
簡介
長短期記憶人工神經網路(Long-Short Term Memory, LSTM)論文首次發表於1997年。由於獨特的設計結構,LSTM適合於處理和預測時間序列中間隔和延遲非常長的重要事件。
LSTM的表現通常比時間遞歸神經網路及隱馬爾科夫模型(HMM)更好,比如用在不分段連續手寫識別上。2009年,用LSTM構建的人工神經網路模型贏得過ICDAR手寫識別比賽冠軍。LSTM還普遍用於自主語音識別,2013年運用TIMIT自然演講資料庫達成17.7%錯誤率的紀錄。作為非線性模型,LSTM可作為複雜的非線性單元用於構造更大型深度神經網路。
結構
LSTM是一種含有LSTM區塊(blocks)或其他的一種類神經網路,文獻或其他資料中LSTM區塊可能被描述成智慧型網路單元,因為它可以記憶不定時間長度的數值,區塊中有一個gate能夠決定input是否重要到能被記住及能不能被輸出output。
右圖底下是四個S函式單元,最左邊函式依情況可能成為區塊的input,右邊三個會經過gate決定input是否能傳入區塊,左邊第二個為input gate,如果這裡產出近似於零,將把這裡的值擋住,不會進到下一層。左邊第三個是forget gate,當這產生值近似於零,將把區塊里記住的值忘掉。第四個也就是最右邊的input為output gate,他可以決定在區塊記憶中的input是否能輸出 。
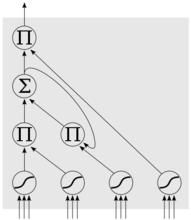 LSTM模型
LSTM模型LSTM有很多個版本,其中一個重要的版本是GRU(Gated Recurrent Unit),根據谷歌的測試表明,LSTM中最重要的是Forget gate,其次是Input gate,最次是Output gate。
訓練方法
為了最小化訓練誤差,梯度下降法(Gradient descent)如:套用時序性倒傳遞算法,可用來依據錯誤修改每次的權重。梯度下降法在遞迴神經網路(RNN)中主要的問題初次在1991年發現,就是誤差梯度隨著事件間的時間長度成指數般的消失。當設定了LSTM 區塊時,誤差也隨著倒回計算,從output影響回input階段的每一個gate,直到這個數值被過濾掉。因此正常的倒傳遞類神經是一個有效訓練LSTM區塊記住長時間數值的方法。
搭建實例
以下代碼展示了在tensorflow中實現使用LSTM結構的循環神經網路的前向傳播過程。
LSTM網路的變體:雙向循環神經網路和深層循環神經網路
雙向循環神經網路的主體結構是由兩個單向循環神經網路組成的。在每一個時刻t,輸入會同時提供給這兩個方向相反的循環神經網路,而輸出則是由這兩個單向循環神經網路共同決定。其結構如下圖一所示:
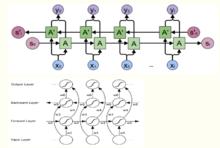 圖一
圖一六個權值分別對應:輸入到向前和向後隱含層(w1, w3),隱含層到隱含層自己(w2, w5),向前和向後隱含層到輸出層(w4, w6)。值得注意的是:向前和向後隱含層之間沒有信息流,這保證了展開圖是非循環的。
深層循環神經網路:為了增強模型的表達能力,該網路在每一個時刻上將循環體結構複製多次,每一層的循環體中參數是一致的,而不同層中的參數可以不同。其結構如下圖二所示:
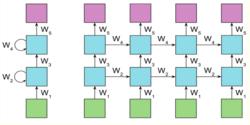 圖二
圖二tensorflow中提供了MultiRNNCell類來實現深層循環神經網路的前向傳播過程。代碼如下:
