
簡介
 深度強化學習的框架
深度強化學習的框架深度學習具有較強的感知能力,但是缺乏一定的決策能力;而強化學習具有決策能力,對感知問題束手無策。因此,將兩者結合起來,優勢互補,為複雜系統的感知決策問題提供了解決思路。
原理框架
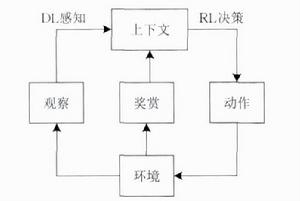 DRL原理框架
DRL原理框架DRL是一種端對端(end-to-end)的感知與控制系統,具有很強的通用性.其學習過程可以 描述為:
(1)在每個時刻agent與環境互動得到一個高維度的觀察,並利用DL方法來感知觀察,以得到具體的狀態特徵表示;
(2)基於預期回報來評價各動作的價值函式,並通過某種策略將當前狀態映射為相應的動作;
(3)環境對此動作做出反應,並得到下一個觀察.通過不斷循環以上過程,最終可以得到實現目標的最優策略。
DRL原理框架如圖所示。
DQN算法
DQN算法融合了神經網路和Q learning的方法, 名字叫做 Deep Q Network。
DQN 有一個記憶庫用於學習之前的經歷。在之前的簡介影片中提到過, Q learning 是一種 off-policy 離線學習法, 它能學習當前經歷著的, 也能學習過去經歷過的, 甚至是學習別人的經歷. 所以每次 DQN 更新的時候, 我們都可以隨機抽取一些之前的經歷進行學習. 隨機抽取這種做法打亂了經歷之間的相關性, 也使得神經網路更新更有效率。Fixed Q-targets 也是一種打亂相關性的機理, 如果使用 fixed Q-targets, 我們就會在 DQN 中使用到兩個結構相同但參數不同的神經網路, 預測 Q 估計 的神經網路具備最新的參數, 而預測 Q 現實 的神經網路使用的參數則是很久以前的。有了這兩種提升手段, DQN 才能在一些遊戲中超越人類。
基於卷積神經網路的深度強化學習
由於卷積神經網路對圖像處理擁有天然的優勢,將卷積神經網路與強化學習結合處理圖像數據的感知決策任務成了很多學者的研究方向。
深度Q網路是深度強化學習領域的開創性工作。它採用時間上相鄰的4幀遊戲畫面作為原始圖像輸入,經過深度卷積神經網路和全連線神經網路,輸出狀態動作Q函式,實現了端到端的學習控制。
深度Q網路使用帶有參數θ的Q函式Q(s, a; θ)去逼近值函式。疊代次數為i 時,損失函式為
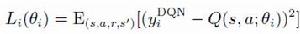 深度強化學習
深度強化學習其中
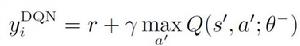 深度強化學習
深度強化學習θi代表學習過程中的網路參數。經過一段時間的學習後, 新的θi更新θ−。具體的學習過程根據:
 深度強化學習
深度強化學習基於遞歸神經網路的深度強化學習
深度強化學習面臨的問題往往具有很強的時間依賴性,而遞歸神經網路適合處理和時間序列相關的問題。強化學習與遞歸神經網路的結合也是深度強化學習的主要形式。
對於時間序列信息,深度Q網路的處理方法是加入經驗回放機制。但是經驗回放的記憶能力有限,每個決策點需要獲取整個輸入畫面進行感知記憶。將長短時記憶網路與深度Q網路結合,提出深度遞歸Q網路(deep recurrent Q network,DRQN),在部分可觀測馬爾科夫決策過程(partiallyobservable Markov decision process, POMDP)中表現出了更好的魯棒性,同時在缺失若干幀畫面的情況下也能獲得很好的實驗結果。
受此啟發的深度注意力遞歸Q網路(deep attentionrecurrent Q network, DARQN)。它能夠選擇性地重點關注相關信息區域,減少深度神經網路的參數數量和計算開銷。
