
文檔訪問概述
在信息化建設發展的過程中,作為信息主要載體的文檔,成為我們工作生活中不可或缺的一部分,其中對基於XML格式的流式辦公文檔的套用最為廣泛。目前世界主流的流式辦公文檔格式主要有3種:標準為IS0/IEC26300;2006的開放文檔格式(open document format,ODF)、標準為ISO/IEC 29500:2008的OOXML(officeopen XML)以及標準為GB/T20916—2007的標文通。這3種流式文檔格式都基於XML,相應的處理技術也由原來VBA、宏等方式逐漸過渡到利用XML相關技術進行處理。
在早期,用戶對流式文檔的操作,主要基於辦公文檔處理軟體,並可以使用VBA、宏等方式擴展對辦公文檔的處理。帶來的問題是,傳統的方式效率低,速度慢,所能處理的文檔格式單一,因其過分依賴辦公軟體產品,使之對於不同格式的流式文檔而言,無法通過同一個辦公軟體實現操作互通,給用戶帶來不便。
流式辦公文檔採用基於XML的格式之後,對XML文檔的各種訪問技術也被用於對流式辦公文檔的處理。針對基於XML格式的文檔,出現了很多XML數據訪問技術,如:XPath、XSLT、DOM和SAX、XQuery、LINQ、相應格式的API/BD、UOML、ODQ等。
XML文檔訪問
隨著XML(eXtensible Markup Language)在電子商務、政務、網路出版和移動通信等領域的廣泛套用,越來越多的公司把XML作為其存放信息或與外部世界交換信息的手段。XML已經成為web環境中描述數據的標準,如何實現XML文檔的安全訪問控制是進行數據保護的一項重要內容。當這些XML格式的信息存儲在計算機時,如果包含了比較敏感的數據,就需要一種靈活高效的訪問控制機制,既保證合法用戶能夠方便快捷地訪問資源,又要阻止非法用戶的訪問請求或合法用戶的非法訪問請求。
國內外對XML文檔的訪問控制的研究有很多。其中自主訪問控制策略DAC具有相當大的缺陷,它是建立在用戶本身能夠保證客體的可信性的假設基礎上的,這個假設通常不成立;基於角色的訪問控制策略RBAC是一種靈活而有效的訪問控制策略,但在擁有多個安全等級的信息系統中效果不佳;基於規則的訪問控制可以解決這些問題,BLP模型是一種基於規則的訪問控制模型,源自軍事套用領域,對一般套用過於嚴格,但又有許多優點,根據實際需求進行改進並得到一個新的DBLP模型。
文檔訪問控倒
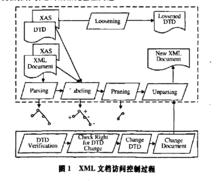 XML文擋訪問控制過程
XML文擋訪問控制過程支持讀操作的訪問控制模型在處理讀操作時的工作過程如圖中虛線部分所示:
當用戶請求訪問XML文檔時首先將文檔解析為DOM(Document Object Model)樹。
根據文檔的DTD(Document‘Type Definition)及存放文檔授權信息的XAS(XML Access Sheets)標記DOM樹,給文檔中的每個節點都設定授權符號(+允許訪問,一禁止訪問)。
將DOM樹中所有授權符號為“一”的節點移除,將剩下的節點轉化為XML格式返同給用戶。
移除某些節點而形成的新的文檔可能不符合原來的DTD。通過將DTD中所有的元素和屬性都設定為可選的來解決該問題,此過程稱為loosening DTD。用戶只能看到他有權訪問的那部分文檔,這樣就確保了數據的保密性。然而,這些模型沒有詳細研究更新操作的訪問控制,也沒有考慮由於更新操作引起的數據完整性問題。
如果向以上支持讀操作的模型引入更新操作以支持用戶的更新請求,則要增加如圖I實線框內所示的訪控制過程,用以處理更新操作帶來的有效性驗證問題。具體步驟為:
通過DTD驗證(DTD verification)確認更新操作執行之後是否引起XML文檔結構的改變,使其不再符合原來的DTD。
