
簡介
增量編譯技術的研究始於上世紀60年代末70年代初,並在80年代獲得了大量的研究,使得增量編譯理論得到了進一步的成熟。
增量編譯技術,顧名思義,是在源程式已經完成第一次編譯的基礎上再次編譯時採取的一種增量性編譯技術。增量編譯技術可以減少源程式再次編譯的時間,這對於源程式只作了微小的改動,而要求再次編譯時是非常有利的,它不僅可以提高軟體開發的效率,還可以提高軟體測試人員的效率。目前,增量技術已經廣泛的運用於許多商用的集成開發環境當中。要實現增量編譯技術,當然就需要對源程式第一次編譯的結果進行有選擇的保存,當對源程式再次編譯時,可以在第一次編譯的基礎上進行增量計算,以實現增量編譯。
增量編譯程式建立在語法制導編輯器的基礎之上,是語言集成化環境的重要組成部分。它對用戶源程式局部修改後進行的重新編譯的工作只限於修改的部分及相關部分的內容。相關部分的確定由系統完成,對用戶是透明的。增量編譯器的這種局部編譯,對軟體開發,尤其是在調試期,無疑會大大縮短編譯時間,提高編譯效率。
和傳統編譯器把多次輸入的用戶源程式都作為孤立對象相比,增量編譯器保留了用戶源程式的某些“歷史”知識,所以報適合於集成化環境。同時,增量編譯器還支持抽象級別上的程式設計方法學,為用戶的編程和調試提供方便。
增量編譯方法
目前,實現增量編譯技術一般有三種方法:
第一種方法是首先確定編譯的最小單元,當源程式修改後,以編譯單元對源程式進行增量編譯。
第二種方法是基於語法制導編輯技術,首先必須開發出語法制導編輯器,其中語法制導編輯器除了是用戶輸入源程式的接口,而且還動態維持著源程式的中間表示形式,一般是抽象語法樹形式。當源程式發生修改,語法制導編輯器遍歷抽象語法樹,同時調用預先設計實現的例程,根據源程式所作的修改來完成所需的增量計算,主要是語法樹的局部調整,以實現增量編譯。
第三種方法是採用屬性文法的實現方式,屬性文法描述了源程式的語義,從屬性文法的定義中,可以計算出語言屬性之間的依賴關係,當源程式發生修改時,從屬性文法中可以計算出源程式中需要重新編譯的最小編譯單元,以實現增量編譯的目的。
基於最小編譯單元
該方法是最易於實現的一種方法,基本思想是:首先確定編譯的最小單元,當程式發生改變時,以最小編譯單元提取源程式代碼,並對提取的代碼進行增量編譯。比如:對於以行為編輯單位的語言,如BASIC或Fortran語言,最小編譯單元可以細到語句級別;而像過程式語言如C,Pascal,Smalltalk,最小編譯單元可是過程或函式。當然還存在一些更為複雜的語言,其定義體間的交叉引用關係過於複雜,一條語句或一個定義的改變,可能導致程式許多地方需要重新編譯,對於這種程式語言,對其實現增量編譯有可能是無意義的。
該方法的另一個特點是具體實現方法的多樣性,所以,該方法可以緊密的結合目標語言的語言特性,充分利用目標語言自身的特點,開發出適合該語言的增量編譯方法。目前,該方法一般通過對編譯的結果進行轉儲的方式來實現,最常見的是將其保存在外部存儲器上,在下次編譯時在將其調入記憶體。具體實現時,主要是對源程式編譯後的中間表示形式進行保存,目前程式的中間表示形式大都是抽象語法樹形式,所以就需要對整個語法樹進行編碼,壓縮,並將其保存在外部檔案中,當再次對源程式進行編譯時;把外部檔案的記憶體讀入記憶體,恢復上一次編譯時的語法樹形式,並在此基礎上實現增量編譯。該方法的實現有一個關鍵就是語法樹向外部檔案轉儲的格式轉換問題,如何對抽象語法樹進行高效的編碼,壓縮並將其保存在外部磁碟上是該方法的一個關鍵點,也是難點,而且由於該方法存在大量的I/O操作,會嚴重影響編譯的效率。由於以上所提到的原因,導致該方法並未在實際中得到大量的使用。
另一種實現方法也是對源程式的某種形式進行轉儲,但並不是對源程式編譯後的中間表示形式進行保存,而是對源程式文本的結構信息進行保存。這主要是通過對源程式增加一遍掃描來實現的,增加的掃描過程並不涉及到對源程式語法,語義的理解,而是對源程式的文本結構進行記錄,並通過外部檔案的形式將其進行轉儲。當需要對源程式進行再次編譯時,先對該程式完成一遍文本掃描過程,然後將掃描的結果與在外部檔案中保存的數據進行比對,以此來標記源程式中發生修改的編譯單元。此外,該方法所保存的數據要比保存源程式的中間表示形式要小很多,所以I/O操作的效率也較高。
基於語法制導編輯
基於語法制導編輯器的實現方法是目前實現增量編譯的一般性方法,也為目前大多數的系統所採用,其中比較具有代表性的有ALOEEdito以及Gandalf項目。
該方法的基本思想是:語法制導編輯器負責調用編譯器對輸入的源程式進行編譯,並維護源程式的中間表示形式,抽象語法樹;所有的編輯操作除了一般意義上的文本操作外,其實都是對抽象語法樹節點的操作;通過預先編寫好的基於特定文法的諸多例程,當對源程式進行編輯的同時,語法制導編輯器遍歷語法樹,調用預先編寫好的例程對語法樹進行必要的操作以反映目前對源程式所作的修改。該方法打破了傳統的“先編輯,後編譯’’的方法,而且在編輯的同時也對源程式進行編譯,並對語法樹進行增量計算。該方法是以語法制導編輯器為基礎,所以也稱為基於語法制導編輯技術的增量編譯方法。
