
基本信息
顧名思義, 編譯程式是一種具有編撰與翻譯功能的程式。一個完整的編譯程式, 再小也包括三個方面的內容: 詞法分析、語法分析和語義翻譯。
人類要用計算機來解決問題, 首先面臨的一個問題, 就是要告訴計算機解決什麼問題, 或許還要告訴計算機如何解決這個問題。這就牽涉到用什麼樣的語言來描述的問題。人所習慣的語言與計算機的基本語言( 機器指令) 有很大的差別, 用機器指令來描述人想解決的問題十分不便。因而, 計算機科學家設計一些比較習慣的語言來描述要解決的問題。這種語言, 因為面向與接近人的自然語言, 表達力強, 易於使用, 易於為人理解與接受, 稱為高級程式語言。相反, 能被計算機直接理解與執行的語言, 即機器指令, 卻不易被人們理解與接受, 因而被稱為低級機器語言。不管用什麼語言來表達的對問題的描述, 通常都稱為程式。例如, FORTRAN 語言, ALGOL 60 語言, PASCAL 語言, C語言, ADA語言, C++ 語言等都是高級程式設計語言。
各種機器的機器語言及其相應的彙編語言, 都是低級程式設計語言. 用高級語言寫的程式, 不能直接被計算機理解與執行, 必須經過等價的轉換, 變成機器能理解與執行的機器語言的程式。進行這種等價轉換的工作, 就是編譯程式的任務。一般地說, 編譯程式就是這樣一種程式, 它將用一種語言寫的程式, 等價地轉換為另一種語言寫的程式。因此,它也叫翻譯程式。前一個程式, 即被翻譯的程式, 叫源程式; 後一個程式, 即翻譯成的程式,叫目的程式或目標程式。
因此, 翻譯程式與編譯程式這兩個名詞並無大的區別。但是, 通常把從高級語言寫的源程式到機器語言表示的目標程式的轉換程式稱為編譯程式。而把從一種語言寫的源程式到另一種語言寫的目標程式的轉換程式稱作翻譯程式。例如, 從ADA 語言到C 語言的轉換, 從ADA 語言到PASCAL 語言的轉換, 從C 語言到ADA 語言的轉換都是翻譯程式。
通用結構
編譯程式的內部結構及組織方式雖是五花八門, 變化多端。但是, 萬變不離其宗, 其主要工作有兩大部分: 分析與綜合。所謂分析, 即對被編譯的源程式進行分析; 所謂綜合, 是在分析正確無誤之後, 綜合出可以執行的機器語言程式, 執行的結果應正確無誤, 同源程式應達到的目的完全一致。
現代編譯程式都是語法制導的, 也就是說, 編譯的過程由源程式的語法結構來控制,而語法結構通常由語法分析器( 程式) 來識別。語法分析器讀入詞法分析器輸出的單詞流,並由此建立源程式的語法結構。詞法分析器逐一讀入源程式的字元, 分析字元流的詞法結構, 組成一個個的單詞, 如標識符、數、運算符等。語法結構的識別是分析部分的主要內容。根據程式的語法結構, 語義分析器分析程式的語義( 意義)。語義分析器包含許多語義子程式, 在識別一種語法結構時, 就調用與此結構相關的語義子程式, 對附於該語法結構上的短語作語義檢查, 如一致性檢查與作用域分析, 確定其意義, 綜合出各程式部分的中間語言表示( IR) 或目標代碼。如果產生了IR, 它作為代碼生成器的輸入, 由此生成所需的機器語言程式。在語義分析器與代碼生成器之間, 可以夾一層最佳化, 它改變IR 序列, 使其可以由此產生高效的代碼, 又與源程式的執行結果一致。一個編輯程式基本上就由這些部件組成。
詞法分析
源程式可以簡單地被看成是一個多行的字元串。詞法分析器逐一從前到後( 從左到右) 讀入字元, 按照源語言規定的詞法規則, 拼寫出一個一個的單詞( TOKEN)。此後, 編譯程式就把單詞當作源語言的最小單位。
語法分析
源語言的語法由以產生式為主體的上下文無關文法描述, 據此, 語法分析器讀入單詞, 將它們組合成按產生式規定的詞組( 短語)。例如, 根據賦值語句的產生式:
〈賦值語句〉→〈變數〉∶ =〈表達式〉
及〈表達式〉的產生式:
〈表達式〉→〈表達式〉+〈項〉
〈表達式〉→〈項〉
〈項〉→〈項〉*〈因式〉
