技術組成
使電腦具有“說話”的功能,這在真正的“面對面人機交流”中扮演著很重要的角色。藉助於語音合成系統,計算機已經可以清晰、自然地說話,普通用戶很容易聽懂並接受。然而,現有能說話的計算機往往只能按照一個模式說話。而終端用戶卻往往對這種能說話的計算機有更高的需求,比如,用戶可能希望計算機能夠以用戶的聲音進行朗讀。這種情況下,如何滿足用戶的期望使計算機可以按照多種不同風格、不同個性來說話呢?這就要藉助於個性化語音生成技術。
個性化語音生成技術是人機互動中的重要組成部分,有關這方面的研究已經引起了國內外很多研究組的關注。除人機互動外,個性化語音生成技術在其他很多領域也有著相當廣泛的套用: 比如在網路聊天中隱藏自己的真實身份,甚至可以套用到間諜領域,用來模擬敵方成員的聲音。
語音中的信息主要來自於兩個方面: 聲源信息和聲道信息。聲源信息來自於聲帶的震動,主要體現在音高的高低變化,也就是人們平常所說的“抑揚頓挫”,通常用基頻值來衡量。另一方面,聲道信息來自於人體聲道的形狀,聲道承載的信息包括說話的內容以及說話人的特徵,在聲學上表現為不同的頻譜分布。研究人員為了使合成系統可以模擬各種說話人的特色,最初將重點放在聲道信息的模擬轉換上,基於此用戶需求就產生了許多針對語音轉換(Voice Conversion)技術的研究。
語音轉換技術是對語音合成技術的豐富和延拓,通過改變頻譜特徵使一個說話人說出的聲音聽起來像是由另外一個人發出一樣。看過“名偵探柯南”的讀者都知道柯南經常用模仿別人聲音的變聲器,這正是語音轉換技術的一個重要套用。近年來,隨著技術的進步和研究人員認識的深入,聲源信息的模擬也引起了很多研究人員的重視。要想模仿一個人的聲音,除了模仿他的音色特徵之外,還要模擬他說話的方式,模仿他抑揚頓挫的風格,這項研究通常被稱為韻律轉換(prosody Conversion)。通過一系列技術措施,使得只要通過錄製目標說話人少量的句子,就可以使計算機學習到該說話人的頻譜特徵和韻律特徵,進而可以使機器所發出的聲音具有該說話人的特色。
除此之外,語音變換也是另外一個重要的研究領域。語音變換的任務並不是將源說話人聲音變為另外一個特定人的聲音,而只是對其進行某種變換使之產生某種特效,比如說通過對基頻的變換使原先的男聲聽起來像女聲或者使原先的女聲聽起來像男聲,或者通過對頻譜進行變換使原先的人聲變得像機器人的聲音。語音變換在數字娛樂領域有著很廣泛的套用。而另一個領域——個性化自適應的研究又有所不同,語音轉換中的輸入是源說話人,系統通過某種變換使之聽起來像是目標說話人的聲音,而個性化自適應系統的輸入是文本,系統通過某種變換使合成系統發出的聲音像是目標說話人的聲音。可見,個性化自適應可以看作是語音轉換技術同語音合成技術的一個聯合擴展,其套用更為廣泛。
有關個性化語音生成技術的研究已經是整個語音語言研究中非常重要的組成部分,國內外均有一些這方面的前期研究成果,但限於計算複雜度、存儲量及計算實時性等多方面原因,早期工作大部分還停留在實驗室階段。近幾年來,隨著許多研究機構對此項研究的重視,研究越來越深入,在一些實際套用場合已經開始逐步獲得了套用。
本文通過對中科院自動化所在語音轉換等技術方面的介紹,系統性闡述語音轉換和韻律轉換、語音變換、個性化語音生成等方面的原理和實現過程。通過本文的介紹,讀者可以詳細了解個性化語音生成研究的整個流程步驟。
語音轉換(voice Conversion)和韻律轉換(Prosody Conversion)
語音轉換
語音轉換主要是指聲道信息的轉換,也即是頻譜信息的轉換。其目標是確定一個模式轉換規則,使轉換後的語音保持源說話人原有語音信息內容不變,而具有目標說話人的聲音特點。為了找到這個轉換規則,我們需要首先錄製源說話人和目標說話人的一組平行語料庫。所謂平行語料是指兩個說話人所錄的內容完全相同,比如說分別錄製源說話人和目標說話人說“今天天氣很好”這句話。這樣的錄製方式便於找到兩個說話人頻譜特徵的對應關係。整個過程可以分為訓練和轉換兩個步驟來進行,圖1展示了語音轉換過程的功能和框架圖。在訓練階段,系統對源說話人和目標說話人的語音樣本進行訓練,得到映射規則,獲取源語音和目標語音頻譜參數之間的關係。在轉換階段,利用上一步得到的映射規則對源語音的頻譜特徵進行變換,使變換後的語音具有目標說話人的特徵。可見,語音轉換技術中最關鍵的部分就是映射規則的確定。
