
簡介
流水線,亦稱管線,是現代計算機處理器中必不可少的部分,是指將計算機指令處理過程拆分為多個步驟,並通過多個硬體處理單元並行執行來加快指令執行速度。其具體執行過程類似工廠中的流水線,並因此得名。流水線技術是一種非常經濟,對提高處理機的運算速度非常有效的技術。採用流水線技術只需要增加少量硬體就能夠把處理機的運算速度提高几倍,它是許多處理機中普遍採用的一種並行處理技術。流水線功能繁雜,種類也非常多;如果按照處理級別來分類,流水線可以有操作部件級、指令級和處理機級。流水線運算屬於操作部件級。流水線運算是指運算器中的操作部件,如浮點加法器、浮點乘法器等可以採用流水線。
分類
按完成的功能分類
單功能流水線:只完成一種如乘法或浮點運算等,多用於數位訊號處理器(DSP),各處理器可並行完成各自的功能,加快整機處理速度。
多功能流水線:在不同情況下可完成不同功能
按連線的方式分類
靜態流水線(Static Pipelining)是指在同一段時間內,多功能流水線中的各個功能段只能按照一種固定的方式連線,實現一種固定的功能。只有當按照這種連線方式工作的所有任務都流出流水線之後,多功能流水線才能重新進行連線,以實現其它功能。
動態流水線(Dynamic Pipelining)是指在同一段時間內,多功能流水線中的各段可以按照不同的方式連線,同時執行多種功能。當然,同時實現多種連線發生是有條件的,即流水線中的各個功能部件之間不能發生衝突。
按處理的數據類型分類
標量流水線:一般數據
向量流水線:矢量數據。X+Y=Z每一個代表一維數據。
流水線結構上分類
線性流水線:指各功能模組順序串列連線,無反饋迴路,如前面介紹的。
非線性流水線:帶有反饋迴路的流水線。
性能指標
衡量一種流水運算線處理方式的性能高低的書面數據主要由吞吐率、效率和加速比這三個參數來決定。
吞吐率
指的是計算機中的流水線在特定的時間內可以處理的任務或輸出數據的結果的數量。流水線的吞吐率可以進一步分為最大吞吐率和實際吞吐率。它們主要和流水段的處理時間、快取暫存器的延遲時間有關,流水段的處理時間越長,快取暫存器的延遲時間越大,那么,這條流水線的吞吐量就越小。因為,線上性流水線中,最大吞吐率Tpmax=流水線時鐘周期△T/1=max(T1,...Ti,..Tm)+T1/1,而其中,m是流水線的段數,i是特定過程段執行時間。如果,一條流水線的段數越多,過程執行時間越長,那么,這條流水線的理論吞吐率就越小。
由此,要對於流水線的瓶頸部分的處理主要在於減少流水段的處理時間。實現的方法一般有兩種:
1、把瓶頸部分的流水線分拆,以便任務可以充分流水處理。流水段的處理時間過長,一般是由於任務堵塞造成的,而任務的堵塞會導致流水線不能在同一個時鐘周期內啟動另一個操作,可以把流水段劃分,在各小流水段中間設定快取暫存器,緩衝上一個流水段的任務,使流水線充分流水。假如X流水段的處理時間為3T,可以把X流水段再細分成3小段,這樣,每小段的功能相同,但是處理時間已經變成3T/3=T了。
2、在瓶頸部分設定多條相同流水段,並行處理。對付流水段的處理時間過長,還有另外一種方法,那就是把瓶頸流水段用多個相同的並聯流水段代替,在前面設一個分派單元來對各條流水段的任務進行分派。仍然假設瓶頸流水段的處理時間是△3T,那么經過3條並聯流水段的同時處理,實際需要的時間只是△T。這樣,就達到了縮短流水段處理時間,但這種方法比較少以採用,因為要3段相同的流水段並聯,成本較高,而且,分派單元會比較麻煩處理。
加速比
是指某一流水線如果採用串列模式之後所用的時間T0和採用流水線模式後所用時間T的比值,數值越大,說明這條流水線的工作安排方式越好。
效率
使用效率:指流水線中,各個部件的利用率。由於流水線在開始工作時存在建立時間;在結束時存在排空時間,各個部件不可能一直在工作,總有某個部件在某一個時間處於閒置狀態。用處於工作狀態的部件和總部件的比值來說明這條流水線的工作效率。
影響因素
流水線處理方式是一種時間重疊並行處理的處理技術,具體地說,就是流水線可以在同一個時間啟動2個或以上的操作,藉此來提高性能。為了實現這一點,流水線必須要時時保存暢通,讓任務充分流水,但在實際中,會出現2種情況使流水線停頓下來或不能啟動:
1、多個任務在同一時間周期內爭用同一個流水段。
2、數據依賴。比如,A運算必須得到B運算的結果,但是,B運算還沒有開始,A運算動作就必須等待,直到B運算完成,兩次運算不能同時執行。
解決方案:
第一種情況,增加運算部件的數量來使他們不必爭用同一個部件;
第二種情況,用指令調度的方法重新安排指令或運算的順序。
資料庫中的流水線運算
流水線運算
流水線計算方法是指將表達式中多個關係運算組合成一個操作流水線來實現,即將一個運算的結果作為輸入直接傳送到下一個運算。例如:
Πcustomer-name(σbalance<2500(account)customer)
用關係代數表達式樹表示流水線計算的過程如圖所示:
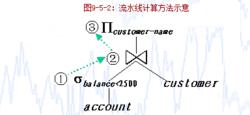 流水線運算
流水線運算說明:如圖所示,關係account上的選擇運算產生一個結果元組①之後,立即就與關係customer進行自然連線;自然連線運算產生一個結果元組②之後,立即就在該元組②上做投影;最後投影運算產生一個最終的結果元組③。
流水線計算方法模型
實體化計算方法可以直接利用各個關係運算的算法實現(即操作代碼),而流水線計算方法雖然具有減少產生臨時關係、提高查詢執行效率的優點,但它需要對流水線中的每一運算建模,以便能夠重用各個關係運算的操作代碼。最簡單的模型就是:每一關係運算都作為系統內獨立的進程或執行緒,它從流水化的輸入中接受元組流,並產生一個元組流作為其輸出。對於流水線中的每對相鄰運算,下圖為流水線計算方法模型。
 流水線運算
流水線運算流水線計算方法的執行
流水線計算方法可按以下兩種方式之一來執行:
⑴ 需求者驅動:系統不停地向位於流水線頂端的操作發出需要元組的請求。每當一個運算收到需要元組的請求時,它就計算下一個或多個元組並返回它們;
⑵ 生產者驅動:各個運算並不等待元組請求,而是不停地產生元組。流水線底端的每個操作不斷地產生元組並將它們放在輸出緩衝區中,直到緩衝區滿為止。從效果上看需求者驅動策略是一個"拉"的過程;而生產者驅動策略是一個"推"的過程。
