
概述
在搜尋引擎中,點擊模型是指對用戶的歷史點擊文檔進行建模,用來預測文檔相關性。
網頁搜尋排序傳統上基於人工設計的排序函式,如BM25等。近幾年,排序學習的引入大大的降低了融合大量特徵的繁瑣程度,不過由於排序學習是監督學習,因此需要大量的人工標註人員對文檔進行標註,這需要大量的人工成本,而且由於網頁的相關性會隨著網頁內容的更新等發生變化,尤其是時效性類的新聞網頁,保持所有的人工標註是最新的是不可行的。
用戶的點擊日誌記錄了用戶對搜尋結果滿意程度的重要信息,能夠提供對相關性預測價值非常高的信息。相比較人工標註而言,點擊的獲得成本更低,而且點擊體現的總是最近的相關性。
點擊問題和難點
1. 點擊的偏置
1) 位置偏向性(position bias)
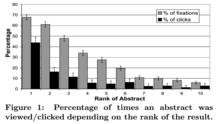
排序越靠前的文檔被用戶瀏覽(examine)和點擊的機率越大 。
 點擊模型
點擊模型 眼動儀實驗
眼動儀實驗2) 吸引偏向性
標題、摘要、垂直結果(圖片、視頻、音樂等)、色情、娛樂八卦、SEO結果等會吸引用戶的點擊。
3) relevance bias
perceived relevance != actual(real) relevance or pre-click relevance != post-click relevance
4) query-intent bias
用戶輸入的query只是真實意圖冰山之一角。
2. 正反饋
如果只依靠點擊,容易產生正反饋,即點擊多的排序高,排序越高相對點擊就會越多,導致正向反饋,新的、好的文檔排不上來。正反饋是一把雙刃劍,好的文檔一直排前也是我們期望達到的。
3. 感知相關性
用戶點擊是感知相關性,即根據標題、摘要等判斷的相關性,而且僅僅是用戶認為的相關性,因此區別於文檔實際的相關性。
4. 稀疏性
長尾查詢無法覆蓋,或者點擊數太少以至於點擊數據不可靠。
點擊稀疏問題分為兩個方面,一個是不完全點擊問題,對於一個query而言,用戶僅僅點擊有限數量的文檔,因此點擊是不完全的;另一個是缺失點擊問題,對大量的queries和documents,用戶沒有點擊數據。
5. 點擊作弊等
如機器人點擊等。
6. 用戶個性化
用戶的點擊行為是一種個性化行為。
7. 冷啟動問題(Cold Start Problem)
新查詢的點擊預測問題
8. Externality
單條url的點擊行為與SERP(Search Engine Return Pages)內其他結果的行為是有關聯的。
9. Query session and Search session
同Externality類似,用戶的一個完整的查詢task可能包括多次query提交,即一個或多個query session組成了search session,顯然同一個search session內多個query session是有關聯的。
點擊模型分類
position model
position model假設點擊依賴於相關性(relevance)和檢驗(examination)。每一個排序位置有一個被檢驗到的確定機率,這個機率隨著排序位置遞減而遞減,並且僅依賴於排序位置。url上的一個點擊表明這個url被用戶查看並認為相關。
position model認為搜尋返回結果頁中的url是獨立的,因此不能夠在檢驗機率中捕獲不同url之間的聯繫。舉例來說,對於一個query的兩個相關性一樣的url,用戶可能僅僅點擊了排序靠前的url,滿足用戶需求,因此就結束了搜尋過程。這樣,位置偏置不能夠充分的解釋第二條url上點擊的稀少。
cascade model
cascade model假設用戶順序檢驗url,直到一個相關文檔被點擊。這樣,檢驗的機率間接的依賴兩個因素:url的排序和url之前的所有url的相關性。cascade model做了一個很強的假設,即每次搜尋過程只有一次點擊,因此它不能解釋放棄搜尋或者有多於一次點擊的搜尋。
即使cascade model如此的嚴格,但在解釋排序較高的url的點擊上,依然遠好於其他position model模型。在較低的url排序位置,cascade model表現較其他position model模型相對差一些 。
1.position model
