
背景
隨著計算機及其相關技術的發展,在最近幾年出現了大量以數據流為信息承載模式的套用系統,這些數據流一般都具有實時性、連續性、順序性以及數據量龐大等特點,使用傳統的資料庫管理系統已經不能滿足數據流處理的要求。各種適應於不同套用的系統緊隨其後不斷湧現,目前主要的數據流管理系統(DSMS)項目有STREAM(Stanford),Aurora(Brandeis/Brown/MIT),Telegraph(Berkeley),Gigascope(AT&T), Niagara (OGI/Wisconsin ),Tribeca(Bellcore)。
系統模型
數據流管理系統所處理的數據流是一種實時連續的數據信息序列,而且在實際處理過程中,這種數據序列具有信息到達順序不可控、單位時間數據到達量不均勻、數據量龐大等特點。這些特點要求DSMS 應當具有以下的功能:
(1)在一定的時間內,對信息能夠進行重組並處理;
(2)由於物理存儲空間的限制和處理效率的要求,對數據流進行線上處理時,一般只掃描數據一遍;
(3)一般不採用阻塞方式處理數據流,以保證數據處理的效率;
(4)能對數據進行提煉,並採取隨機和/或有選擇地丟包等減負措施,保證在突發流量情況下系統的整體性能;
(5)對異常的數據有足夠迅速(接近於實時)的反應能力。
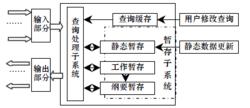 數據流管理系統的概要結構模型
數據流管理系統的概要結構模型圖 1 描述了DSMS 的一般功能結構,用於支持長期運行,連續的、標準的、持久的查詢。主要由3 部分組成:輸入部分,處理部分和輸出部分。輸入部分主要對輸入的數據流進行初步的過濾,併兼有應付突發流量的基本功能(譬如在系統沒有足夠資源處理突發數據流時進行負載脫落)。處理部分是整個系統的主幹,由3 部分組成:(1)暫存子系統,數據分為3 部分暫存:靜態暫存部分存儲元數據(例如DSMS 各部分的物理位置等),允許用戶自定義相關的設定;工作暫存部分存儲當前處理的數據流,如果遇到突發流量而沒有足夠的物理存儲空間, 可以對數據進行歸納, 將獲得的綱要(Synposes)或摘要存儲在綱要暫存中;(2)查詢快取,主要存儲用戶定義的查詢條件,一般的DSMS 系統支持用戶線上修改查詢條件;(3)查詢處理子系統,主要功能是從查詢快取中提取用戶定義的查詢,根據最佳化需求對其進行分組,並將其作用於從輸入部分獲得的數據流。查詢處理子系統還具有自適應功能,能根據當前數據流量和查詢條件調整系統查詢策略。輸出部分主要的功能是保證處理所得的結果(數據流或/和關係型數據項)能夠平穩地輸出,一般都包含臨時存儲的功能。
數據流預處理模型
由於數據流只出現1 次並且具有一定順序性的特點,一般在處理數據流時,DSMS 將數據流劃分為若干數據單元,根據DSMS 處理這些數據單元所採用的不同模型將數據流單元分別存儲到一系列順序的元素列表。針對連續數據流的非阻塞方式處理,一般DSMS 實驗系統都採用視窗技術。視窗是一種從不受限制的數據流轉化為一系列可控的受限數據單元的機制。按現有數據流管理系統使用視窗技術處理數據流的方式,可將視窗機制分3 類。
(1)採用基於順序視窗機制的數據流都存在可以唯一標記流元素到達順序的屬性,現有系統一般都採用到達時間作為衡量標準。這些系統通過顯性或隱性的方式以一定的時間間隔給到達的數據流單元打上時間戳(timestamps),根據時間戳從數據流中提取數據單元進行分析。C.Cranor, Y.Gao et al. [2]介紹的面向網路數據流監測的Gigascope 系統。L.Golab, M.T.Ozsu[1]把這種視窗機制稱為基於物理分類的視窗機制。
(2)基於單元數量的機制將到達的數據流被看作由一系列元組(tuple)組成佇列(例如在網路監測中將數據流中的每個包作為一個元組處理),套用數據流處理系統自定義的規則暫存到達的元組,並對其進行處理。Telegraph將到達的元組分類存儲在數據狀態模組(Data SteMs),與查詢狀態模組(Query SteMs)進行一系列相關操作獲得結果並以數據流的形式輸出。
(3)基於標記的機制:標記是確定連續流中一部分結束的記號,從而使系統可以將一條沒有限制的流看成是若干受限流的組合。在具體套用中,標記被作為一個控制包嵌入到輸入的數據流中,數據流操作單元通過讀取標記獲得操作和控制數據流的信息。使用標記技術的數據流處理項目主要包括Aurora,STREAM,Tribeca,Niagara,Hancock等。
在目前 DSMS 系統中,這幾種視窗機制是一般都是結合使用的,已達到不同階段採用相對更有效處理方式的目的,如STREAM 中就包含這3 種類型的視窗機制。
數據流查詢語言
