例子
 圖1
圖1舉個簡單的例子:莎士比亞的哪部劇本包含Brutus及Caesar 但是不包含Calpurnia?布爾表達式為:Brutus AND Caesar AND NOTCalpurnia。最笨的方法是線性掃描的方式:從頭到尾掃描所有劇本,對每部劇本判斷它是否包含Brutus和Caesar ,同時又不包含Calpurnia。這個方法缺點如下:速度超慢(特別是大型文檔集)、處理NOT Calpurnia 並不容易(一旦包含即可停止判斷)、不太容易支持其他操作(例如find the word Romans nearcountrymen)、不支持檢索結果的排序(即只返回較好的結果)。
一種非線性掃描的方式是事先給文檔建立索引(index),假定我們對每篇文檔(這裡是劇本)都事先記錄它是否包含詞表中的某個詞,結果就會得到一個由布爾值構成的詞項—文檔關聯矩陣,如圖1。
為回響查詢Brutus AND Caesar AND NOTCalpurnia,我們分別取出Brutus、Caesar及Calpumia 對應的行向量,並對 Calpumia對應的向量求反,然後進行基於位的與操作,得到:
110100 AND110111 AND 101111 = 100100
結果向量中的第1和第4個元素為1,這表明該查詢對應的劇本是Antonyand Cleopatra和Hamlet。檢索效果的評價標準一般為正確率和召回率。正確率(Precision)表示返回結果文檔中正確的比例,如返回80篇文檔,其中20 篇相關,正確率1/4;召回率(Recall)表示全部相關文檔中被返回的比例,如返回80篇文檔,其中20 篇相關,但是總的應該相關的文檔是100篇,召回率1/5。正確率和召回率反映檢索效果的兩個方面,缺一不可。全部返回,正確率低,召回率100%,只返回一個非常可靠的結果,正確率100%,召回率低。因此引入了F度量,如下:
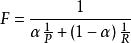 布爾查詢
布爾查詢回到剛才的例子,我們顯然不能再採用原來的方式來建立和存儲一個詞項—文檔矩陣,假定N = 1百萬篇文檔(1M), 每篇有1000個詞(1K),每個詞平均有6 個位元組( 包括空格和標點符號),那么所有文檔將約占6GB 空間,假定辭彙表的大小( 即詞項個數)為50萬,即500K,則詞項—文檔矩陣=500K x 1M=500G。我們可以對上述例子做個粗略計算,由於每篇文檔的平均長度是1000個單詞,所以100萬篇文檔在詞項—文檔矩陣中最多對應10億(1 000×1 000 000 )個1,也就是在詞項—文檔矩陣中至少有99.8%(1 - 10億/5000億)的元素為0。很顯然,只記錄原始矩陣中1 的位置的表示方法比詞項—文檔矩陣更好。
查詢最佳化
 圖2
圖2查詢最佳化(query optimization )指的是如何通過組織查詢的處理過程來使處理工作量最小。對布爾查詢進行最佳化要考慮的一個主要因素是倒排記錄表的訪問順序。一個啟發式的想法是,按照詞項的文檔頻率(也就是倒排記錄表的長度)從小到大依次進行處理,如果我們先合併兩個最短的倒排記錄表,那么所有中間結果的大小都不會超過最短的倒排記錄表,這樣處理所需要的工作量很可能最少。如圖2,就是先計算兩個短的倒排記錄表的and運算 。
對於任意的布爾查詢,我們必須計算並臨時保存中間表達式的結果。但是,在很多情況下,不論是由於查詢語言本身的性質所決定,還是僅僅由於這是用戶所提交的最普遍的查詢類型,查詢往往是由純“與” 操作構成的。在這種情況下,不是將倒排記錄表合併看成兩個輸入加一個不同輸出的函式,而是將每個返回的倒排記錄表和當前記憶體中的中間結果進行合併,這樣做的效率更高而最初的中間結果中可以調入最小文檔頻率的詞項所對應的倒排記錄表。該合併算法是不對稱的:中間結果表在記憶體中而需要與之合併的倒排記錄表往往要從磁碟中讀取。此外,中間結果表的長度至多和倒排記錄表一樣長,在很多情況下,它可能會短一個甚至多個數量級。在倒排記錄表的長度相差很大的情況下,就可以使用一些策略來加速合併過程。對於中間結果表,合併算法可以就地對失效元素進行破壞性修改或者只添加標記。或者,通過在長倒排記錄表中對中間結果表中的每個元素進行二分查找也可以實現合併。另外一種可能是將長倒排記錄表用哈希方式存儲,這樣對中間結果表的每個元素,就可以通過常數時間而不是線性或者對數時間來實現查找。
