公司簡介
成立於2009年的吉浦迅科技是中國首家專注於GPU異構高性能套用的科技企業,不僅為眾多科研單位提供最完整的GPU高性能開發平台與集群系統,同時也是最早引進最先進OpenACC異構編程標準的廠商,協助科研院所、重點高校、研究單位、金融企業,能快速開發與移植GPU異構套用系統。吉浦迅科技自主研發“結合GPU性能與VDI套用”的SuperVDITM技術,也於2012年獲得政府“領軍孵化企業”殊榮,將GPU從視覺、高性能、遊戲等傳統套用破繭而出,開啟企業商用的套用範疇,為VDI雲桌面技術提供支持3D套用環境(如CATIA、SolidWorks、AutoCAD等),將GPU套用開創更寬廣的格局。
發展里程碑
2012年4月,結合GPU高性能特性與“桌面雲(VDI)”而成的SuperVDI,是國內首套支持三維(3D)設計環境的桌面雲方案,廣泛滿足工業三維設計(包括汽車、航空、造船、工程、機械、建設、家具、裝修....等)以及文創三維設計(包括動漫製作、影視後製作...等)套用需求,以及對於“數據安全”有高度要求單位(包括軍工、政府、設計院、律師會計師事務所、銀行/保險/電信櫃檯、廣告創意、設計外包....等)的需求。2012年1月,成為全球領先的高性能計算(HPC)編譯器提供商Portland Group中國區代理,全線代理其PGI加速編譯器產品。該產品可以迅速幫助現有C/C++/Fortran編程開發人員將現有可並行套用移植到GPU上。 Porland Group為意法半導體全資子公司。
2011年12月,入選NVIDIA中國區GTD戰略夥伴,共同成立“GPU超算實驗室”,投資建立國內最先進的GPU超算平台,計算峰值高達12萬億次(TFLOPs)浮點運算,相當於150台6核CPU電腦計算性能。
2011年12月,推出真正”GPU雲“架構的 VT-GPU 虛擬技術。由吉浦迅創始人兼首席技術官、前任ATI/AMD中國區技術總監Dereck Lin在台灣與交通大學合作成立研發團隊,歷時兩年開發GPU虛擬套用技術,並推出GPU遊戲平台,透過GPU並行運算提升線上遊戲伺服器效能,提高運算效率,並有效降低每一單位運算所需之電力成本(Performance/Watt),取代原本營運所需之數百台伺服器成為單一機櫃,簡化管理和維護。
2011年 8月,推出業界最小的GPU超算系統,並申請兩項相關專利
2011年 5月,成為美國EM photonics公司CULATools線性代數庫加速工具中國區唯一代理。LAPACK是線性代數中常用函式的一個集合,被科學與工程界數以百萬計的開發人員所廣泛使用。而CULAtools作為GPU版本被全球超級計算中心廣泛採用。
2011年 1月,成為ASUS高性能計算中國區唯一戰略合作夥伴,並且針對生命科學、分子動力、流體力學、生物化學等領域,提供完整的GPU加速方案。
2010年10月,獲NVIDIA中國區TPP 2.0資質
2010年 9月,獲美國Acclereyes公司青睞,授權Jacket for Matlab加速軟體中國區代理,成為國內首家提供Matlab數值計算GPU整體解決方案供應商
2010年 4月,率先推出GPU/CUDA網上培訓系統,成為國內首家提供"商業化CUDA培訓"單位,培訓師是受過nVIDIA正規培訓的專業講師
2010年 1月,進入 nVIDIA 中國區 TPP 行列,並獲得nVIDIA亞太區代理商麗台科技(Leadtek)授權
2009年11月,申請“結合GPU套用與石油第三次探勘方案”專利。
公司業務
CPU/GPU異構(hybrid)並行計算套用