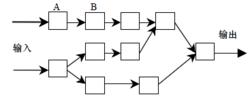 DSMS查詢操作過程示意圖
DSMS查詢操作過程示意圖在 DSMS 中,連續查詢可以被分解為運算元(operator)的集合,例如project,select,join 等,這些運算元在傳統的DBMS 中也作了相關定義,其區別主要集中在DSMS 如何使運算元能夠在非阻塞的模式下運行,這個問題可以使用視窗技術解決,如圖2。
數據流查詢操作的 整個過 程可以使用 單 向 無 環 圖(DAG)來表示,其中每個點表示一個管道(pipelined)運算元,有向的邊表示連線兩個運算元的佇列(例如,經過運算元A處理的數據流通過緩衝寫入佇列AB 成為運算元B 的輸入流)。
最佳化策略
數據流處理過程中需要解決的問題很多,其中比較典型的有兩個:突發流量不確定性和近乎實時處理的性能需求。需要採取必要的措施進行協調。
進度安排
進度安排是一種積極的最佳化策略,是影響系統的整體性能最關鍵的因素之一。在實施過程中,系統為達到各種性能指標的要求會發生衝突(例如較小的相應時間必然要求較大的記憶體),所以對實際系統而言,尋找各種指標的平衡至關重要。具體的DSMS 會根據數據流的特點和需達到的目的,以部分犧牲其它性能為代價,選取其中的一個或一部分性能作為主要衡量指標。
負載脫落
當突發流量超過系統的處理能力,如果不採取相應的措施,會導致整個系統的吞吐量和回響時間都惡化。負載脫落通過丟棄一定數量的數據,在部分犧牲準確性和完整性的條件下,保證系統的性能。負載脫落算法可以根據採用的處理方式分為以下兩種:隨機的負載脫落算法和基於語義的負載脫落算法。
隨機負載脫落是指在發現數據輸入超出系統處理能力時,通過按一定的比重隨機丟棄部分元組保證系統的正常運行。基於語義的負載脫落,通過用戶對流處理語義的理解,有選擇地丟棄一部分元組,使元組損失對系統性能和輸出結果的影響最小化。目前普遍採用的負載脫落算法一般是基於語義的。基於語義的負載脫落算法與系統的上下文有關,主要考慮的問題是:何時,何地以及如何進行。
近似值計算
當系統性能滿足數據流處理的要求時,處理結果可以正常輸出。但如果處理要求超出系統的處理能力時,如突發流量、處理數據流所需記憶體超出物理記憶體等,可能導致系統總體性能下降甚至出錯。DSMS 採用計算近似值的方法,通過發現處理數據流的相似性,將其進行歸類處理,在部分犧牲精確性的條件下獲得處理時間的減少和存儲空間上的節省。
近似值計算是 DSMS 中重要的數據處理方式,所採用的算法根據具體方法的不同分為計數(Counting) 、哈希(Hashing)、抽樣(Sampling)、概要(Sketches)、直方圖(Histograms)和小波(Wavelets)等。
未來研究方向
雖然數據流管理系統在不同領域數據流處理中得到了廣泛的套用,但是由於其在總體上尚處於起步階段,而數據流處理本身需求有多種形式且複雜程度呈迅速上升趨勢,因此數據流管理系統在許多方面有待提高,主要集中在以下:
(1)數據流管理系統的統一接口問題
目前相關研究機構出於各自研究的需要,都自定義了一系列自己的DSMS 接口規範,而沒有考慮不同DSMS 之間的互聯和共享。由於所需處理問題的複雜化和各個研究機構之間協作的增加,和傳統的DBMS 類似,定義統一訪問接口勢在必行。
(2)數據流處理最佳化策略
由於所需處理數據的量和數據處理的複雜程度增長的速度要遠遠超過硬體處理能力的增長速度,而且現有數據流處理最佳化策略還不能很好地滿足相關要求,因此有必要進一步改進和發展流處理最佳化策略。首先針對進度安排,問題主要集中在回響時間和記憶體占用之間能否找到一個平衡點,並且平衡點是可變的,始終契合具體的套用需求;負載脫落算法主要考慮如何跟語義更緊密地結合,從而使其代價最小化;近似值計算目前主要發展方向是多種處理方法的結合使用,具體方法的選擇應當較好地考慮其使用範圍和具體套用。
(3)數據流管理系統如何在整體性能方面超過針對套用的專業工具
數據流管理系統相對於一般針對具體套用的專業工具主要的優點在於其適應能力和通用性,用戶可以根據具體的需要通過定義不同的接口來獲得不同的測試結果,但這是以犧牲一定的處理性能為代價的。如何通過技術的改進在整體性能方面超過一般專用的工具;或者通過為一般工具提供接口的方式和專用工具結合使用,以達到更高的處理能力和更好的處理效果,這是DSMS 發展所需解決的一個問題。
數據流管理系統在借鑑傳統資料庫的基礎上提出了時間戳、視窗機制、連續查詢、最佳化策略等方法,用於線上分析連續數據流。在現有DSMS 中這些技術得到了廣泛的套用和發展,但是由於硬體性能增長速度要遠遠落後於數據流處理需求的增長速度,因此有必要在系統結構和最佳化算法等諸多方面促進DSMS 的發展。