如果文檔的結構發生改變,對原有的DTD不再有效,則檢查用戶是否具有修改原有DTD的許可權。
如果用戶具有修改DTD的許可權,則修改DTD並更新文檔;否則,不能修改DTD並拒絕執行操作。
1.當用戶請求訪問XML文檔時首先將文檔解析為DOM(Document Object Model)樹。
2.根據文檔的DTD(Document‘Type Definition)及存放文檔授權信息的XAS(XML Access Sheets)標記DOM樹,給文檔中的每個節點都設定授權符號(+允許訪問,一禁止訪問)。
3.將DOM樹中所有授權符號為“一”的節點移除,將剩下的節點轉化為XML格式返同給用戶。
4.移除某些節點而形成的新的文檔可能不符合原來的DTD。通過將DTD中所有的元素和屬性都設定為可選的來解決該問題,此過程稱為loosening DTD。用戶只能看到他有權訪問的那部分文檔,這樣就確保了數據的保密性。然而,這些模型沒有詳細研究更新操作的訪問控制,也沒有考慮由於更新操作引起的數據完整性問題。
如果向以上支持讀操作的模型引入更新操作以支持用戶的更新請求,則要增加如圖I實線框內所示的訪控制過程,用以處理更新操作帶來的有效性驗證問題。具體步驟為:
5.通過DTD驗證(DTD verification)確認更新操作執行之後是否引起XML文檔結構的改變,使其不再符合原來的DTD。
6.如果文檔的結構發生改變,對原有的DTD不再有效,則檢查用戶是否具有修改原有DTD的許可權。
7.如果用戶具有修改DTD的許可權,則修改DTD並更新文檔;否則,不能修改DTD並拒絕執行操作。
現有的DTD驗證方法解析被更新操作更改了的XML文檔,生成新的DOM樹,之後通過遍歷每個節點來比較新的DOM樹與DTD。這個DTD驗證過程需要在記憶體中保留2個DOM樹,這將消耗大量的記憶體窯間,解析及搜尋DOM樹也降低了訪問控制的速度訪問控制技術通過定義操作類型來明確區分更新操作的語義,避免了基於DOM樹的驗證和重複標記過程。
訪問控制實現
訪問控制系統必須始終保存那些檢查訪問許可權所需的信息,很多不必要的許可權檢查也被重複多次,多餘的工作降低了訪問控制的速度,可以通過將訪問控制過程劃分為2步來解決以上問題:
根據訪問授權信息得出用戶的許可權類型,如果請求中某些操作的操作類型高於用戶的許可權類型,則這些操作將提前被排除掉,不再進入訪問控制過程的第(2)步,這就節省了隨後的許可權檢查及其他工作。
通過步驟(1)檢查的操作要通過遍歷被標記的DOM樹來判斷它是否能被最終執行。
1.根據訪問授權信息得出用戶的許可權類型,如果請求中某些操作的操作類型高於用戶的許可權類型,則這些操作將提前被排除掉,不再進入訪問控制過程的第(2)步,這就節省了隨後的許可權檢查及其他工作。
2.通過步驟(1)檢查的操作要通過遍歷被標記的DOM樹來判斷它是否能被最終執行。
 分步訪問控制第(1)步
分步訪問控制第(1)步下面通過實例來說明如何使用操作類型及分步訪問控制技術實現XML文檔的訪問控制。
首先進入訪問控制第(1)步,針對圖2中的XML文檔,圖3中用戶Wong的許可權類型是x,因此沒有請求D類型操作的許可權。根據文檔相應的操作類型表可知,插入title元素的操作是D類型的,該操作就被排除掉。其餘2個操作為x類型,被允許進入訪問控制第(2)步。
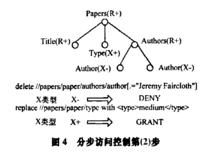 分步訪問控制第(2)步
分步訪問控制第(2)步在第(2)步中,遍歷使用操作類型標記的DOM樹,根據節點上標記的授權信息判斷通過第(1)步檢查的2個操作是否能被最終執行。根據該用戶的訪問授權信息標記的DOM樹。根據圖中元素標記的授權信息可知,對於這個嵌套請求,replace操作通過許可權驗證可以被執行,而delete操作被拒絕。
BLP和DBLP模型
BLP模型