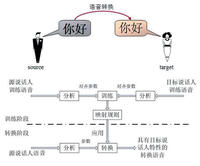
中科院自動化所經過多年的研究,提出了一種使用碼本映射和高斯混合模型共同轉換聲學特徵細節的混合映射算法。碼本映射和高斯混合模型分別是語音轉換研究領域兩種主流的做法,各有其優缺點。碼本映射的方法可以這樣理解: 將源語音和目標語音分別分為很多個段落,這些段落即可稱之為碼本。進行語音轉換時,將源語音的段落直接替換為目標語音中的相應段落,這樣轉換後的語音就完全由目標語音中的段落組成,因此也必然具有目標說話人的特徵。為了更清晰地闡述這個概念,我們假設段落的基本單元是音節,現在源說話人說了一句: “今天天氣不錯”,轉換過程中只要分別找到目標說話人語料庫中以上六個音節的合適語音段,再將其連起來即可。當然,真正的碼本映射算法並沒有像上面描述的這么簡單,當存在多個候選段落時,如何選取最合適的段落是最關鍵的問題,同時還要考慮拼接後語音是否連續,並且在真正的套用中段落的基本單位常常是一段固定長度的語音段(通常稱其為禎)。儘管有以上不同,但其基本思想是一樣的。基於碼本映射的方法簡單有效,時至今日仍然是非常流行的方法。
與碼本映射的方法相比,基於高斯混合模型(Gaussian Mixture Model, GMM)的方法則有所不同,它不是通過直接替換語音段落來使轉換後的聲音具有目標說話人聲音的,相反,它是假設存在一個函式y=f(x),可以將源說話人的聲學特徵x變為具有目標說話人聲學特徵的y。根據錄製的平行語料庫可以估計得到函式f的參數和形式,轉換過程中只要對源說話人語音套用該函式即可。
前面已經提到,上述兩個方法各有優缺點,碼本映射的方法直接使用目標說話人的語音段,轉換後的語音在聽感上基本等同於目標說話人,但在相鄰語音段之間可能會引入不連續現象; 而基於高斯混合模型的方法,在估計f(x)過程中可能忽視了很多細節信息,導致轉換後的語音具有過平滑現象。我們詳細研究了兩種方法的優缺點及其產生原因,在所提出的這種混合映射算法中,將兩種方法的優缺點進行互補,使用碼本映射方法構建細節特徵來補償高斯混合模型產生的過平滑現象,實驗證明,該方法有效地克服了過平滑現象,並且同時還提高了頻譜轉換的精確度。
韻律轉換(Prosody Conversion)
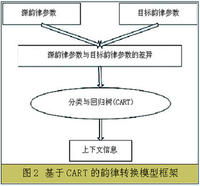
現在的個性化語音生成工作主要集中在頻譜轉換上,對韻律轉換的研究較少,轉換中通常忽略基頻信息或是僅作簡單變換。事實上,韻律信息是非常重要的聲音特徵,不同人有各自不同的韻律風格。韻律特徵中包括言語中除了音色外的其餘三個特徵——音高、音強和音長。在漢語中,則具體體現在重音、時長、語調和停頓等幾個方面。韻律特徵尤其是基頻曲線含有大量的說話人身份信息,對確定說話人身份起了很重要的作用。要想真正達到使合成的聲音具有目標說話人的特性,必須對韻律信息也進行合適的轉換。韻律轉換的目的就是利用某種映射關係把源說話人的基頻曲線轉換為目標說話人的基頻曲線。最基本的求解映射關係的做法是保持基頻曲線的基本形狀不變,只是調整源說話人的基頻值的範圍使之更接近目標說話人。然而目前,隨著統計學習和機器學習技術的發展,許多基於統計和機器學習的算法可供基頻轉換研究使用,鑒於此,中科院自動化所提出了一種使用分類與回歸樹(Classification and Regression Tree,CART)來進行韻律轉換的方法,CART是一種常用的決策樹,是模式識別研究領域中進行分類和回歸的一種十分有效的方法。使用CART主要有兩個步驟: 訓練和決策。
訓練的過程就是生成一棵二叉樹的過程,根結點包含所有的待分類樣本,其中樣本的目標值為源韻律參數與目標韻律參數的差異,預測屬性為各種上下文信息,比如說聲調類型、音節類型等。通過對樣本屬性問題的提問,不斷分裂節點,最終形成若干葉子節點,每一葉子節點代表一類。分裂的準則是使得節點內樣本的平均距離最小,當某一葉子節點的樣本總數小於預先設定的閾值時停止分裂,如何設計提問屬性是一個關鍵的問題,參與提問的屬性應該是文本信息中對基頻曲線的變化有較大影響的那些上下文環境信息。決策的過程就是模型的套用,即根據目標樣本的屬性,從根結點開始找到對應的葉子節點。基於決策樹的韻律轉換模型如圖2所示