自從2003年開始,有人將GPU(圖形處理單元)的多核(multi-core)特性作為並行運算的用途,便在CPU主宰計算機領域裡埋下一顆未爆彈。其後再經過AMD/ATI的OpenCL介面與NVIDIA CUDA架構的推出,使得GPGPU(General Purpose GPU)開發環境日趨成熟,也在國內外科研領域逐漸獲得認可與採用,其主要原因,還在於“以主頻提高性能的CPU”面臨性能提升的瓶頸所導致,使用大量集群(cluster)架構的CPU並行方式,耗費極高的電能、空間、網路設備、數據存儲設備等等極高成本,所產生的效益曲線已不符預期。至於“並行”與“串列”計算的差異,與人的眼睛與耳朵的接收模式非常相似。從右圖
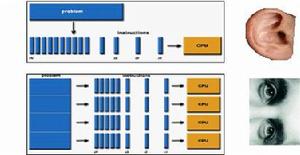
然而,最初用於解決圖形圖像處理的GPU單元,正好就是屬於”並行架構“處理模式:利用多核(multi-core)架構,協助CPU解決大量處理處理與顯示的問題。這一特性恰好在”計算需求爆炸“的21世紀初,被利用來簡易並且快速地提高計算性能達數倍甚至數十倍以上(同樣成本的前提下),透過CPU與GPU相結合的異構(hybrid)模式,其實與”人腦“的工作模式更加接近。
20世紀最重要發現之一,就是權威腦學專家斯佩里對於動物腦部的解剖研究表明,腦有左右之分,其中左腦,被稱為“文字腦”,主要處理文字和數據等抽象信息,具有理解、分析、判斷等抽象思維功能,有理性和邏輯性的特點,所以又稱為“理性腦”;右腦, 被稱為“圖像腦”,處理聲音和圖像等具體信息,具有想像、創意、靈感和超高速反應(超高速記憶和計算)等功能,有感性和直觀的特點,所以又稱“感性腦”。
CPU/GPU異構計算模式,就如同左右腦搭配使用的方式極為相似,偏重左腦(CPU)或偏重右腦(GPU),都會產生不協調或性能不佳的現象,必須雙劍合璧、各司所職便能發揮非常大的效能。所以,GPU並非取代CPU的,而是提供更大的能量來提升總體計算性能,同樣的,缺乏CPU的話,GPU也無法獨立運作。二者相得益彰,不可或缺!
異構(hybrid)計算模型與OpenACC開發
許多剛接觸CPU/GPU異構計算模式的開發人員,一開始便急忙從CUDA或OpenCL這些開發指令下手,很快就會碰到學習上的障礙,畢竟CUDA與OpenCL屬於”類Assembly“的底層指令,與硬體架構的關聯性緊密,直接與硬體通訊、下命令、分配記憶體空間、數據搬移、數據同步。。。。,往往令人生畏,讓許多原本鍾情於GPU套用的開發人員產生挫敗感,甚至敬而遠之,形成反效果。其實,簡單分析”異構計算“模型(右圖),

數據傳輸頻寬:在單機系統,主要瓶頸在PCI Bus上,所以這與主機板設計有非常直接的關係。集群架構環境下,則網路頻寬就是很重要關鍵
數據搬移頻率:過度頻繁的數據搬移,絕對會導致計算性能下降,需慎重規劃
計算間斷時間:如果不能讓GPU持續處於峰值計算,經常產生間歇等待狀態,也無法產生有限的性能提升。
基於上述幾點,其實”演算法“的改善,會比”熟悉CUDA/OpenCL程度“更加重要,甚至採用2011年最新制定的OpenACC異構開發標準的工具(如PGI Accelerator編譯器),以及一些商用函式館(如 ArrayFire、CULA等),都能協助開發人員將現有CPU代碼(C或Fortran)快速移植到異構計算架構上,並且得到”一套代碼、跨平台執行“的境界,大幅縮短70%的學習成本與開發周期。
以上OpenACC開發/移植工具、函式館以及相關培訓,都是吉浦迅科技自2013年開始的重點,陸續開展線上的基礎培訓以及進階的實體培訓,更加針對圖形圖像處理(含石油勘探、地質套用、CT重建等)、安防視頻處理、金融分析、數據挖掘等領域,提供專屬的領域套用高階培訓,為GPU套用領域提供更加完整的協助。
