![暗網[漢語詞語、網際網路術語]](/img/e/63c/nBnauM3XxMTM5ITOwETO1ATN0UTMyITNykTO0EDMwAjMwUzLxkzLxQzLt92YucmbvRWdo5Cd0FmL0E2LvoDc0RHa.jpg "暗網[漢語詞語、網際網路術語]")
定義
暗網(不可見網,隱藏網)是指那些儲存在網路資料庫里、不能通過超連結訪問而需要通過動態網頁技術訪問的資源集合,不屬於那些可以被標準搜尋引擎索引的表面網路。
麥可·伯格曼將當今網際網路上的搜尋服務比喻為像在地球的海洋表面的拉起一個大網的搜尋,大量的表面信息固然可以通過這種方式被查找得到,可是還有相當大量的信息由於隱藏在深處而被搜尋引擎錯失掉。絕大部分這些隱藏的信息是須通過動態請求產生的網頁信息,而標準的搜尋引擎卻無法對其進行查找。傳統的搜尋引擎“看”不到,也獲取不了這些存在於暗網的內容,除非通過特定的搜查這些頁面才會動態產生。於是相對的,暗網就隱藏了起來。
來源和現狀
Hidden Web最初由Dr.Jill Ellsworth於1994年提出,指那些沒有被任何搜尋引擎索引註冊的網站:
“這些網站可能已經被合理地設計出來了,但是他們卻沒有被任何搜尋引擎編列索引,以至於事實上沒有人能找到他們。我可以這樣對這些不可見的網站說,你們是隱藏了的。”
另外早期使用“不可見網路”這一術語,是一家叫做“個人圖書館軟體”公司的布魯斯·芒特(產品開發總監)和馬修·B·科爾(執行長和創建人)發明的。當他們公司在1996年12月推出和發行的一款軟體時,他們對暗網工具的有過這樣的一番描述:
不可見網路這一術語其實並不準確,它描述的只是那些在暗網中,可被搜尋的資料庫不被標準搜尋引擎索引和查詢的內容,而對於知道如何進入訪問這些內容的人來說,它們又是相當可見的。
第一次使用暗網這一特定術語,是2001年伯格曼的研究當中。
從信息量來講,與能夠索引的數據相比,“暗網”更是要龐大得多。根據Bright Planet公司此前發布的一個名為《The Deep Web-Surfacing The Hidden Value》(深層次網路,隱藏的價值)白皮書中提供的數據,“暗網”包含100億個不重複的表單,其包含的信息量是“非暗網”的40倍,有效高質內容總量至少是後者的1000倍到2000倍。更讓人無所適從的是,Bright Planet發現,無數網站越來越像孤立的系統,似乎沒有打算與別的網站共享信息,如此一來,“暗網”已經成為網際網路新信息增長的最大來源,也就是說,網際網路正在變得“越來越暗”。
當然,所謂“暗網”,並不是真正的“不可見”,對於知道如何訪問這些內容的人來說,它們無疑是可見的。2001年,Christ Sherman、GaryPrice對Hidden Web定義為:雖然通過網際網路可以獲取,但普通搜尋引擎由於受技術限制而不能或不作索引的那些文本頁、檔案或其它通常是高質量、權威的信息。根據對HiddenWeb的調查文獻得到了如下有意義的發現:
Hidden Web大約有307,000個站點,450,000個後台資料庫和1,258,000個查詢接口。它仍在迅速增長,從2000年到2004年,它增長了3~7倍。
Hidden Web內容分布於多種不同的主題領域,電子商務是主要的驅動力量,但非商業領域相對占更大比重。
當今的爬蟲並非完全爬行不到Hidden Web後台資料庫內,一些主要的搜尋引擎已經覆蓋Hidden Web大約三分之一的內容。然而,在覆蓋率上當前搜尋引擎存在技術上的本質缺陷。
Hidden Web中的後台資料庫大多是結構化的,其中結構化的是非結構化的3.4倍之多。
雖然一些Hidden Web目錄服務已經開始索引Web資料庫,但是它們的覆蓋率比較小,僅為0.2%~15.6%。
Web資料庫往往位於站點淺層,多達94%的Web資料庫可以在站點前3層發現。