BLP模型是對安全策略形式化的第一個數學模型,它用狀態變數表示系統的安全狀態,用狀態轉換規則來描述系統的變化規則。它是高安全系統中常用的多級安全策略模型。
在BLP多級安全策略模型中,給每一個數據對象定義一個安全級標籤表示它所包含信息的敏感性;同時給每一個用戶定義一個安全級標籤,表示他能訪問什麼樣的數據。每個安全級標籤由兩部分組成:密級和範圍的集合。密級是密級集合中的一個元素,密級集合可表示為:{絕密、機密、秘密、公開}。此集合是全序的,即:絕密>機密>秘密>公開。範圍的集合是系統中非分層元素集合的一個子集,它的元素依賴於所考慮的環境生產部門、銷售部門等等。安全級的集合滿足偏序關係,此偏序關係稱為支配。
多級訪問控制策略模型基於安全級間的支配關係定義了一個安全規則集合來保證系統的安全,系統中每一個操作要由系統通過安全檢查。安全檢查執行“不上讀不下寫”的規則。系統中的數據對象稱為客體,用戶稱為主體,設用戶的安全級為L,數據對象的安全級為L,則安全讀寫規則定義如下:
(1)允許讀:若且唯若L≥L;(2)允許寫:若且唯若L≥L。
若且唯若操作滿足模型的所有規則,此操作才能允許執行,可以有效地保證數據流的保密性。其中稱(1)是BLP模型的簡單安全特性,(2)是BLP模型的特性。
BLP模型是一個很安全的模型,控制信息只能由低向高流動,能滿足對數據保密性要求特別高的需求。本文的立足點是希望這種高安全的模型能套用到一般的系統中去。在實際中這種過安全機制帶來了一些問題:·特性使得只能由下級向上級或平級寫,這樣上級對下級發文就受到限制;並且沒有考慮客體的安全級可以發生變化。也存在不安全的地方:一方面,特性允許低級用戶向高級寫,使得低安全級的信息向高安全級流動,可能破壞高安全客體中數據的完整性;另一方面,高讀低沒考慮是否需要,不符合最小特權原則。
動態BLP模型
動態BLP模型(DBLP模型)的主客體標籤中增加了時限域,時限主要是用來控制客體標籤的動態變化,DBLP模型中的主客體標籤的支配關係首先要比較時限,即若T∈T,標籤之間才具有可比性,否則標籤之間是不可比的。
•結論1 DBLP模型具有和BLP模型相同的保密性。
•證明 在DBLP模型標籤支配關係的形式化定義中添加時限可以完成對訪問許可權的動態控制,Ts∈To的判斷只是一個先行條件,在條件滿足時標籤支配關係的判定完全等同於BLP模型,DBLP模型具有和BLP模型相同的保密性,其保密性是可以保證的。
•結論2 在DBLP模型中可以保證各級客體的完整性。
•證明 如果主體中所有成員都信任客體成員則客體關於主體具有完整性,與客體平級和經過授權的上級都是可信任主體,其寫入操作是可信的,從而不會破壞客體的完整性,DBLP的特性禁止上寫保證了上級客體的完整性,從而能夠保證整個模型中客體的完整性。
流式辦公文檔訪問
處理需求
隨著對流式辦公文檔套用領域的不斷擴展,對其訪問與操作的需求也呈現了多樣化的趨勢,具體如下:
(1)格式無關性需求。由於目前存在的流式辦公文檔格式不統一,對文檔內容的訪問與操作都要依賴於支持相應格式的辦公軟體產品,無法實現離線文檔操作。因此需要有一種統一的方式,能夠對各種格式文檔進行相應的訪問與操作,以禁止文檔底層存在的格式差異,實現文檔格式的互操作;
(2)文檔訪問查詢粒度適中性需求。對於流式辦公文檔而言,用戶常常希望能夠以段落、列表、表格、圖片等基本元素,即文檔的功能點進行訪問與操作,而目前對於流式辦公文檔的訪問操作,要么是利用文檔中提供的元數據對整個文檔實現獲取,粒度較粗糙,無法很好地從文檔真實的內容中準確獲得數據,很多流式文檔的數據資源無法得到有效的共享和利用;要么就是利用XML的相關技術,訪問文檔的結構粒度過於細緻,效率不高的同時,也不利於流式文檔上下文環境內容理解。因此,流式辦文檔訪問查詢粒度的適中性,也成為流式文檔得以進一步套用的阻礙;