position model假設點擊依賴於相關性(relevance)和檢驗(examination)。每一個排序位置有一個被檢驗到的確定機率,這個機率隨著排序位置遞減而遞減,並且僅依賴於排序位置。url上的一個點擊表明這個url被用戶查看並認為相關。
position model認為搜尋返回結果頁中的url是獨立的,因此不能夠在檢驗機率中捕獲不同url之間的聯繫。舉例來說,對於一個query的兩個相關性一樣的url,用戶可能僅僅點擊了排序靠前的url,滿足用戶需求,因此就結束了搜尋過程。這樣,位置偏置不能夠充分的解釋第二條url上點擊的稀少。
2.cascade model
cascade model假設用戶順序檢驗url,直到一個相關文檔被點擊。這樣,檢驗的機率間接的依賴兩個因素:url的排序和url之前的所有url的相關性。cascade model做了一個很強的假設,即每次搜尋過程只有一次點擊,因此它不能解釋放棄搜尋或者有多於一次點擊的搜尋。
即使cascade model如此的嚴格,但在解釋排序較高的url的點擊上,依然遠好於其他position model模型。在較低的url排序位置,cascade model表現較其他position model模型相對差一些 。
點擊模型相關工作
點擊模型的相關工作如下。
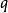 點擊模型
點擊模型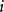 點擊模型
點擊模型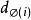 點擊模型
點擊模型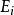 點擊模型
點擊模型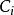 點擊模型
點擊模型點擊模型一個眾所周知的挑戰是位置偏向性(position bias)。這種偏向性被Granka et al [2004]首次注意到,他們發現一個文檔排序越高,即使是不相關的,也會吸引更多的用戶點擊。此後,Richardson et al [2007]提出了對低排序位置的文檔提權;Craswell et al [2008]把這種思想形式化為檢驗假設(examination hypothesis)。給定一個查詢 和一個排序位置是 的文檔 ,檢驗假設假定給定檢驗事件 下二值點擊事件 的機率如下:
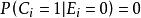 點擊模型
點擊模型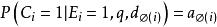 點擊模型
點擊模型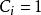 點擊模型 點擊模型 點擊模型
點擊模型 點擊模型 點擊模型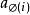 點擊模型 點擊模型 點擊模型 點擊模型
點擊模型 點擊模型 點擊模型 點擊模型這裡我們用 表示位置 的文檔被點擊,否則此值為0, 的定義類似。此外, 表征了查詢 和文檔 的相關程度。很顯然, 在查看之後點擊的條件機率。這樣,點擊率(CTR)可以表示如下:
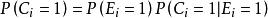 點擊模型
點擊模型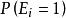 點擊模型
點擊模型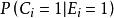 點擊模型
點擊模型這樣CTR被分解為位置偏向性( )和文檔相關性( )。
點擊模型 點擊模型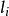 點擊模型
點擊模型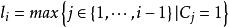 點擊模型
點擊模型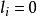 點擊模型
點擊模型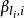 點擊模型 點擊模型 點擊模型
點擊模型 點擊模型 點擊模型 點擊模型
點擊模型 點擊模型
