基本概述
虛擬繼承是多重繼承中特有的概念。虛擬基類是為解決多重繼承而出現的。如下圖所示。
類D繼承自類B1、B2,而類B1、B2都繼承自類A,因此出現如右圖所示的局面(非虛基類)。
為了節省記憶體空間,可以將B1、B2對A的繼承定義為虛擬繼承,而A就成了虛擬基類。最後形成如左圖所示的情況。
實現的代碼如下:
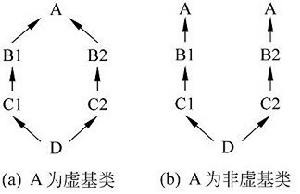 虛基類和非虛基類的區別
虛基類和非虛基類的區別class A;//忽略C1和C2
class B1:public virtual A;
class B2:public virtual A;
class D:public B1,public B2;
虛擬繼承入門
為什麼要引入虛擬繼承?虛擬繼承在一般的套用中很少用到,所以也往往被忽視,這也主要是因為在C++中,多重繼承是不推薦的,也並不常用,而一旦離開了多重繼承,虛擬繼承就完全失去了存在的必要(因為這樣只會降低效率和占用更多的空間,關於這一點,我自己還沒有太多深刻的理解,有興趣的可以看網路上白楊的作品《RTTI、虛函式和虛基類的開銷分析及使用指導》,說實話我目前還沒看得很明白,高人可以指點下我)。
一個例子以下面的一個例子為例:
#include <iostream.h>
#include <memory.h>
class CA
{
int k; //如果基類沒有數據成員,則在這裡多重繼承編譯不會出現二義性
public:
void f() {cout << "CA::f" << endl;}
};
class CB : public CA
{
};
class CC : public CA
{
};
class CD : public CB, public CC
{
};
void main()
{
CD d;
d.f();
}
當編譯上述代碼時,我們會收到如下的錯誤提示:
error C2385: 'CD::f' is ambiguous
即編譯器無法確定你在d.f()中要調用的函式f到底是哪一個。這裡可能會讓人覺得有些奇怪,命名只定義了一個CA::f,既然大家都派生自CA,那自然就是調用的CA::f,為什麼還無法確定呢?
這是因為編譯器在進行編譯的時候,需要確定子類的函式定義,如CA::f是確定的,那么在編譯CB、CC時還需要在編譯器的語法樹中生成CB::f,CC::f等標識,那么,在編譯CD的時候,由於CB、CC都有一個函式f,此時,編譯器將試圖生成這兩個CD::f標識,顯然這時就要報錯了。(當我們不使用CD::f的時候,以上標識都不會生成,所以,如果去掉d.f()一句,程式將順利通過編譯)
要解決這個問題,有兩個方法:
1、重載函式f():此時由於我們明確定義了CD::f,編譯器檢查到CD::f()調用時就無需再像上面一樣去逐級生成CD::f標識了;
此時CD的元素結構如下:
|CB(CA)|
|CC(CA)|
故此時的sizeof(CD) = 8;(CB、CC各有一個元素k)
2、使用虛擬繼承:虛擬繼承又稱作共享繼承,這種共享其實也是編譯期間實現的,當使用虛擬繼承時,上面的程式將變成下面的形式:
#include <iostream.h>
#include <memory.h>
class CA
{
int k;
public:
void f() {cout << "CA::f" << endl;}
};
class CB : virtual public CA //也有一種寫法是class CB : public virtual CA
{ //實際上這兩種方法都可以
};
class CC : virtual public CA
{
};
class CD : public CB, public CC
{
};
void main()
{
CD d;
d.f();
}
此時,當編譯器確定d.f()調用的具體含義時,將生成如下的CD結構:
|CB|
|CC|
|CA|
同時,在CB、CC中都分別包含了一個指向CA的虛基類指針列表vbptr(virtual base table pointer),其中記錄的是從CB、CC的元素到CA的元素之間的偏移量。此時,不會生成各子類的函式f標識,除非子類重載了該函式,從而達到“共享”的目的(這裡的具體記憶體布局,可以參看鑽石型繼承記憶體布局,在白楊的那篇文章中也有)。
也正因此,此時的sizeof(CD) = 12(兩個vbptr + sizoef(int));
另註:
如果CB,CC中各定義一個int型變數,則sizeof(CD)就變成20(兩個vbptr + 3個sizoef(int)
如果CA中添加一個virtual void f1(){},sizeof(CD) = 16(兩個vbptr + sizoef(int)+vptr);
再添加virtual void f2(){},sizeof(CD) = 16不變。原因如下所示:帶有虛函式的類,其記憶體布局上包含一個指向虛函式列表的指針(vptr),這跟有幾個虛函式無關。
虛繼承與虛基類的本質
虛繼承和虛基類的定義是非常的簡單的,同時也是非常容易判斷一個繼承是否是虛繼承
的,雖然這兩個概念的定義是非常的簡單明確的,但是在C++語言中虛繼承作為一個比較生
僻的但是又是絕對必要的組成部份而存在著,並且其行為和模型均表現出和一般的繼承體系
之間的巨大的差異(包括訪問性能上的差異),現在我們就來徹底的從語言、模型、性能和
套用等多個方面對虛繼承和虛基類進行研究。
首先還是先給出虛繼承和虛基類的定義。
虛繼承:在繼承定義中包含了virtual關鍵字的繼承關係;
虛基類:在虛繼承體系中的通過virtual繼承而來的基類,需要注意的是:
struct CSubClass : public virtual CBase {}; 其中CBase稱之為CSubClass
的虛基類,而不是說CBase就是個虛基類,因為CBase還可以不不是虛繼承體系
中的基類。
有了上面的定義後,就可以開始虛繼承和虛基類的本質研究了,下面按照語法、語義、
模型、性能和套用五個方面進行全面的描述。
語法有語言的本身的定義所決定,總體上來說非常的簡單,如下:
struct CSubClass : public virtual CBaseClass {};
其中可以採用public、protected、private三種不同的繼承關鍵字進行修飾,只要
確保包含virtual就可以了,這樣一來就形成了虛繼承體系,同時CBaseClass就成為
了CSubClass的虛基類了。
其實並沒有那么的簡單,如果出現虛繼承體系的進一步繼承會出現什麼樣的狀況呢?
