
簡介
定義
漢語是一種有調語言,其聲調具有辨意的作用。聲調是重要的聲學參數,在語音識別、語音合成和分析處理套用中,都有重要的意義。聲調是由調值和調型組成的,調值由基頻數值決定,調型由調值的走向決定。 基頻是語言信號的一個重要參數。在聲碼器和各種語言信號處理系統中一般都具有提取基頻的基本部件。
語言基頻識別就是將語音信號的基頻提取出來,以彩色動態圖形的方式顯示其大小和變化形狀。
目前普遍地對在噪聲的背底中增強語言信號感興趣,也提出了一些減低噪聲增強語言信號的方法,例如頻譜相減方法、基頻跟蹤方法、自相關方法、線性濾波方法、自適應濾波方法等等。它們對減小噪聲提高信噪比都有一定的效果。然而其中的一些方法,如自相關、基頻跟蹤以及一種自適應濾波等都需要先測得基頻參數。
研究背景
在現有的漢語語音識別系統中,聲調信息並未得到充分利用,隨著漢語語音識別技術的進一步發展,聲調研究成為識別技術突破的重要方向;在語音合成研究中,目前合成自然度不高的一個重要因素是韻律規則的不完善,而漢語韻律規律的核心問題就是聲調規律。因此為了能在語音識別和合成中充分、有效的利用聲調信息,必須對連續語音中漢語聲調的特點進行深入的研究,並從聲調特徵的提取、聲調的建模、連續語音中聲調變化規律的獲取以及連續語音中聲調的識別這四個方面對連續語音中的漢語聲調進行深入研究。而基頻曲線是漢語聲調的最本質特徵,因而基頻的提取是聲調研究的基礎。
常用基頻提取算法
目前,常用的基頻提取的算法大致有四種:自相關算法、平行處理法、倒譜法和簡化逆濾波法。
自相關算法
自相關算法是利用語音信號在發濁音時的周期性來檢驗音調的周期的算法。對於確定性信號,自相關函式定義為:
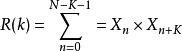 語言基頻識別
語言基頻識別式中X是用採樣頻率f,對連續信號X(t)進行採樣後得到的離散信號,而在對語言信號作自相關處理時.總是將語言信號X,分成若干幀,式中的N是幀的長度,K=0,1,2,...2/3N
如果信號序列是周期性的,其自相關函式也是同周期性的。並且自相關函式是偶函式,R(0)具有最大值。為了避免音調周期性和共振峰周期性混在一起,需要對語音信號進行預處理,從而去掉聲道回響的影響。常用的預處理方法是“中心削波”技術.自相關算法的關鍵在於確定中心削波電平和自相關數據的點數。
中心削波電平與語音信號和環境噪音電平有關,一般取語音段最大幅度的一個固定百分數值,低於削波電平的信號輸出為零。自相關數據的點數至少要大於音調周期的兩倍,同時要儘可能地小以保證語音信號的短時性。
平行處理法
平行處理法是一種比較成功的音調檢測的時域方法.語調信號通過略去與音調檢測無關的信息而保留住信號的周期性的預處理後形成一系列脈衝,由平行的一些簡單的檢測器估計音調周期,在後處理器部分對這幾個估值作邏輯組合,輸出估計的正確周期。
倒譜法
倒譜法,是一種有效的頻域方法,特別是對於無噪語音.倒譜法是基於聲道的激勵一調製模型,信號的倒譜是其功率的對數的傅立葉變換。
簡化逆濾波法
簡化逆濾波法,先降低語音信號採樣率,抽取其模型參數,用這些參數對原信號進行逆濾波得出音源序列,最後求出該序列的峰值位置,從而求得音調周期。
簡化基頻提取算法
算法要求在低成本的硬體設備上,保證系統的實時性和準確性。因此,算法必須簡單,而且要滿足能夠提取從普通成年男子的低頻90Hz到兒童的高頻450Hz的基頗。因為元音是漢語音調信息的主要攜帶者,元音主要分部在低頻部分。所以只需採用4kHz的採樣率。雖然平行處理法是一種不錯的音調檢測的時域方法,算法比較簡單,但是,它同簡化逆濾波算法一樣都涉及到增加硬設備的問題,實現起來有特殊的要求,增加了成本。倒譜法在採用無噪語音時,性能很好,而存在加性噪聲時其性能就會急劇惡化,並且該算法要經過傅立葉變換,運算量大,比較複雜,對於實時系統的實現有一定的困難。所以選用了一種簡化的自相關算法。
自相關算法的關鍵在於確定中心削波電平和自相關數據的點數.中心削波電平與語音信號和環境噪音有關.藉助於中心削波可以消除語音信號的低幅度部分,但是,如果削波電平過低就起不到簡化數值的目的,而削波電平太高又會破壞基頻的周期性。
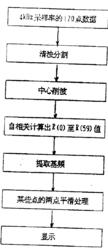 算法流程
算法流程所以,採用語音信號峰值幅度的68.5%作為中心削波電平。自相關數據點應至少包括兩個基頗周期。由於採用4kHz的採樣率,取自相關數據的點數為120,從理論上講,本算法可估計的頻率範圍可以達到最低66.7Hz,最高2kHz。具體算法的流程如下:
這種算法,從採樣到基頻提取,一直到圖形的顯示,可以實時地完成。
基於語音基頻的性別識別方法
性別識別是語音信號處理中一個很重要的課題,他與語音識別、說話人識別、語音通信等都有很大的聯繫。在語音識別和說話人識別實驗中發現,事先知道說話人性別時所得到的正確識別率要比不知道說話人性別時高。在語音通信中,可以基於性別識別建立性別有關的語音特徵參數提取方案,減少特徵參數的維數,減少傳輸頻寬。由此可見性別識別是語音識別研究中的一個重要問題,具有重要意義。
基音頻率是性別識別最重要的判別依據。他反映了說話人發濁音時的聲帶振動頻率。一般而言,男聲的基音頻率分布範圍為0~200Hz,女聲的基音頻率分布範圍為200~500Hz。因此,準確而可靠地估計基音周期對於說話人性別識別非常重要。
特徵提取方法
基音頻率提取包括基音頻率候選估計和後處理兩個必要步驟。基音頻率候選估計法主要有兩類:時域估計法和變換域估計法。常用的時域估計方法有自相關函式法和平均幅度差函式法等;變換域方法有頻域法和倒譜域法等。
採用歸一化幅度差平方和函式法(sumofmagnitudedifferencesquarefunction,SMDSF)來進行基音周期候選估計,並利用viterbi算法進行後處理,快速、準確的提取基音頻率。採取後處理的目的是使用基音周期全局的信息,糾正基音周期的局部錯誤,通過Viterbi算法可以找到一個最優的基音周期序列,使得發生基音周期誤判錯誤的損失最小。
系統流程描述
利用幅度差平方和函式方法提取訓練及測試語音所有幀的基音頻率,分別基於男女訓練集特徵檔案利用EM參數估計法建立男女兩個高斯混合模型,然後利用已訓練好的兩個模型分別對測試集中語音檔案計算兩個後驗機率值,後驗機率值大的性別類別即為該測試語音檔案的性別類型,最後統計整個測試集的正確率。