點擊模型檢驗假設的一種重要擴展是UBM模型[Georges Dupret and Benjamin Piwowarski, SIGIR'08]。UBM假設檢驗事件 不僅依賴於位置 ,也依賴於同一個query session里前面的點擊位置 , , 意味著之前沒有點擊。全局參數 表征了從位置 到位置 的轉移機率。我們用 表示 :
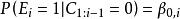 點擊模型
點擊模型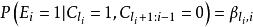 點擊模型
點擊模型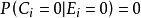 點擊模型
點擊模型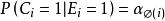 點擊模型
點擊模型使用UBM的一個類似的模型是貝葉斯瀏覽模型(BBM)[C. Liu et al, 2009],BBM採用貝葉斯方法把每個隨機變數作為機率分布推導,這類似於General Click Model(GCM, [Z. Zhu et al, 2010])。GCM考慮了大量的偏向性來擴展模型,並說明了以前的模型都是GCM的特例。Hu et al[2011]擴展UBM描述點擊日誌里的查詢意圖的多樣性。Chen et al[2011]提出了一個全頁的點擊模型,這個模型考慮到了搜尋結果頁的所有結果,包括自然結果和廣告結果,把搜尋結果作為一個整體來幫助CTR預測。
cascade模型是另一個擴展。cascade模型假設用戶從上到下不會跳過的瀏覽文檔。因此,一個文檔被檢驗僅當前面的文檔都被檢驗。
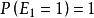 點擊模型
點擊模型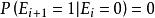 點擊模型 點擊模型
點擊模型 點擊模型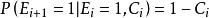 點擊模型
點擊模型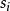 點擊模型
點擊模型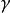 點擊模型
點擊模型對cascade模型兩個重要的改進是CCM[F, Guo et al, 2009]和DBN[O Chapelle and Y. Zhang, 2009]模型。兩個模型都強調了檢驗機率也依賴於前面文檔的點擊和相關性。此外,允許用戶停止檢驗,即放棄搜尋。CCM使用了前面文檔的相關性信息,而DBN則引入了一個用戶滿意的參數 。這個參數表明如果用戶對當前點擊的文檔滿意,那么他將不會再瀏覽下面的文檔。否則,存在一個機率 用戶繼續搜尋。
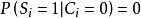 點擊模型
點擊模型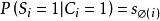 點擊模型
點擊模型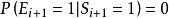 點擊模型
點擊模型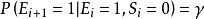 點擊模型
點擊模型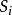 點擊模型
點擊模型這裡 是一個表示用戶滿意的隱事件。
有三個其他的模型沒有套用cascade assumption。SUM(session utility model, [G. Dupret and C. Liao, 2010]),給定一個query,點擊文檔集合的相關性以用戶停在這個query session的機率來表征。adPredictor 模型([T. Graepel et al, 2010])以線性組合帶權值的特徵來解釋點擊率。PRM(pure relevance model, [R. Srikant et al, 2010])認為一個文檔的相關性不是恆定不變的,而是受其他位置的點擊影響。
TCM(Task-centric Click Model, [Yuchen Zhang et al, 2011])不同於上述的假設和方法。TCM針對如何對包括多個query和query會話的整個搜尋會話作為一個整體和動態的實體進行探索。TCM是整合了整個搜尋會話數據的一個更加細緻和有效的點擊模型。
