基本概念
 生成隨機網路
生成隨機網路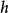 生成隨機網路
生成隨機網路生成隨機網路(generative stochastic network, GSN)是去噪自編碼器的推廣,除可見變數(通常表示為 )之外,在生成馬爾可夫鏈中還包括潛變數 。
GSN 由兩個條件機率分布參數化,指定馬爾可夫鏈的一步:
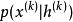 生成隨機網路
生成隨機網路(1) 指示在給定當前潛在狀態下如何產生下一個可見變數。這種 ‘‘重建分布’’ 也可以在去噪自編碼器、 RBM、 DBN 和 DBM 中找到。
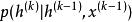 生成隨機網路
生成隨機網路(2) 指示在給定先前的潛在狀態和可見變數下如何更新潛在狀態變數。
去噪自編碼器和 GSN 不同於經典的機率模型(有向或無向),它們自己參數化生成過程而不是通過可見和潛變數的聯合分布的數學形式。相反,後者如果存在則隱式地定義為生成馬爾可夫鏈的穩態分布。存在穩態分布的條件是溫和的,並且需要與標準 MCMC 方法相同的條件。這些條件是保證鏈混合的必要條件,但它們可能被某些過渡分布的選擇(例如,如果它們是確定性的)所違反。
訓練準則
我們可以想像 GSN 不同的訓練準則。
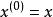 生成隨機網路 生成隨機網路
生成隨機網路 生成隨機網路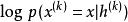 生成隨機網路 生成隨機網路
生成隨機網路 生成隨機網路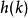 生成隨機網路 生成隨機網路
生成隨機網路 生成隨機網路由 Bengio等提出和評估的只對可見單元上對數機率的重建,如套用於去噪自編碼器。通過將 夾合到觀察到的樣本並且在一些後續時間步處使生成 的機率最大化,即最大化 ,其中給定 後, 從鏈中採樣。為了估計相對於模型其他部分的 的梯度, Bengio等使用了重參數化技巧。
回退訓練過程可以用來改善訓練 GSN 的收斂性。
重參數化技巧
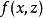 生成隨機網路
生成隨機網路 生成隨機網路
生成隨機網路傳統的神經網路對一些輸入變數 x 施加確定性變換。當開發生成模型時,我們經常希望擴展神經網路以實現 x 的隨機變換。這樣做的一個直接方法是使用額外輸入 z(從一些簡單的機率分布採樣得到,如均勻或高斯分布)來增強神經網路。神經網路在內部仍可以繼續執行確定性計算,但是函式 對於不能訪問 z 的觀察者來說將是隨機的。假設 是連續可微的,我們可以使用反向傳播計算訓練所需的梯度。
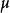 生成隨機網路
生成隨機網路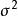 生成隨機網路
生成隨機網路作為示例,讓我們考慮從均值 和方差 的高斯分布中採樣 y 的操作:
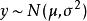 生成隨機網路 生成隨機網路 生成隨機網路
生成隨機網路 生成隨機網路 生成隨機網路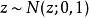 生成隨機網路
生成隨機網路因為 y 的單個樣本不是由函式產生的,而是由一個採樣過程產生,它的輸出會隨我們的每次查詢變化,所以取 y 相對於其分布的參數 和 的導數似乎是違反直覺的。然而,我們可以將採樣過程重寫,對基本隨機變數 進行轉換以從期望的分布獲得樣本:
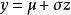 生成隨機網路 生成隨機網路
生成隨機網路 生成隨機網路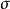 生成隨機網路
生成隨機網路我們將其視為具有額外輸入 z 的確定性操作,可以通過採樣操作來反向傳播。至關重要的是,額外輸入是一個隨機變數,其分布不是任何我們想對其計算導數的變數的函式。如果我們可以用相同的 z 值再次重複採樣操作,結果會告訴我們或的微小變化將會如何改變輸出。
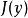 生成隨機網路
生成隨機網路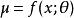 生成隨機網路