1.Hidden Web大約有307,000個站點,450,000個後台資料庫和1,258,000個查詢接口。它仍在迅速增長,從2000年到2004年,它增長了3~7倍。
2.Hidden Web內容分布於多種不同的主題領域,電子商務是主要的驅動力量,但非商業領域相對占更大比重。
3.當今的爬蟲並非完全爬行不到Hidden Web後台資料庫內,一些主要的搜尋引擎已經覆蓋Hidden Web大約三分之一的內容。然而,在覆蓋率上當前搜尋引擎存在技術上的本質缺陷。
4.Hidden Web中的後台資料庫大多是結構化的,其中結構化的是非結構化的3.4倍之多。
5.雖然一些Hidden Web目錄服務已經開始索引Web資料庫,但是它們的覆蓋率比較小,僅為0.2%~15.6%。
6.Web資料庫往往位於站點淺層,多達94%的Web資料庫可以在站點前3層發現。
分類
它分為兩種:
一種是技術的原因,很多網站本身不規範、或者說網際網路本身缺少統一規則,導致了搜尋引擎的爬蟲無法識別這些網站內容並抓取,這不是搜尋引擎自身就能解決的問題,而是有賴整個網路結構的規範化,百度的“阿拉丁計畫”、谷歌的“雲計算”就是要從根本解決這一問題。
另一個原因則是很多網站根本就不願意被搜尋引擎抓取,比如考慮到著作權保護內容、個人隱私內容等等,這更不是搜尋引擎能解決的問題了。如果他們能被搜尋引擎抓取到,就屬於違法了。
數據顯示,能夠搜尋到的數據僅占全部信息量的千分之二。而對暗網的發掘能擴大搜尋資料庫,使人們能夠在搜尋引擎上搜尋到更多的網頁、信息。
幾乎任何有抱負的通用搜尋引擎都有一個共同的夢想:整合人類所有信息,並讓大家用最便捷的方式各取所需。
對此,百度說:“讓人們最便捷地獲取信息,找到所求”;谷歌說:“整合全球信息,使人人皆可訪問並從中受益”。這兩者表達的實際上是同一個願景。
然而,這注定是一項不可能完成的任務。據科學家估測,人類信息大概只有0.2%實現了web化,並且這個比例很可能在持續降低。更甚的是,即便在已經Web化的信息中,搜尋引擎的蜘蛛能抓取到的和不能抓取到的比例為1:500。
處理
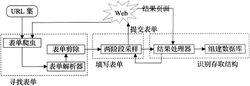 暗網spider結構圖
暗網spider結構圖為實現自動獲取Hidden Web頁面的任務,此爬蟲必須能自動尋找表單,填寫表單,然後獲取和識別結果頁面。HiddenWeb爬蟲系統結構如圖所示
1.尋找Hidden Web入口頁面
Web上存在多種多樣的表單,同時表單上含有各種各樣的元素,如單選按鈕、下拉列表框、文本框等,有些還是用戶自定義的,因此處理所有的表單是比較困難的。為此,需要先解析HTML頁面,獲取要研究的表單類型,同時從中抽取有用信息。本文要研究的是不含或含有少量的文本框元素,其它類型元素都具有默認值的表單。這很容易通過解析HTML表單來完成,如可以使用標記序列樹或DOM(文檔對象模型)來過濾出要研究的表單。
2.自動提交表單
當搜尋表單提供了每一表單元素所有可能的值時,直接的方法是對具有少量的文本框元素使用空串作為默認值,窮盡表單其他元素所有可能值的組合來填寫表單,獲取後台資料庫全部的數據。此方法存在兩個問題:①處理過程非常耗時;②在窮盡所有可能值組合之前,也許已經獲取了所有或大部分的後台資料庫數據,從而出現了重複提交;③多個欄位組合可能存在語義上的衝突。Hidden Web爬蟲設計的目標是使用最少的資源(如提交時間或次數等)獲取特定Hidden Web站點內最大量的數據,然而不能保證對所有表單使用有限次的提交可以獲取後台資料庫的全部數據,因此有必要再次傳送查詢來確定是否已獲取了全部數據。本文提出一種兩階段採樣爬行策略以充分獲取Hidden Web數據,它分為如下兩個步驟:
首先使用表單提供的默認值來提交;