(3)文檔操作的簡便實用性需求。利用XML技術對流式文檔進行訪問,無論是專業開發人員還是普通用戶,都需要學習複雜的語言及編程思想,編寫繁瑣的代碼,並且,對文檔邏輯結構要有一定的了解,訪問方式不夠。
處理技術
訪問流式辦公文檔的處理需求的增加,使得相應的處理技術變得非常關鍵。這裡給出XML數據訪問技術的簡要介紹:
(1)XPath。W3C的XPath主要是對XML文檔底層元素和屬性等節點直接進行操作的技術,它是直接針對XML的樹形結構的路徑表達式導航來定位XML文檔中的各個節點。表達直觀,但表達式構造複雜容易出錯,如果不藉助其它工具,則需要手工編寫完成,耗時耗力L6J。
(2)XSLT。XSLT是以XPath為基礎發展起來的,是利用XPath獲取所需節點,並進行相應處理,但表達能力有所限制,不夠靈活。
(3)DOM和SAX。DOM技術是利用樹型結構來對XML文檔中的各個元素(節點)進行處理,使對XML的文檔處理更為靈活,但DOM處理需一次將整個XML文檔載入記憶體,尤其是對於規模較大的xML文檔,其處理速度較慢;為避免DOM載入慢的問題,SAX技術被提出來,利用SAX處理時,不是一次性把整個檔案載入到記憶體中,而是對XML檔案按其對應節點的訪問次序,將檔案的一部分載入入記憶體,相比DOM處理速度大大提升。
(4)XQuery技術。XQuery的查詢描述能力較強,相比其它訪問方式來說,可支持多文檔聯合查詢,但語言過於複雜,普通用戶不易完全掌握。
(5)LINQ技術。隨著對文檔訪問技術的簡化需求增加,微軟在Visual Studio 2008中引入了LINQ,其關鍵技術包括LINQ to XML,該技術提供了一套比DOM更輕量的API,相比使用以往的操作方法,使得處理XML更為容易。
(6)相應格式的API/SDK。目前主流的流式辦公文檔格式ODF,00xML以及UOF,都提供了相應的API或SDK,那么,利用API或SDK來對流式文檔的訪問就可以直接針對文檔的功能點進行直接獲取並進行各種操作,便於實現對文檔的進一步套用或二次開發。
(7)UOML。UOML是OASIS的正式標準,是電子檔案領域針對基於XML的版式文檔的接口標準,它定義了一整套非結構化文檔的操作規範.可以很方便地對版式文檔進行訪問與操作,禁止底層細節問題,能夠實現不同格式文檔的互相讀寫。
(8)ODQ。ODQ是一種專門針對流式辦公文檔的訪問技術。它從用戶使用需求出發,能夠脫離辦公軟體,利用較為通俗的語句,對不同格式的文檔直接獲取其局部內容並進行相應的操作,方便用戶使用;同時對開發人員來說,能夠禁止底層的操作細節,使之更專注於上層套用開發。
訪問方法比較
使用ODQ對流式文檔進行訪問,與前3種訪問方式進行比較,其優越性體現如下:
(1)針對流式文檔,禁止文檔格式和版本的差異,為用戶提供統一的訪問接口,達到了格式無關性;
(2)ODQ具有類似SQL的語法結構,符合用戶使用習慣,代碼簡潔,開發人員無需花費過多時間去學習複雜的查詢語言,只需發出“做什麼”的命令,而不用考慮“怎么做”。為操作流式辦公文檔帶來了很大的方便。
(3)查詢粒度方面,與前3種訪問方式做比較,如表1所示。因為需要的是通用文檔操作功能,不是進行細粒度的訪問,並不需要深入了解文檔內部結構,在這方面,可以體現出ODQ和API的優越性。
(4)將在基於B/S結構的web套用中,ODQ封裝進協定中,大部分內容放在伺服器端,對於客戶端來說,不會耗用很大記憶體,可以較為快速地提取所需信息;
(5)在web套用方面,文獻中對0DQ的返回值形式進行了扁平化研究,可以將訪問結果以更容易的方式進行網路傳輸並解析。
綜合上述分析,這裡給出4種流式文檔訪問方式在代碼精簡度、查詢粒度、對不同格式流式文檔問互操作能力支持以及操作簡便性的比較,見表1。
 4種訪問方式比較
4種訪問方式比較