
簡介
學習矢量量化是一種結構簡單、功能強大的有監督式神經網路分類方法。該算法自1988年由Kohonen提出以來,己經成功套用到統計學、模式識別、機器學習等多個領域。作為一種最近鄰原型分類器,LVQ在訓練過程中通過對神經元權向量(原型)的不斷更新,對其學習率的不斷調整,能夠使不同類別權向量之間的邊界逐步收斂至貝葉斯分類邊界。算法中,對獲勝神經元(最近鄰權向量)的選取是通過計算輸入樣本和權向量之間歐氏距離的大小來判斷的。 與矢量量化(VQ)相比, LVQ 最突出的優點是其具有自適應性,它可以通過線上學習的方式獲得訓練樣本的碼本。
分類
根據訓練樣本是否有監督,LVQ 可分為兩種:一種是有監督學習矢量量化,如 LVQ1、LVQ2.1 和 LVQ3,它是對有類別屬性的樣本進行聚類;另一種是無監督學習矢量量化,如序貫硬 C-均值,它是對無類別屬性的樣本進行聚類。
結構
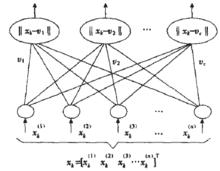 圖1 LVQ的結構圖
圖1 LVQ的結構圖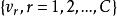 學習矢量量化
學習矢量量化圖 1 描述了 LVQ 神經網路模型,LVQ 神經網路的輸入層是直接連線到輸出層,在輸出層的每個節點有一個權值向量( 碼本) 同它連線( 見圖 1) ,學習的目的就是尋找權值即碼本 的最優值。
LVQ算法
LVQ算法是一種有監督的自組織神經網路算法,是無監督的自組織神經網路算法(SOMF)的擴展,其基本思想是利用少量權向量來表示數據的拓撲結構。與無監督的自組織神經網路算法相比,由於在權向量更新過程中引入了監督信號,LVQ算法在模式識別領域具有更廣泛的套用。
LVQ1
LVQ訓練過程的具體步驟如下:
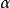 學習矢量量化
學習矢量量化(1)對於一個N維的輸入樣本,初始化權向量w及學習率 ,並給定最大疊代次數T。
(2)判斷是否滿足疊代停止條件:是,則停止疊代;否,則繼續以下步驟。
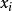 學習矢量量化
學習矢量量化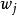 學習矢量量化
學習矢量量化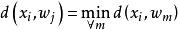 學習矢量量化
學習矢量量化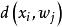 學習矢量量化
學習矢量量化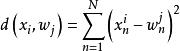 學習矢量量化
學習矢量量化(3)尋找輸入樣本 的最近鄰 ,滿足: 。 通常選用歐氏距離的平方,其計算公式為: 。
學習矢量量化(4)對獲勝神經元的權向量 進行更新:
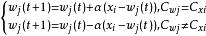 學習矢量量化
學習矢量量化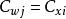 學習矢量量化
學習矢量量化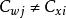 學習矢量量化
學習矢量量化其中,t 為疊代的次數, 表示輸入樣本與獲勝神經元同類, 表示輸入樣本與獲勝神經元異類。
(5)返回步驟(2)。
LVQ2.1
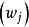 學習矢量量化
學習矢量量化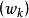 學習矢量量化
學習矢量量化每一次疊代過程只能對一個權向量進行更新,這是LVQ1算法的一個局限。因此,在改進的LVQ2.1算法中,提出同時更新兩個權向量的方法。尋找輸入樣本最近鄰的兩個權向量,若這兩個權向量一個與輸入樣本同類 ,而另一個與輸入樣本異類 ,同時更新兩個權向量:(式1)
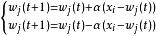 學習矢量量化
學習矢量量化儘管 TVQ2.1可以同時更新兩個權向量,較TVQ1性能優越,但是仍然存在著不足之處:
(1)在訓練過程中與輸入樣本異類的權向量可能不收斂。雖然(式1)同時調整輸入樣本最鄰近的兩個權向量( 一個與輸入樣本同類,一個與輸入樣本異類) ,使他們之間的邊界向最優貝葉斯邊界靠近,但是算法又對異類權向量一直進行遠離輸入樣本的調整,卻沒有考慮其最終的位置,這樣會導致該權向量的不收斂.
(2)LVQ算法未體現出數據各維屬性在分類過程中重要程度的不同,這一問題的原因要歸咎於歐氏距離的計算公式。 歐氏距離計算公式是基於數據各維屬性重要程度相同這樣一種假設,然而,這種假設忽視了這樣一個事實,即數據各維屬性對分類所做"貢獻”的程度可能會不同。換句話說,對於某一輸入樣本而言,它的全部屬性中的一部分可能對分類是非常重要的,是重要屬性;相反,其它的屬性對分類的作用可能是次要的,甚至會干擾正確的分類,是次要屬性。對這種情況而言,用歐氏距離進行分類顯然不夠準確,而且實際數據大部分都屬於這種情況。因此,如何發現並強調這些重要屬性同時忽略那些次要屬性成為能否準確對數據進行分類的關鍵。
LVQ的不足
雖然傳統LVQ算法性能優越且套用廣泛,但是仍存在著一些不足:
1)訓練過程中權向量可能不收斂。原因是由於在尋找最優貝葉斯邊界時,對權向量更新的趨勢沒有給予充分的考慮
2)對輸入樣本各維屬性的信息利用不充分,沒有體現出各維屬性在分類過程中重要程度的不同。原因是由於在尋找獲勝神經元過程中採用的歐氏距離度量方法,沒有考慮到輸入樣本各維屬性重要度差異,即假定各維屬性對分類的“貢獻”是相同的。
