
定義
布爾檢索模型是最早也是最簡單的一種檢索模型,它採用布爾代數的方法,用布爾表達式表示用戶檢索提問,通過對文獻標識與提問式的邏輯比較來檢索文獻。該模型的優點是簡單、易理解、易實現並能處理結構化提問。存在的缺陷主要表現在:①布爾邏輯式的構造不易全面反映用戶的需求;②匹配標準存在某些不合理的地方;③檢索結果不能按照用戶定義的重要性排序輸拄;;④易造成零輸出或輸出過量;⑤對用戶的素質有很高的要求。
為了克服上述缺陷,沃勒(Waller)和克那夫(Kraft)在1979年提出了加權布爾檢索模型(Weighted Boolean Retrieval.odel’),該模型通過對標引詞進行加權來解決檢索結果的排序、檢索詞的重要程度的區分等問題,但布爾操作算符的一一些算法規律(如交換律、結合律)也因此不再成立;Sallon在1983年提出了擴展布爾檢索模型(Extended Boolean RetrievalModel),該模型在保持布爾檢索的結構式提問的同時,也吸取了模糊模型和向量空間模型的長處,巧妙地引入了一個模型參數P,通過適當調節此參數,Sahon模型可以分別表現為布爾模型、向量空聞模型和模糊模型。
基本理論
權值的意義
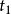 加權布爾檢索
加權布爾檢索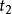 加權布爾檢索
加權布爾檢索 加權布爾檢索
加權布爾檢索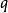 加權布爾檢索
加權布爾檢索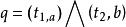 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索
加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索
加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索為了對權的概念形成一個統一的、合理的認識。設目標引詞、及邏輯算符構成查詢:,其中a、b分別是,在中的權值。當權值減小時,我們可以理解為標引詞在查詢中的重要性減小,相對來說,標引詞在查詢中的重要性就增大;同樣,當權值增大時,我們可以理解為標引詞在查詢中的重要性增大,而相對來說,標引詞在查詢口中的重要性就減小。
加權布爾檢索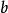 加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索
加權布爾檢索 加權布爾檢索 加權布爾檢索 加權布爾檢索從這種意義上講,權值和是標引詞,在查詢中的重要性的一種量度。
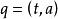 加權布爾檢索 加權布爾檢索 加權布爾檢索
加權布爾檢索 加權布爾檢索 加權布爾檢索但是,如果拿這個觀點來定義查詢標引詞的權值意義,將會給我們以後的研究帶來麻煩。比如對查詢來說,因為只有一個標引詞,所以該標引詞在查詢中的重要程度是難以用其權值來衡量的。即使我們人為地規定了一些標準使得任何查詢標引詞的權值都有意義,那么,因為查詢標引詞的權值和文獻標引詞的權值的意義不同,仍然會使我們在設計檢索模型時遇到困難。
所以我們應該這樣來定義查詢標引詞的權值的意義:查詢標引詞的權值和文獻標引詞的權值具有相同的意義,即一個查詢標引詞的權值是用來表明用戶期望檢出文獻論述該標引詞的程度的。
模型基本原則
1)當文獻標引詞與查詢標引詞的權值為1,0時,加權系統應退化為傳統布爾檢索系統;
2)邏輯上等價的加權查詢應檢索出相同的文獻集;
3)遵循可分性原則,
4)檢索狀態值應隨文獻標引詞權值的增大而增大;
5)檢索狀態值應隨查詢標引詞取值的增大而不減小;
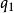 加權布爾檢索
加權布爾檢索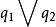 加權布爾檢索
加權布爾檢索 加權布爾檢索
加權布爾檢索6)查詢關於任一文獻的檢索狀態值應不大於查詢的檢索狀態值,不小於查詢的檢索狀態值。