語音變換完成的功能同語音轉換是不一樣的,語音轉換是特定的源說話人聲音向特定的目標說話人聲音的轉換,轉換過程有著明確的目標; 而語音變換則不一樣,語音變換中一般沒有明確的目標,大部分情況下,都是對源語音施加一種產生某種趨向的變換,使之具有某種特徵或者表達某種特效。
中科院自動化所在語音變換領域也投入了很多研發力量,研製了一個線上實時的語音變換系統,可以實時的將一個人的語音進行多種特色的變換,如: 男聲變女聲、女聲變男聲、變成機器人聲音、變成帶有哮喘的聲音等。該系統還有一個特色,就是還可以融入韻律特徵的變換,讓一個人在語音發生變換時,語氣特徵也發生變換,聽起來就像不同的方言口音。所有運算完全實時進行,用戶使用麥克風采集數據,在音頻輸出上可以當即得到變換後的語音。這些特殊的功能在網路實時聊天中有很大的套用前景。
個性化自適應
為了進一步提高所生成個性化語音的表現力並拓展個性化語音生成的套用領域,中科院自動化所提出了個性化自適應的框架。上面所介紹的頻譜轉換和韻律轉換是個性化自適應研究的基礎,但是個性化自適應的研究與二者有著本質的不同: 在一般的頻譜轉換和韻律轉換中採用的都是平行訓練語料庫,即源語料和目標語料的大小和文本是完全一致的,這有利於建立準確的對應關係; 而在個性化自適應中,源訓練語料採用的是可用於合成系統的大語料庫,該語料庫通常有幾千句,甚至有可能是多人的。目標訓練語料庫則比較小,一般只有幾百句甚至只有幾十句,可能是源語料庫的一個小的子集。個性化自適應與語音轉換的目的都是使合成語音與目標說話人的聲音相似,但是二者的輸入是不同的,在韻律轉換中輸入的是源說話人的聲音,而在韻律自適應中輸入的是純文本,由合成系統根據文本來預測發音和韻律結構等基本信息。總之,個性化自適應的目的是在已有合成系統和大語料庫的基礎上由合成系統輸出與目標說話人相似的合成語音。相比一般的頻譜轉換和韻律轉換而言,個性化自適應中可利用的信息更多,因此也就可以得到更好的結果並具有更廣泛的套用領域。圖3清楚地顯示了語音轉換和個性化自適應的不同。需要指出的是,儘管二者的工作存在著顯著的差異,但是許多套用於語音轉換的方法和思想仍然可以用於個性化自適應工作。
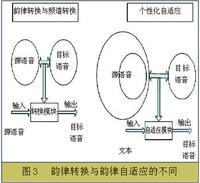
為了達到個性化自適應的目的,通常大的源語料庫不止一個。個性化自適應方法的基本思想是: 在N個大型源語料庫中找到一個與目標語料庫風格最相似的語料庫,由這兩組語料庫中的平行部分建立對應關係,然後套用前面所介紹的頻譜轉換和韻律轉換的方法,建立源語料庫與目標語料庫的映射關係。而後,合成系統即可以合成具有目標說話人特色的聲音。
連結一:語音合成技術
語音合成技術(Text-to-Speech,簡稱TTS)是一種將任意文本轉換成語音輸出的技術,在通信、遊戲娛樂等領域中有著廣闊的套用前景。近十年來,隨著各種信號處理技術、模式識別技術的飛速發展,語音合成技術也取得了相當大的進步,其合成的語音清晰、自然,用戶很容易即可聽懂。目前的合成語音雖然少了許多“機器味”,但是依然比較單調無趣,一個合成系統通常只能以一種特定的風格進行朗讀,這就導致合成語音在日常生活中難以廣泛套用。目前TTS系統最大的不足就是它僅僅能夠產生幾個特定人的發音,而用戶則期望它具有模擬發出自己或者某些特定人聲音的能力。
連結二:個性化語音生成的總體框架
個性化語音生成研究的總體框架主要包括三組內容: 傳統意義上的韻律轉換和頻譜轉換、語音變換、個性化自適應研究。傳統意義上的韻律轉換和頻譜轉換的目的是對源說話人聲音施加某種變換,保持源說話人的內容不變,並且使得轉變後的聲音具有目標說話人的特徵。其中頻譜轉換保證轉換後的聲音具有目標說話人的音色特徵,而韻律轉換保證轉換後的聲音具有目標說話人的韻律特徵。語音變換則是對源聲音施加一種代表某種趨向的變換,使得轉換後的聲音具有某種特殊效果,如性別的改變、人聲到機器聲的改變等。個性化自適應研究是語音轉換技術同語音合成技術的一個結合點。同時,在個性化自適應研究中,通過合成系統能夠得到發音、韻律結構等文本信息,而在轉換中,往往只能得到有限的韻律特徵和聲學特徵信息。由此可以看出,個性化自適應系統比傳統意義的韻律轉換和頻譜轉換系統可以利用更廣泛的信息,所達到的轉換效果也必然更加真實,具有更廣泛的套用價值。