隨著搜尋引擎的發展,搜尋結果頁的展現越來越豐富,搜尋引擎都有很多垂直結果(如圖片或視頻),理解用戶點擊行為作為反饋信息是一種有效的方法,很多點擊模型主要解決位置偏向性問題(position bias),提高普通搜尋結果的排序效果,普通結果的展現樣式是一樣的。然而,當把垂直結果和普通結果組合在一起的時候,展現的巨大不同將導致用戶行為的偏向,也就使得以前的點擊模型失效。在中國一個流行的搜尋引擎的幫助下,我們收集了大量的包含垂直結果和普通結果的行為信息的數據集。我們也利用眼動儀學習了用戶在現實世界中的檢驗行為。通過這些分析,我們發現不同的結果展現可能造成不同的用戶偏向,無論對於垂直結果還是對於整個結果列表。這些偏向性包括:垂直結果(尤其是帶多媒體組件的)的檢驗偏向性,垂直結果的信任偏向性,垂直結果的更高機率的重新訪問。基於這些發現,一個處理考慮位置偏向性之外還考慮這些偏向性的新的點擊模型被構建來描述包含垂直結果的搜尋結果頁的相互作用。實驗結果顯示新的考慮垂直結果的點擊模型(Vertical-aware Click Model, VCM)能夠比已有的模型更好的理解聯合搜尋的用戶點擊行為,在對數似然和困惑度上都變現的更好。
從用戶的角度出發,我們有必要對用戶的偏向進行建模,顯而易見,不同用戶使用搜尋引擎的習慣是不同的。已經有研究者對這個問題進行了研究並發表了論文。
目前大部分的點擊模型都隱含的假設所有的用戶是一致的,即他們在瀏覽搜尋結果的時候行為是一致的。然而,大量的研究已經表明用戶有多樣化的行為模式,這可以被本文的眼動儀實驗和點擊日誌分析證實。對所有用戶一致的點擊模型很難捕獲到多樣性的點擊行為,因此我們提出了把用戶的偏好結合到現有的許多點擊模型中和提出了一個新的點擊模型這兩種方式。在大規模點擊日誌集合的實驗結果表明加入用戶偏向的點擊模型一致的明顯優於傳統模型。
點擊模型示例
DBN
DBN,Dynamic Bayesian Network Click Model,由雅虎實驗室的Olivier Chapelle和Ya Zhang提出,發表在2009年WWW會議上。
DBN模型假設
檢驗假設:如果用戶點擊了一個文檔,若且唯若用戶檢驗過這個文檔並認為這個文檔相關。
用戶按順序從上到下瀏覽文檔,並且根據認為相關與否決定是否點擊。
1.檢驗假設:如果用戶點擊了一個文檔,若且唯若用戶檢驗過這個文檔並認為這個文檔相關。
2.用戶按順序從上到下瀏覽文檔,並且根據認為相關與否決定是否點擊。
DBN模型有兩點區別於傳統的cascade model,一是因為用戶點擊不一定意味著對文檔滿意,因此DBN對感知相關性(perceived relevance)和實際相關性(actual relevance)做了區分;二是在搜尋過程中,DBN不限定用戶點擊的文檔數目。
DBN數據準備
去除一段時間內query的session數比較少的query。
對於不符合模型假設的:點擊不是按順序點擊的,去除,或者人工交換順序。
1.去除一段時間內query的session數比較少的query。
2.對於不符合模型假設的:點擊不是按順序點擊的,去除,或者人工交換順序。
DBN參數估計
DBN模型參數估計採用EM算法。
 DBN模型
DBN模型如下假設或者敘述描述了DBN模型:
用戶點擊某個url若且唯若用戶查看了這個url並被其吸引。被吸引的機率僅依賴於這個url。
與cascade模型一樣,用戶從上到下瀏覽文檔,直到用戶決定停下來。
在用戶點擊並且打開了某個url之後,用戶存在一定的機率對這個url滿意。
如果用戶沒有點擊某個url,說明用戶不滿意。
一旦用戶對某個打開訪問的url滿意,用戶終止搜尋過程。
如果用戶對當前的結果不滿意,以機率r用戶會放棄本次搜尋,1-r的機率查看下一條url。
如果用戶沒有查看位置i,那么用戶也不會查看位置i後續的位置。
url被吸引存在一個Beta先驗機率。url被點擊情況下能夠滿足用戶需求,也存在一個Beta先驗機率。
1.用戶點擊某個url若且唯若用戶查看了這個url並被其吸引。被吸引的機率僅依賴於這個url。
2.與cascade模型一樣,用戶從上到下瀏覽文檔,直到用戶決定停下來。
3.在用戶點擊並且打開了某個url之後,用戶存在一定的機率對這個url滿意。
4.如果用戶沒有點擊某個url,說明用戶不滿意。
