串列算法直接並行化
1模擬快速排序
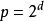 並行排序
並行排序超立方體網路是基於超立方體連線構建的網路。網路中以格雷碼對各頂點編號。在下面的描述中,設頂數,待排序元素共有n個。
 並行排序
並行排序超立方體上的快速排序是這樣進行的:首先我們將n個元素分配到p個處理器上,為了使問題討論簡單化,假設n是p的整數倍,那么每個頂點將會分到個元素。然後隨機選一個主元,各個處理器將每個頂點中的元素按與主元的比較結果分為兩部分。這個算法的關鍵點在這裡,對每一個處理器(頂點)在進行第i次劃分時,將大於主元的部分都送到超立方體的一個d-i維自立方體中,而將小於主元的部分送到另一個d-i位的子立方體中,這樣就模擬了快速排序中的劃分算法。子立方體可以這樣選擇:在第i次劃分中判斷第i位是0還是1。劃分算法到處理完所有1維子立方體後結束。接下來對每個頂點中的元素調用串列算法進行局部排序,最後對整個立方體進行一次遍歷便可得到排好序的元素。
由快速排序的過程,我們可以看到,快速排序實際上就是在構造一棵二叉樹,讓劃分主元位於根節點,使得左子節點小於或等於根而右子節點大於根,最後對整棵二叉樹進行一次中序遍歷,便可以得到最後排好序的數列。
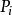 並行排序
並行排序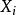 並行排序 並行排序
並行排序 並行排序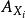 並行排序
並行排序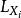 並行排序
並行排序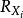 並行排序
並行排序我們可以選n個處理器分別保存待排序數組A的n個元素,處理器對應一個變數用於存放主元元素的處理器號,以及兩個變數L,R分別存放其左右兒子。開始時,每一個處理器都試圖往變數root中寫入它的處理器號,若果我們使用PRAM-CRCW計算模型,那么就只有一個能夠寫入root,接著root被複製給每一個處理器的。然後對於每個處理器(除去被原為主元的那個外)判斷其值與的大小,從而確定放入還是,同樣的,由於並發操作的互斥性,只有一個只能被最終寫入,他們就作為下次劃分的主元。算法繼續進行直到n個主元被選完為止。
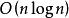 並行排序
並行排序串列算法簡介:快速排序是一種較為高效的排序算法,它通過不斷的劃分待排序列為兩段,使得前一段總小於或等於某個數,而後一段總大於某個數,這樣每次劃分就能確定一個數的最終位置。一般情況下,如果每次劃分的兩個子列大致等長,那么它的時間複雜度是。
2.在PRAM-CRCW計算模型上利用二叉樹網路模擬快速排序
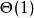 並行排序
並行排序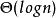 並行排序
並行排序時間複雜度分析:由於一層節點的構造時間是,所以算法的時間複雜度是
二叉樹上模擬快速排序
超立方體上模擬快速排序
比較器網路上的並行排序
比較器網路一般是指由 Batcher比較器構成的網路。這些比較器均可以執行兩個數之間的 比較與條件交換(CCI)操作。Batcher排序網路是由一系列Batcher歸併網路組成的,故Batcher排序網路可以分為奇偶排序網路和雙調排序網路兩大類。
•高德納(Knuth)的0-1原理
•奇偶排序網路(Odd-Even Sorting Network)
•雙調排序網路(Bitonic Sorting Network)