〈項〉→〈因式〉
〈因式〉→標識符
〈因式〉→數
每個產生式都有形式: 左部→右部。左部只有一個符號, 叫非終結符, 表示一個語法單位。右部是由非終結符與終結符組成的串。只在右部出現的符號叫終結符。非終結符即可在左部又可在右部中出現。
在語法分析中, 如果源程式沒有語法錯, 就能正確地畫出其分析樹, 否則, 就指出語法錯, 給出相應的診斷信息。
語義分析
語義分析階段主要檢查源程式是否包含語義錯誤, 並收集類型信息供後面的代碼生成階段使用。只有語法、語義正確的源程式才可被翻譯成正確的目標代碼。語義分析的一個重要內容是類型檢查。定義一種類型一般包含兩個方面的內容, 類型的載體及其上的操作。例如, 整型是容納整數的空間及定義在存於此空間上的整數的操作的統一體。這個空間是32 位或64 位的字, 操作是+ 、- 、* 、/ 等32 位或64 位整數操作。因此, 每個操作符( 運算符) 的運算元都必須符合源語言的規定。例如, 有的程式語言要求整數加法只施用於兩個整數, 有的程式語言允許將實數自動轉換為整數並進行整數加。有的程式語言把做數組下標用的實數視為一個錯誤並作出錯報告。對表達式及語句中的對象作類型檢查與分析, 是語義分析的重要內容。
在確認源程式的語法與語義( 類型一致性) 之後, 就可以對其進行翻譯, 改變源程式的內部表示, 使其逐步變成可在目標機上運行的目標代碼。
經過類型一致性檢查之後, 有的編譯程式把源程式轉換為明顯的中間語言表示。不妨把這種中間語言表示看成是一種抽象機的程式。一般地說, 這種中間表示應有兩個重要的性質: 易於產生; 易於譯成目標程式。產生中間語言表示的工作也可以看成是一個獨立的編譯階段, 也可以看成是語義分析階段的一部分工作, 即把類型一致性檢查看成靜態語義分析, 產生中間語言表示看成是動態語義分析。
中間語言表示有多種形式,它很像是一台機器的彙編語言, 機器的記憶體單元的作用同暫存器一樣。
符號表管理
在編譯過程中, 源程式中的標識符及其各種屬性都要記錄在符號表中。這些屬性可以提供標識符的存儲分配信息、類型信息、作用域信息等等。對於過程標識符, 還有參數信息, 包括參數的個數及類型, 實形參結合的方式等等。
符號表是一種含記錄的數據結構, 通常一個標識符在符號表中占一個記錄, 記錄中除了標識符的名字域之外, 還有記錄該標識符的屬性的域。符號表在編譯過程中使用頻繁,是影響編譯速度的主要因素。因此, 對符號表的組織的要求是存儲與查找的效率。在詞法分析階段就可識別出標識符, 因而就可將其填入符號表。但是, 標識符的屬性在詞法分析時一般不能確定。例如, 在PASCAL 語言程式的聲明中:VAR X, Y: REAL標識符在前, 類型在後, 且標識符後不直接跟類型, 因此, 在詞法分析看到一個標識符時,其類型還看不到。
在語義分析階段及其以後, 都要使用標識符的屬性, 因此, 都要涉及查詢與填表的問題。
出錯處理
編譯的每個階段都會發現源程式中的錯誤。在發現錯誤之後, 一般要對其有一定的處理措施, 因而編譯還可繼續進行, 不會一有錯誤就停止編譯工作。
在語法與語義分析階段, 一般都處理編譯中可發現的大部分錯誤。詞法分析中可能發現字元拼寫錯誤, 但單詞串違反語言的結構規則( 語法) 的錯誤要由語法分析階段來查。在語義分析中, 編譯程式進一步查出語法上雖正確但含有無意義的操作的成分, 如兩個標識符相加, 一個是數組名, 一個是過程名, 雖然語法上允許, 但語義上不允許。諸如此類的各種錯誤, 都在相應的階段進行處理。
代碼最佳化
代碼最佳化的階段力圖提高中間代碼的質量, 使之運行速度提高, 經語義分析之後, 對於樹表示中的每一內部節點都生成一條指令的直接代碼生成算法。
代碼最佳化階段的設計隨編譯程式不同而異。進行了大量最佳化工作的編譯程式通常稱作“最佳化編譯程式”, 這種編譯程式的大部分編譯時間都花在這個階段。但是, 在實用上仍有許多簡單有效的最佳化算法, 能夠顯著地提高目標程式的運行速度而不明顯地降低編譯速度。
