新型資料庫產生的背景
傳統資料庫技術的產生不是為了分析海量數據,而是為了數據記錄、事務處理(OLTP)。當數據量不斷膨脹之後,用戶就會產生越來越多的分析需求,而傳統資料庫在分析處理時,整體性能會大大降低。造成此問題的原因如下:傳統行存儲導致大量無效 I/O
行存儲方式設計思想是以事務處理為主,存儲結構異常複雜。由於數據頁結構和MVCC(多版本並發控制)的原因,每個數據頁必須讀到記憶體中,導致每次查詢必須讀取大量無用數據。這種數據存儲方式造成磁碟I/O成為了限制性能的主要因素。雖然磁碟成本在不斷下降,但數據傳輸效率並沒有根本的改變。因此,在處理的數據量不大時往往影響不大,但在處理海量數據時, 性能下降問題就會突現出來。
傳統索引不適於海量數據
傳統行存資料庫索引需要手工設定,對套用不完全透明,隨場景和需求的變化需要不斷調整,人工維護成本很高。並且傳統索引占用存儲空間很大,甚至高於數據本身,造成查詢效率的下降。
數據裝載速度慢
因為索引需要重新創建,載入性能會變的很糟糕。分析型架構系統要解決這些個問題,必須最大限度地減少磁碟 I/O ,提升查詢效率,減小人工維護成本。南大通用分析型資料庫GBase8a (以下簡稱GBase 8a)通過列存儲模式、數據壓縮、智慧型化的索引、並行處理、並發控制、高效的查詢最佳化器等技術,使得上述問題得到有效解決。以下各節將描述 GBase 8a 的創新架構如何實現這些目標。
隨著雲計算和大數據時代的到來,行業數據和移動網際網路套用對數據交易處理的實時性和規模提出更高的要求。例如,淘寶每天千萬量級交易筆數,50GB匯總結果,7億條日誌記錄,1.5PB原始數據記錄;FaceBook每天處理27億次Like按鈕點擊,上傳3億張圖片,由人工或系統自動執行的請求達到7萬次,吸收逾500TB新數據。傳統資料庫面臨前所未有的挑戰:首先,數據處理需求與傳統資料庫平台硬體擴展的差距不斷擴大,傳統的資料庫性能和TB級數據處理規模已不能滿足海量數據的實時交易查詢需求。其次,通過不斷堆疊高性能盤陣獲取性能提升的傳統擴展方式,使得底層硬體和資料庫軟體採購成本不斷攀升。在性能和成本的雙重壓力之下,資料庫需要尋找突破之路。淘寶、Facebook、Google、騰訊、百度等網際網路企業紛紛展開探索,面向不同套用的各種新型資料庫應運而生。
新型資料庫設計思想
三個“1/10”把執行同樣一條查詢語句所需要磁碟的 I/O 降低到傳統行存儲資料庫的1/10 以下;
在啟動壓縮的情況下,同樣的裸數據載入到資料庫後占有的磁碟空間是傳統行存儲資料庫的 1/10 以下;
人工管理費用(安裝、調試、最佳化、維護、擴展等)是傳統行存儲資料庫的1/10 以下。
兩個“10 倍以上”
在海量數據分析型套用中,平均綜合查詢性能(複雜查詢、即席查詢、模糊查詢、分頁查詢、TOP-N 查詢等)是傳統行存儲資料庫的 10 倍以上;
壓縮比 10 倍以上。
新型資料庫技術創新
新型資料庫採用分散式並行計算架構,部署於X86通用伺服器,滿足大數據實時交易需求,成本低、擴展性高,突破了傳統資料庫性能瓶頸。分散式非關係型資料庫技術創新
非關係型資料庫即NoSQL,拋棄了關係資料庫複雜的關係操作、事務處理等功能,僅提供簡單的鍵值對(Key, Value)數據的存儲與查詢,換取高擴展性和高性能,滿足論壇、部落格、SNS、微博等網際網路類套用場景下針對海量數據的簡單操作需求。主要技術創新為:
(1) 簡單的數據操作換取高效回響。NoSQL僅支持按照Key(關鍵字)來存儲和查詢Value(數據),不支持對非關鍵字數據列的高效查詢;因數據操作簡單、數據間一般不需要關聯操作,故系統可支持高並發和較快的回響速度。
(2) 多種一致性策略滿足業務需求。不同於傳統關係型資料庫僅支持強一致性策略,NoSQL還支持弱一致性和最終一致性等多種策略,可根據套用場景進行對應配置。例如,對寫入操作頻繁,但數據讀取最新版本要求並不嚴格的套用,如網際網路網頁數據的存儲和分析套用,可以採用最終一致性策略;而對訂購關係存儲的套用,則必須用強一致性策略,保證總是讀取最新版本數據。
新型分析型資料庫介紹
新型分析型GBase 8a 的架構設計充分滿足了海量數據分析需求,是具有高效複雜統計和分析能力的列存儲關係型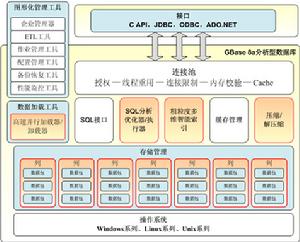
資料庫管理系統。GBase 8a 面向分析型套用領域,以列為基本存儲結構和數據運算對象,結合列數據壓縮處理、並行處理、智慧型索引等新型數據處理技術。
技術特性
·支持標準Linux核心:Cent OS,Redhat, Suse等·支持基於x86-64的標準PC伺服器
·支持本地存儲(Sata, SAS, SSD etc)
·支持陣列部署(SAN,NAS)
·支持SSD,Flash存儲介質作為2級I/O快取
·支持標準SQL
·提供通用API: JDBC,ODBC,CAPI,ADO(.)NET
關鍵指標
·真正的列存儲,數據壓縮比可達到1:5 到 1:20·自動提供粗粒度智慧型索引,高效過濾,膨脹小,免維護
·可支撐10TB級別的結構化數據
·支持並行計算,充分利用現代的 SMP 多核CPU資源
·數據載入速度可達到200GB/小時
·提供MVCC支持,讀寫不阻塞,並發能力大於300個用戶
產品優勢
·高性能列存儲在大大減少了I/O的同時,顯著的提高查詢性能;
智慧型索引大幅提高查詢性能;
非常快的數據載入(單表高達 200GB/小時 的載入速度);
高效的並行 SQL 執行方法,支持 Hash Join、Merge Join和NL Join;
資料庫可擴展性非常高。
·高性價比
市場領先的數據壓縮(從1:5到1:20以上),顯著減少存儲開銷;
減少伺服器的數量,顯著減少數據倉庫運營成本。
·高可用性
不要求設計特定的數據模型,例如要求星型模型, 雪花模型;
沒有物化視圖的要求,不要求複雜的數據分區或索引;
易於實施和管理,只需要傳統資料庫 1/10 的管理;
與主要商業智慧型工具兼容,如 Cognos、Business Objects、Pentaho、JasperSoft、SPSS;
支持市場上主流64位作業系統。
