定義及介紹
語義網路模型又叫語義記憶的層次網路模型,是美國心理學家A.M.柯林斯和奎林(J. R. Quillian)於1969年提出的。
該模型認為,長時記憶中語義記憶的基本單元是概念,每個概念具有一些特徵。有關概念按照邏輯的上下級關係組成一個具有層次的網路系統(見圖)。圖中的圓點表示結點,代表一個概念,帶箭頭的線段表示概念之間的從屬關係以及概念與特徵的關係,以此構成一個複雜的層次網路。該模型對概念的特徵實行相應的分級貯存。在每一水平上,只貯存該級概念獨有的特徵,而同一級各概念具有的共同特徵則貯存於上一級概念水平上。這樣的分級貯存可以節省儲存空間,體現出“認知經濟原則”。
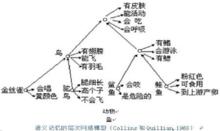 語義網路模型
語義網路模型該模型是一種預存模型,表明由一些概念的聯繫構成的知識,預先就已貯存在語義記憶中。當需要從記憶中提取信息時,可以沿著連線進行搜尋。搜尋是這個模型的加工過程。
實驗過程
實驗假設:一個特定的問題將會激活層次網路的一個結點,穿過層次網路去發現一個問題的答案的距離越長,則所用時間越長。
實驗過程:向被試呈現一些簡單的陳述句,如“金絲雀是鳥”、“金絲雀是動物”、“金絲雀是金絲雀”(他們之間的區別是語義存儲水平上的不同),句子每次只隨機呈現一句。要求被試用按鍵的方式對句子的真假作出反應,記錄被試的反應時間。
實驗結果:結果發現,被試判斷“金絲雀是金絲雀”比判斷“金絲雀是動物”時間更短,判斷“金絲雀是鳥”比判斷“金絲雀是動物”的時間更短。
實驗結論:“金絲雀是動物”句子中的動物與金絲雀相距兩個層級,會出現距離或者是範疇大小效應,即“金絲雀是鳥”比“金絲雀是動物”的判斷時間要快。證實了在層次語義網路模型中,主語節點與謂語節點之間的距離越遠,證實該陳述句所需時間就越長
評價
該模型可以通過“範疇大小效應”來得到驗證,但無法解釋“熟悉效應”“典型性效應”以及“作出否定判斷時反應反而快”的現象,而且缺乏概念間的橫向聯繫,從而限制了其表征和加工能力。