代碼生成
編譯的最後一個階段, 生成目標機代碼, 通常是可供裝配的機器代碼或彙編碼。在代碼生成過程中, 對源程式中使用的變數要分配暫存器或記憶體單元, 然後, 為每一條中間語言指令選擇合適的機器指令, 包括確定機器指令的操作碼或編址模式。
相互關係
這三種設計相互依存, 相互影響。程式語言的設計對編譯程式設計的影響是顯然的。許多新的程式語言的特徵對編譯程式的設計提出了新的課題。如並行程式設計語言的特徵, 就刺激了並行編譯技術的發展。ADA 語言的多任務設施, 要求對運行棧的結構作必要的修改, 運行棧結構的變化又對機器指令提出新的要求。程式設計語言的重載特徵, 對編譯算法也有影響。程式設計語言的信息隱藏要求, 抽象數據類型, 對編譯程式技術都是明顯的。編譯程式技術的進步也強烈地影響著程式語言的設計。
容易編譯實現的程式語言, 往往也易學、易讀、易懂。相反, 難於實現的語言特徵, 也很難為用戶掌握。易於實現的語言, 往往在各種機器上都有編譯程式。流行廣泛的程式語言與編譯程式, 自然又是語言設計成功的標誌。
一般地說, 可編譯的語言是那些在編譯時可確定其結構、對象、作用域、類型的語言。這些靜態的程式成分對編譯程式是很重要的, 在這個前提下, 才能將其完全翻譯成具體的目標機器指令。程式語言及其編譯程式的設計對計算機設計的影響, 體現在計算機指令集設計的變化。
在過去, 計算機指令組的設計較為面向彙編級程式設計, 因此, 很難產生高質量的目標代碼。主要問題是: ① 指令集不統一, 有的操作要在暫存器中做, 有的要在記憶體中做。暫存器又往往分幾類, 每一類又只適合於某種特定類的操作; ② 高級操作太緊密地結合特定語言, 其作用難以發揮。雖然大多數語言都支持分程式結構及動態存儲分配, 但是棧式與堆式存儲器仍然很難高效地實現。
微程式技術的廣泛使用使許多使用最普遍的操作得以用少量甚至一條指令來實現。這種設計形成了一個機器體系CISC。即所謂複雜指令組計算機。
另一個對立的體系是所謂的RISC 體系, 即精簡指令組計算機。其基本思想是指令集的體系應當簡單。奇怪的是, 這種設計也考慮到編譯程式的要求。持這種觀點的人認為,程式都是用高級語言書寫的, 並由最佳化的編譯程式來編譯的。指令的簡單性的目的是使編譯的工作更加容易, 減少代碼生成中可能選擇的個數。
但可以說, 它們都考慮到高級語言的執行, 考慮到如何減輕編譯程式人員的負擔而影響計算機的設計。
通用系統
數控(NC)代碼編譯指對NC代碼進行詞法分析、語法分析及語義分析,查出其中存在的錯誤,並對錯誤進行相應處理。NC程式編譯水平及效率是影響NC加工效率的一項重要因素。目前存在的NC代碼編譯器多為專用編譯器,雖可顯著提高NC代碼編譯效率,但存在開發工作量大、周期長、改進或修補困難及適用面窄等局限性。並對傳統NC代碼編譯技術加以擴展,將代碼轉換增加到其中,提出系統定製方法,使NC代碼編譯系統可適用於多種NC系統的代碼,即達到通用性要求,可從理論上建立了一個新的NC代碼編譯模式,該模式可突破傳統NC代碼編譯的缺陷,顯著提高NC代碼編譯效率。
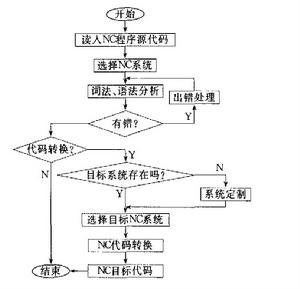 系統實現流程
系統實現流程整個編譯系統可分為NC代碼編譯和NC系統定製兩大模組。NC代碼編譯模組的功能是針對給定NC系統,對代碼進行詞法分析和語法分析,然後將通過檢查無誤的代碼轉換為另一指定NC系統的格式。根據其實現功能,可劃分為詞法分析、語法分析、出錯處理和代碼轉換4個子模組。NC系統定製則提供足夠互動功能,使用戶可根據具體要求為編譯系統添加NC系統特徵,以滿足編澤多種類型NC代碼的需要。系統定製又可分為前後期2個子模組,前期子模組用於實現系統定製中與用戶互動部分的功能,後期子模組則用於建立定製系統與NC代碼編譯之間的聯繫。系統實現流程見圖。
