簡介
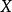 信息瓶頸
信息瓶頸信息瓶頸(英語:information bottleneck)是資訊理論中的一種方法,由納夫塔利·泰斯比、費爾南多·佩雷拉(Fernando C. Pereira)與威廉·比亞萊克於1999年提出 。
對於一隨機變數,假設已知其與觀察變數 Y之間的聯合機率分布p(X,Y)。此時,當需要概括(聚類){\displaystyle X}時,可以通過信息瓶頸方法來分析如何最最佳化地平衡準確度與複雜度(數據壓縮)。該方法的套用還包括分布聚類(distributional clustering)與降維等。
此外,信息瓶頸也被用於分析深度學習的過程。
信息瓶頸方法
信息瓶頸方法中運用了互信息的概念。假設壓縮後的隨機變數為 T,我們試圖用 T代替 X來預測 Y。
此時,可使用以下算法得到最優的T:
 信息瓶頸
信息瓶頸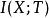 信息瓶頸
信息瓶頸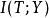 信息瓶頸
信息瓶頸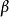 信息瓶頸
信息瓶頸其中 與 分別為X與T之間、以及T與Y之間的互信息,可由 p(X,Y)計算得到。則表示拉格朗日乘數。
信息瓶頸:網路在抽取相關性時的理論邊界
2015年,Tishby和他的學生Noga Zaslavsky假設深度學習是一個信息瓶頸過程,儘可能地壓縮噪聲數據,同時保留數據所代表的信息 。Tishby和Shwartz-Ziv對深度神經網路的新實驗揭示了瓶頸過程如何實際發生的。在一種情況下,研究人員使用小型神經網路,使用隨機梯度下降和BP,經過訓練後,能夠用1或0(也即“是狗”或“不是狗”)標記輸入數據,並給出其282個神經連線隨機初始強度,然後跟蹤了網路在接收3000個樣本輸入數據集後發生了什麼。
實驗中,Tishby和Shwartz-Ziv跟蹤了每層網路保留了多少輸入中的信息和輸出標籤中的信息。結果發現,信息經過逐層傳遞,最終收斂到信息瓶頸的理論邊界:也就是Tishby、Pereira和Bialek在他們1999年論文中推導出的理論界限,代表系統在抽取相關信息時能夠做到的最好的情況。在這個邊界上,網路在沒有犧牲準確預測標籤能力的情況下,儘可能地壓縮輸入。
深度學習中的信息瓶頸問題
信息瓶頸理論認為,網路像把信息從一個瓶頸中擠壓出去一般,去除掉那些含有無關細節的噪音輸入數據,只保留與通用概念(general concept)最相關的特徵。Tishby和他的學生Ravid Shwartz-Ziv的最新實驗,展示了深度學習過程中這種“擠壓”是如何發生的(至少在他們所研究的案例里)。
Tishby的發現在AI研究圈激起了強烈的反向。Google Researc的Alex Alemi說:“我認為信息瓶頸的想法可能在未來深度神經網路的研究中非常重要。”Alemi已經開發了新的近似方法,在大規模深度神經網路中套用信息瓶頸分析。Alemi說,信息瓶頸可能“不僅能夠用於理解為什麼神經網路有用,也是用於構建新目標和新網路架構的理論工具”。
另外一些研究人員則持懷疑態度,認為信息瓶頸理論不能完全解釋深學習的成功。但是,紐約大學的粒子物理學家Kyle Cranmer——他使用機器學習來分析大型強子對撞機的粒子碰撞——表示,一種通用的學習原理(a general principle of learning),“聽上去有些道理”。
深度學習先驅Geoffrey Hinton在看完Tishby的柏林演講後發電子郵件給Tishby。“這簡直太有趣了,”Hinton寫道:“我還得聽上10,000次才能真正理解它,但如今聽一個演講,裡面有真正原創的想法,而且可能解決重大的問題,真是非常罕見了。”
Tishby認為,信息瓶頸是學習的一個基本原則,無論是算法也好,蒼蠅也罷,任何有意識的存在或突發行為的物理學計算,大家最期待的答案——“學習最重要的部分實際上是忘記”。
