節約不少的電晶體。所以在克卜勒中NVIDIA將一大部分指令派發和控制的操作交給了軟體(驅動)來處理。而且GPU的架構並沒有本質上的改變,只是結構和規模以及控制方式發生了變化,只要驅動支持到位,與遊戲開發商保持緊密的合作,效率損失必然會降到最低——事實上NVIDIA著名的The Way策略就是幹這一行的!這方面NVIDIA與AMD的思路和目的是相同的,但最終體現在架構上還是有所區別。NVIDIA的架構被稱為SIMT(Single Instruction Multiple Threads,單指令多執行緒),NVIDIA並不像AMD那樣把多少個運算單元捆綁為一組,而是以執行緒為單位自由分配,控制邏輯單元會根據執行緒的任務量和SM內部CUDA運算單元的負載來決定調動多少個CUDA核心進行計算,這一過程完全是動態的。但不可忽視的是,軟體預解碼雖然大大節約了GPU的電晶體開銷,讓流處理器數量和運算能力大增,但對驅動和遊戲最佳化提出了更高的要求,這種情況伴隨著AMD度過了好多年,NVIDIA也要面對相同的問題了,希望他能做得更好一些,否則散熱量還將繼續增加。
但也借鑑了AMD“較老”的SIMD架構之作法,降低控制邏輯單元和指令發射器的比例,用較少的邏輯單元去控制更多的CUDA核心。於是一組SM當中容納了192個核心的壯舉就變成了現實!通過右面這個示意圖就看的很清楚了,CUDA核心的縮小主要歸功於28nm工藝的使用,而如此之多的CUDA核心,與之搭配的控制邏輯單元面積反而縮小了,NVIDIA強化運算單元削減控制單元的意圖就很明顯了。此時相信有人會問,降低控制單元的比例那是不是意味著NVIDIA賴以成名的高效率架構將會一去不復返了?理論上來說效率肯定會有損失,但實際上並沒有想像中的那么嚴重。NVIDIA發現執行緒的調度有一定的規律性,編譯器所發出的條件指令可以被預測到,此前這部分工作是由專門的硬體單元來完成的,如今可以用簡單的程式來取代,這樣就能節約不少的電晶體。所以在克卜勒中NVIDIA將一大部分指令派發和控制的操作交給了軟體(驅動)來處理。而且GPU的架構並沒有本質上的改變,只是結構和規模以及控制方式發生了變化,只要驅動支持到位,與遊戲開發商保持緊密的合作,效率損失必然會降到最低——事實上NVIDIA著名的The Way策略就是幹這一行的!這方面NVIDIA與AMD的思路和目的是相同的,但最終體現在架構上還是有所區別。NVIDIA的架構被稱為SIMT(Single Instruction Multiple Threads,單指令多執行緒),NVIDIA並不像AMD那樣把多少個運算單元捆綁為一組,而是以執行緒為單位自由分配,控制邏輯單元會根據執行緒的任務量和SM內部CUDA運算單元的負載來決定調動多少個CUDA核心進行計算,這一過程完全是動態的。但不可忽視的是,軟體預解碼雖然大大節約了GPU的電晶體開銷,讓流處理器數量和運算能力大增,但對驅動和遊戲最佳化提出了更高的要求,這種情況伴隨著AMD度過了好多年,NVIDIA也要面對相同的問題了,希望他能做得更好一些,否則散熱量還將繼續增加。核心
SMX與SM的改動細節全新的Kepler相比上代的Fermi架構改變了什麼,看架構圖就很清楚了: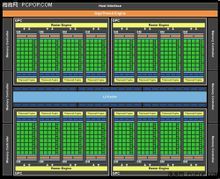 GK104相比GF110,整體架構沒有大的改變,GPU(圖形處理器集群)維持4個,顯存控制器從6個64bit(384bit)減至4個64bit(256bit),匯流排接口升級至PCIE 3.0。剩下的就是SM方面的改變了NVIDIA把GK104的SM(不可分割的流處理器集群)稱為SMX,原因就是暴增的CUDA核心數量。但實際上其結構與上代的SM沒有本質區別,不同的只是各部分單元的數量和比例而已。具體的區別逐個列出來進行對比:
GK104相比GF110,整體架構沒有大的改變,GPU(圖形處理器集群)維持4個,顯存控制器從6個64bit(384bit)減至4個64bit(256bit),匯流排接口升級至PCIE 3.0。剩下的就是SM方面的改變了NVIDIA把GK104的SM(不可分割的流處理器集群)稱為SMX,原因就是暴增的CUDA核心數量。但實際上其結構與上代的SM沒有本質區別,不同的只是各部分單元的數量和比例而已。具體的區別逐個列出來進行對比: | Kepler與Fermi架構SM參數對比 |
| 單元 | GF100 | GF104 | GK104 | GK104/GF104 |
| CUDA | 32 | 48 | 192 | 4:1 |
| SFU | 4 | 8 | 32 | 4:1 |
| Warp | 2 | 2 | 4 | 2:1 |
| Dispatch | 2 | 4 | 8 | 2:1 |
| LD/ST | 16 | 16 | 32 | 2:1 |
| TMU | 4 | 8 | 32 | 4:1 |