生成隨機網路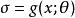 生成隨機網路
生成隨機網路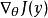 生成隨機網路
生成隨機網路能夠通過該採樣操作反向傳播允許我們將其併入更大的圖中。我們可以在採樣分布的輸出之上構建圖元素。例如,我們可以計算一些損失函式 的導數。我們還可以構建這樣的圖元素,其輸出是採樣操作的輸入或參數。例如,我們可以通過 和 構建更大的圖。在這個增強圖中,我們可以通過這些函式的反向傳播導出 。
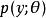 生成隨機網路
生成隨機網路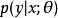 生成隨機網路
生成隨機網路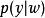 生成隨機網路
生成隨機網路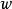 生成隨機網路
生成隨機網路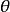 生成隨機網路 生成隨機網路 生成隨機網路
生成隨機網路 生成隨機網路 生成隨機網路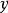 生成隨機網路 生成隨機網路
生成隨機網路 生成隨機網路在該高斯採樣示例中使用的原理能更廣泛地套用。我們可以將任何形為 或 的機率分布表示為 ,其中 是同時包含參數 和輸入 的變數 (如果適用的話)。給定從分布 採樣的值 (其中 可以是其他變數的函式),我們可以將
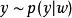 生成隨機網路
生成隨機網路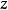 生成隨機網路 生成隨機網路 生成隨機網路 生成隨機網路 生成隨機網路 生成隨機網路 生成隨機網路 生成隨機網路 生成隨機網路
生成隨機網路 生成隨機網路 生成隨機網路 生成隨機網路 生成隨機網路 生成隨機網路 生成隨機網路 生成隨機網路 生成隨機網路其中 是隨機性的來源。只要 是幾乎處處連續可微的,我們就可以使用傳統工具(例如套用於 的反向傳播算法)計算 相對於 的導數。至關重要的是, 不能是 的函式,且 不能是 的函式。這種技術通常被稱為 重參數化技巧(reparametrization trick)、 隨機反向傳播(stochastic back-propagation) 或擾動分析(perturbation analysis)。
回退訓練過程
回退訓練過程由 Bengio等提出,作為一種加速去噪自編碼器生成訓練收斂的方法。不像執行一步編碼-解碼重建,該過程有代替的多個隨機編碼-解碼步驟組成(如在生成馬爾可夫鏈中),以訓練樣本初始化,並懲罰最後的機率重建(或沿途的所有重建)。
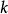 生成隨機網路
生成隨機網路訓練 個步驟與訓練一個步驟是等價的(在實現相同穩態分布的意義上),但是實際上可以更有效地去除來自數據的偽模式。
判別性GSN
生成隨機網路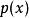 生成隨機網路
生成隨機網路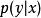 生成隨機網路
生成隨機網路GSN的原始公式用於無監督學習和對觀察數據 的 隱式建模,但是我們可以修改框架來最佳化 。
例如, Zhou and Troyanskaya以如下方式推廣 GSN,只反向傳播輸出變數上的重建對數機率,並保持輸入變數固定。他們將這種方式成功套用於建模序列蛋白質二級結構),並在馬爾可夫鏈的轉換運算元中引入(一維)卷積結構。重要的是要記住,對於馬爾可夫鏈的每一步,我們需要為每個層生成新序列,並且該序列於在下一時間步計算其他層的值(例如下面一個和上面一個)的輸入。
因此, 馬爾可夫鏈確實不只是輸出變數(與更高層的隱藏層相關聯),並且輸入列僅用於條件化該鏈,其中反向傳播使得它能夠學習輸入序列如何條件化由馬爾夫鏈隱含表示的輸出分布。因此這是在結構化輸出中使用 GSN 的一個例子。
生成隨機網路 生成隨機網路Zöhrer and Pernkopf引入了一個混合模型,通過簡單地添加(使用不同的權重)監督和非監督成本即 和 的重建對數機率,組合了監督目標(如上面的工作)和無監督目標(如原始的 GSN)。 Larochelle and Bengio以前RBM 中就提出了這樣的混合標準。他們展示了在這種方案下分類性能的提升。