5.一旦用戶對某個打開訪問的url滿意,用戶終止搜尋過程。
6.如果用戶對當前的結果不滿意,以機率r用戶會放棄本次搜尋,1-r的機率查看下一條url。
7.如果用戶沒有查看位置i,那么用戶也不會查看位置i後續的位置。
8.url被吸引存在一個Beta先驗機率。url被點擊情況下能夠滿足用戶需求,也存在一個Beta先驗機率。
雖然上述的一些假設不符合實際的情況,一方面可以進行擴展,另一方面DBN的作者通過實驗證明,這樣的模型已經能夠準確的解釋用戶的點擊行為了。
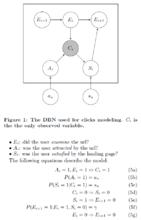
用戶在搜尋過程中,如果發現當前的文檔並不滿足需求,可能存在兩種情況,一是繼續查看下一條文檔,直到找到滿意的文檔為止,二是放棄本次搜尋過程。如果假設用戶是堅持不懈的第一種情況,DBN的參數估計可以大大的簡化,簡化的DBN結果如下:
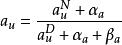 點擊模型
點擊模型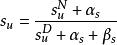 點擊模型
點擊模型其中,au表示文檔吸引程度,su表示用戶滿意程度。α和β表示的相應的先驗機率。再簡化一點,如果忽略先驗機率,那么文檔吸引程度就是點擊的比例,用戶滿意程度就是末次點擊占總點擊的比例。
 A Simplified DBN Model
A Simplified DBN ModelDBN可以對實際相關性建模,如果定義url的相關性是一個在用戶查看條件下滿意的機率,那么:
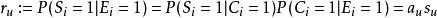 點擊模型
點擊模型ru表示文檔u的相關性,Si表示u滿足用戶需求與否,Ci是用戶點擊,Ei是查看,i是u展示位置。
DBN的完整參數估計算法如下圖所示。
 DBN參數估計 M step
DBN參數估計 M step DBN參數估計 E step
DBN參數估計 E stepDBN和其他模型聯繫
examination model(屬於position model的一種求解方式)是DBN的一個特例,此時,url的檢驗Ei是獨立的,並且僅依賴於位置。這樣,Si(用戶點擊情況下滿意的機率)將變得沒有意義,因為無法被推導出來。
cascade model也是DBN的一個特例,此時,r=1,su=1,即,用戶持續瀏覽url直到發現一個相關文檔,然後點擊,並對結果滿意,結束搜尋。
1.examination model(屬於position model的一種求解方式)是DBN的一個特例,此時,url的檢驗Ei是獨立的,並且僅依賴於位置。這樣,Si(用戶點擊情況下滿意的機率)將變得沒有意義,因為無法被推導出來。
2.cascade model也是DBN的一個特例,此時,r=1,su=1,即,用戶持續瀏覽url直到發現一個相關文檔,然後點擊,並對結果滿意,結束搜尋。
對於position model來說,不同位置的url對於用戶的吸引針對導航型或信息性的查詢是應該區分對待的,原因很簡單,導航型的query,CTRs隨著位置降低衰減的更快。但是DBN模型的作者認為,這種衰減並不是查詢類型的函式,而是排序靠前的url質量的函式。DBN模型不用區分查詢類型,本身就能反映不同類型的查詢。
DBN模型擴展
考慮帶廣告、查詢糾錯、用戶翻頁的情況。
landing page的用戶行為,如停留時間等。
沒有點擊url而滿足了用戶需求,如用戶從摘要獲取到了想要的結果。
滿意變數不要求是二值變數,例如對信息性查詢,典型情況是,用戶在每個頁面上尋找信息片段,全部的信息需求被滿足後才停止搜尋。
非線性的examination model,即用戶可以前向後向跳轉。
解決正反饋。
利用query smoothing 推導其他文檔的相關性。
1.考慮帶廣告、查詢糾錯、用戶翻頁的情況。
2.landing page的用戶行為,如停留時間等。
3.沒有點擊url而滿足了用戶需求,如用戶從摘要獲取到了想要的結果。
4.滿意變數不要求是二值變數,例如對信息性查詢,典型情況是,用戶在每個頁面上尋找信息片段,全部的信息需求被滿足後才停止搜尋。
5.非線性的examination model,即用戶可以前向後向跳轉。
6.解決正反饋。
7.利用query smoothing 推導其他文檔的相關性。