語法制導編輯,顧名思義,就是整個程式的編輯是在語言語法的約束下完成的,語法制導編輯是在語法制導編輯器的引導下完成。語法制導編輯器的另一個重要任務就是要在源程式編輯的同時調用相應的語法分析器來對剛剛編輯的程式單位進行語法分析,語法分析器應當實現增量的功能,這樣當程式修改後,語法分析只對程式中修改的部分進行語法分析,這樣可以大大提高語法分析的效率,也可作為實現增量編譯的基礎。
語法制導編輯技術的研究開展於七十年代,在這之後取得了長足的進步。其中,由美國Comell大學開發的CPS系統是其中的代表之作。CPS採用的是模板驅動的方式,模板是預先定義好的,通過模板的展開來引導程式設計師自頂向下來開發程式。而在程式的內部表示中,模板則對應於語法中的非終結符。在國內,由中國科學院軟體研究所研製的C語言結構編輯器也是基於模板驅動實現的,是結構編輯器的經典之作。
 while循環結構的模板展開
while循環結構的模板展開具體來說,模板由關鍵字,特殊符號和占位符構成,一個典型的模板展開形式如下圖所示:
模板驅動的方式提供了一種有助於輸入語法正確的源程式的方法,整個程式的輸入是按照自頂向下通過一系列模板的展開而完成的。在CPS系統所描述的結構編輯技術中,對游標的位置作了嚴格的規定。在圖的模板展開中,游標只能停留在占位符的下面,每次游標的移動實際上都是對程式內部表示的語法樹節點進行操作,在這種基於結構編輯的實現方式下,編輯命令的實現過於複雜,更重要的是喪失了程式編輯的靈活性,而程式編輯的靈活性往往是大多數程式設計師所希望的。
屬性文法
屬性文法存在許多缺點:首先,屬性文法定義了源語言語義的低級表示形式,而且還必須為源語言制定出適合增量計算的屬性文法,而這一點本身並不容易做到,況且,對於有些語言,甚至很難制定出這樣的文法;其次,該方法必須在語法樹節點中保存大量的狀態信息,否則一個變數聲明的改變就有可能導致程式中大部分需要重新編譯,所以該方法的實現要求對原有編譯器的語法樹結構及其符號表進行重新的設計,這顯然不利於整個系統的設計與實現。
編譯程式工作流程
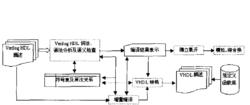 編譯程式工作流程
編譯程式工作流程編譯程式的輸入Verilog(標準硬體描述語言)設計源描述了詞法分析和語法分析採用一遍掃描的策略。詞法和語法分析程式使用Unix系統提供的詞法、語法自動生成工具Lex和YACC生成。與編譯有關的編譯指令在詞法分析部分予以處理,其它與模擬有關的編譯指令保存在編譯結果之中由模擬器處理。
在編譯器的構成中,增量編譯部分的作用是利用已經建立的符號表和設計層次信息對修改模組及其影響到的模組重新編譯,在編譯後更新符號表、、蹬計層次關係和編譯結果,並可調用VHDI,轉換程式對重新編譯的模組實行轉換(轉換以模組——實體/結構體對為單位)。
對應於Vefilog設計組成和增量編譯的需要,編譯結果和符號表都採取層次化的組織方式。頂層都是模組類對象鍊表。符號表內部分類記錄了各種標識符的屬性,按標識符的作用域進行組織,以提高查找的效率。
編譯程式中的各項功能都是建立在符號表和設計層次關係的基礎上。為了實現增量編譯,將通常在確立階段進行的設計層次信息提取提前到語法分析和語義檢查中完成。這樣做除了可以實現增量編譯之外,還有利於VHDL轉換程式的工作:VHDI中被側示的實體/結構體必須首先聲明,而Vefilog則沒有這個要求,因此在轉換時要根據設計層次關係從最低層的模組開始進行轉換。
未來發展趨勢
增量編譯技術的目的是提高開發人員與測試人員的工作效率,但是增量編譯技術也只能提高源程式二次編譯的效率,並不能解決源程式首次編譯的效率。展望下一步的工作主要有以下兩個方面:一是對翻譯檔案的格式作進一步的最佳化,由於目前的翻譯方案中存在有翻譯代碼過大的問題,該問題在整個系統實現中仍然還沒有得到有效的解決,導致該系統在實際的工業測試中仍然存在著一定的缺陷,由於開放的編譯環境,如:微軟的Phoenix編譯器的出現,定義一種更低級,高效,更易於最佳化的中間表示形式已成為可能,比如:三地址碼格式,而且該中間表示形式更貼近機器語言,從而省去了由於翻譯為C++檔案而導致的對C++檔案的編譯過程,能夠從根本上提高整個系統的執行效率,提高系統的可用性;二是通用的增量編譯環境的開發,目前絕大多數的增量編譯技術都是在語法制導編輯器的基礎上實現的,雖然語法制導編輯技術存在靈活性上的缺陷,但是隨著結構編輯技術的發展,該技術目前已在商用集成開發環境中有限的採用,所以開發基於語法制導編輯技術的增量編譯器仍具有實際意義,而且基於語法制導編輯技術的增量編譯方法由於在編輯的同時即對源程式進行編譯從而更能發揮目前多核,多執行緒計算的優點。
另外,從長遠的角度考慮,由於分散式技術以及網際網路套用的進一步發展,構建一個支持分散式套用的測試系統是非常必要的,這仍然需要我們對基於編譯執行的技術方案作進一步的改進與完善,這些都是值得嘗試的研究方向。