然後對表單元素值組合進行採樣以確定默認值提交是否返回了後台資料庫的所有數據,若返回了後台資料庫所有或大部分數據則可以結束提交過程。否則,在爬蟲所具有資源限制範圍內窮盡所有可能值的組合。
1.首先使用表單提供的默認值來提交;
2.然後對表單元素值組合進行採樣以確定默認值提交是否返回了後台資料庫的所有數據,若返回了後台資料庫所有或大部分數據則可以結束提交過程。否則,在爬蟲所具有資源限制範圍內窮盡所有可能值的組合。
如果C次採樣提交每次都產生了新的記錄,則窮盡表單元素其它可能值組合來提交表單,直到滿足特定的結束條件。然而在繼續提交表單前,先要估計完成這樣的操作所需的最大剩餘時間和用於存儲所有結果記錄所需的最大空間。可以指定如下幾個參數來完成此階段的任務:最大查詢提交次數、最大存儲空間和最大剩餘時間等。
可以通過疊加每次查詢所返回的數據量來估計所需最大存儲空間S。類似地可以估計最大剩餘時間T。
在窮盡階段,可以使用幾個參數閥值來提前結束提交過程。包括:
•獲取Web資料庫數據的百分比:通過估計Web資料庫百分比以確定獲取了多少數據以後可以結束提交過程。
•查詢提交次數:通過確定查詢提交次數來減輕站點的負擔。
•獲取數據的數量:即獲取了多少惟一性的Web資料庫信息。
•提交時間:爬行某特定站點需要多長時間。
上述每一個閥值或其組合都可以在窮盡階段提前結束爬蟲爬行。
3.識別和存取查詢結果
對表單提交操作產生的回響主要有如下幾種情況:回響頁含有後台資料庫部分或所有數據;回響頁不僅包含有數據還包含連結;回響頁含有數據和原始表單結構;回響頁可能是另一張需要進一步填寫的表單;錯誤頁面通知;無記錄通知或需要缺失欄位。這一步主要是針對這些可能出現的情況進行處理。然後從含有豐富數據的頁面中使用信息抽取工具抽取結構化的數據構建數據,以進一步提供信息檢索服務。
現狀
迎戰“暗網”
對於龐大的“暗網”,搜尋業界通行的策略主要有兩種:其一,構建更有針對性的“暗網”爬蟲,以便獲取後台資料庫;其二,與“暗網”網站合作,實現信息的對接和上浮。
對於第一種策略,它始終貫穿搜尋引擎的發展過程。百度產品部相關人士對此表示,針對搜尋引擎的升級和更新中,大部分與“暗網”問題有關,只不過對普通用戶來講,他們很難察覺。
第二種策略似乎更成效。不管是國外的谷歌、雅虎,還是國內的百度,都有針對性的計畫,並且用戶已經體驗到了它們帶來的變化。
富含信息查詢模組技術
對於暗網爬蟲來說,一個簡單粗暴的方式是:將各個輸入框肯呢過的輸入值組合起來形成查詢,比如機票查詢來說,將所有出發城市、所有目的城市和時間範圍的選項一一組合,形成大量的查詢,提交給垂直搜尋引擎,從其搜尋結果里提煉資料庫記錄。
GOOGLE對此提出了解決方案,稱之為富含信息查詢模組技術。
假設為了描述一個職位,完整的查詢由3個不同的屬性構成:出發城市、到達城市和出發日期。如果在搜尋引擎提交查詢的時候,部分屬性被賦予了值,而其他屬性不賦值,則這幾個賦值屬性一起構成了一個查詢模組。
如果模組包含一個屬性,則稱之為一維模組。圖中模組1是一維模組,模組2和模組3是二維模組,模組4是三維模組。
模組1={出發城市 }
模組2={出發城市,到達城市 }
模組3={到達城市,出發日期 }
模組4={出發城市,到達城市和出發日期 }
對於某個固定的查詢模組來說,如果給模組內每個屬性都賦值,形成不同的查詢組合,提交給垂直搜尋引擎,觀察所有返回頁面的內容,如果相互之間內容差異較大,則這個查詢模組就是富含信息查詢模組。但是這將是一個龐大的查詢組合基數,為了進一步減少提交的查詢數目。GOOGLE的方案使用了ISIT算法。
ISIT算法的基本思路是:首先從一維模組開始,對一維查詢模組逐個查詢,看其是否富含信息查詢模組,如果是的話,則將這個一模模組擴展到二維,再次依次查詢對應的二維模組,如此類推,逐步增加維數,直到再無法找到富含信息查詢模組為止。通過這種方式,就可以找到絕大多數富含信息查詢模組,同時也儘可能減少了查詢總數,有效達到了目的。
