
基本信息
SWISS-PROT是經過注釋的蛋白質序列資料庫,由歐洲生物信息學研究所(EBI)維護。資料庫由蛋白質序列條目構成,每個條目包含蛋白質序列、引用文獻信息、分類學信息、注釋等,注釋中包括蛋白質的功能、轉錄後修飾、特殊位點和區域、二級結構、四級結構、與其它序列的相似性、序列殘缺與疾病的關係、序列變異體和衝突等信息。SWISS-PROT中儘可能減少了冗餘序列,並與其它30多個數據建立了交叉引用,其中包括核酸序列庫、蛋白質序列庫和蛋白質結構庫等。利用序列提取系統(SRS)可以方便地檢索SWISS-PROT和其它EBI的資料庫。SWISS-PROT只接受直接測序獲得的蛋白質序列,序列提交可以在其Web頁面上完成。
 SWISS-PROT
SWISS-PROT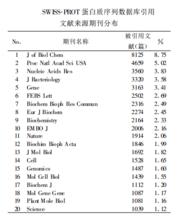 SWISS-PROT
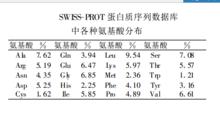
SWISS-PROTSWISS-PROT創建於1986年,由瑞士生物信息學研究所(Swiss Institute for Bioinformatics,SIB)和歐洲生物信息學研究所(European Bioinformatic Institute,EBI)共同協作維護。該資料庫到2001年末共收錄102708個序列數據,包含37803202個胺基酸。在SWISS-PROT資料庫各種胺基酸的分布中,亮氨酸、丙氨酸、絲氨酸、甘氨酸、纈氨酸、谷氨酸占較高的比例,而組氨酸、半胱氨酸、苯丙氨酸等占的比例較小(表)。SWISS-PROT資料庫現有的序列數據涉及1202種期刊的92845篇文獻。被引用100篇文獻以上的期刊有91種,其中經常被引用的前20種期刊(表)被引用次數皆在1000次以上,合計貢獻文獻48314篇,占總被引用文獻數的52.04%,說明這些期刊是發表蛋白質序列相關信息的主要文獻源 。
特點
•可提供蛋白質序列的詳盡注釋信息序列注釋包括蛋白質功能、蛋白質翻譯後修飾、結構域和結合位點、二級結構、四級結構、蛋白質缺陷相關疾病等信息。
•避免過多的重複在SWISS-PROT中,儘量避免過多的重複。對同種蛋白質的多個記錄進行仔細比較後歸結到一個記錄內,方便了用戶檢索利用。
•與其他資料庫交叉參考一次檢索可同時獲得蛋白質的各方面資料信息。
•記錄顯示格式規範欄位名運用兩位字母代碼表示 。
 SWISS-PROT
SWISS-PROTSwissProt採用了和EMBL核酸序列資料庫相同的格式和雙字母標識字。這種雙字母的標識字對於資料庫的管理維護比較方便,但用戶在使用時卻不很方便,特別對資料庫格式不很熟悉的用戶。ExPASy開發了面向生物學家的、基於瀏覽器的用戶界面,特別是用可視化方式表示胺基酸特徵表,使用戶對序列特性一目了然,如二硫鍵、跨膜螺鏇、二級結構片段、活性位點等。截止1998年6月,SWISS-PROT資料庫包含約7萬條序列,這些序列涵蓋了5千多個不同種屬,其中大部分來自於幾種主要模式生物,如人、小鼠等。
SWISS-PROT資料庫的結構與其它蛋白質序列資料庫不同。給出SWISS-PROT資料庫中一個序列條目的實例。圖中每一行由兩個字母起始,用來說明每一行所代表的信息。起其中第一行以ID開始,最後一行以雙斜槓//結束。ID行表示該序列的名稱是OPSD_SHEEP,共有348個胺基酸殘基。SWISS-PROT資料庫的ID包含一定信息,如本例中OPSD表示蛋白質名稱縮寫,而SHEEP表示該蛋白質分子來自於哪個物種,中間用下劃線分隔。即這一蛋白序列是來源於綿羊的視紫紅質(rhodopsin)。序列條目的標識符ID隨著版本的更新有可能改變,因此有必要採用能夠唯一識別該序列條目的其它標識符。SWISS-PROT採用AC(accession number)作為表示某個特定序列的代碼,具有唯一性和永久性。在文獻中引用某個序列時,應以AC為準,而不是以序列名稱或ID為準。本例中,代碼AC為P02700。採用AC代碼的另一個好處是便於計算機處理。如果在AC行出現了幾個代碼值,那么應以第一個為準,它表示該序列在當前版本中的代碼。下面的DT行提供了蛋白質序列提交到資料庫的時間,及最近一次修改的時間等信息。描述行(DE)可以有一行或幾行,提供了對該蛋白質的簡單說明。此例中,說明該蛋白質為視紫紅質。下面的幾行中提供了有關該蛋白質的基因名(GN)、物種來源(OS)和分類學位置(OC)等信息。接下來是與該蛋白質相關的基本注釋信息,包括文獻信息、與測序有關的信息、以及對該蛋白質序列分析得到的與結構或突變相關的信息等。這些注釋為用戶提供了非常有價值的信息。基本注釋信息後,是說明行(CC)。在CC行中按主題進行區分,其中,FUNCTION說明該蛋白質的功能,PTM說明翻譯後修飾,TISSUE SPECIFICITY說明組織專一性,SUBCELLULAR LOCATION說明亞細胞定位,SIMILARITY說明了與該蛋白質序列具有相似性或相關的某個蛋白質家族,等等。蛋白質序列具有與另一個蛋白質序列資料庫PIR的連結、與GPCR專門資料庫的連結,以及與蛋白質序列模體資料庫PROSITE的連結和與蛋白質結構域資料庫ProDom的連結。在DR行之後,是關鍵字行(KW)和特徵表行(FT)。特徵表包括對該序列特性的進一步注釋,包括跨膜螺鏇等超二級結構單元、配體結合位點、翻譯後修飾位點等。特徵表的每一行有一個關鍵字(如TRANSMEM)、特徵序列的胺基酸殘基位置(如37-61),以及注釋信息的性質(如POTENTIAL)等。SWISS-PROT資料庫中的序列數據與蛋白質前體對應,如果想要獲得成熟蛋白質的序列,可以參考特徵表所提供的信息,即根據特徵表所提供的信號(SIGNAL),轉運區(TRANSIT)或前肽(PROPEP)等信息來推斷成熟蛋白質或多肽序列。此外,CHAIN和PEPTIDE兩個關鍵字用來表示成熟蛋白質的位置。SWISS-PROT資料庫的格式便於通過計算機軟體進行查詢,即通過對每行起始的標識字建立索引檔案,即可方便地找到某一欄位。