如下所示:
/*
* 帶有數據成員的基類
*/
struct CBaseClass1
{
CBaseClass1( size_t i ) : m_val( i ) {}
size_t m_val;
};
/*
* 虛擬繼承體系
*/
struct CSubClassV1 : public virtual CBaseClass1
{
CSubClassV1( size_t i ) : CBaseClass1( i ) {}
};
struct CSubClassV2 : public virtual CBaseClass1
{
CSubClassV2( size_t i ) : CBaseClass1( i ) {}
};
struct CDiamondClass1 : public CSubClassV1, public CSubClassV2
{
CDiamondClass1( size_t i ) : CBaseClass1( i ), CSubClassV1( i ), CSubClassV2( i ) {}
};
struct CDiamondSubClass1 : public CDiamondClass1
{
CDiamondSubClass1( size_t i ) : CBaseClass1( i ), CDiamondClass1( i ) {}
};
注意上面代碼中的CDiamondClass1和CDiamondSubClass1兩個類的構造函式初始化列
表中的內容。可以發現其中均包含了虛基類CBaseClass1的初始化工作,如果沒有這
個初始化語句就會導致編譯時錯誤,為什麼會這樣呢?一般情況下不是只要在
CSubClassV1和CSubClassV2中包含初始化就可以了么?要解釋該問題必須要明白虛
繼承的語義特徵,所以參看下面語義部分的解釋。
從語義上來講什麼是虛繼承和虛基類呢?上面僅僅是從如何在C++語言中書寫合法的
虛繼承類定義而已。首先來了解一下virtual這個關鍵字在C++中的公共含義,在C++
語言中僅僅有兩個地方可以使用virtual這個關鍵字,一個就是類成員虛函式和這裡
所討論的虛繼承。不要看這兩種套用場合好像沒什麼關係,其實他們在背景語義上
具有virtual這個詞所代表的共同的含義,所以才會在這兩種場合使用相同的關鍵字。
那么virtual這個詞的含義是什麼呢?
virtual在《美國傳統詞典[雙解]》中是這樣定義的:
adj.(形容詞)
1. Existing or resulting in essence or effect though not in actual
fact, form, or name:
實質上的,實際上的:雖然沒有實際的事實、形式或名義,但在實際上或效
果上存在或產生的;
2. Existing in the mind, especially as a product of the imagination.
Used in literary criticism of text.
虛的,內心的:在頭腦中存在的,尤指意想的產物。用於文學批評中。
我們採用第一個定義,也就是說被virtual所修飾的事物或現象在本質上是存在的,
但是沒有直觀的形式表現,無法直接描述或定義,需要通過其他的間接方式或手段
才能夠體現出其實際上的效果。
那么在C++中就是採用了這個詞意,不可以在語言模型中直接調用或體現的,但是確
實是存在可以被間接的方式進行調用或體現的。比如:虛函式必須要通過一種間接的
運行時(而不是編譯時)機制才能夠激活(調用)的函式,而虛繼承也是必須在運行
時才能夠進行定位訪問的一種體制。存在,但間接。其中關鍵就在於存在、間接和共
享這三種特徵。
對於虛函式而言,這三個特徵是很好理解的,間接性表明了他必須在運行時根據實際
的對象來完成函式定址,共享性表象在基類會共享被子類重載後的虛函式,其實指向
相同的函式入口。
對於虛繼承而言,這三個特徵如何理解呢?存在即表示虛繼承體系和虛基類確實存在,
間接性表明了在訪問虛基類的成員時同樣也必須通過某種間接機制來完成(下面模型
中會講到),共享性表象在虛基類會在虛繼承體系中被共享,而不會出現多份拷貝。
那現在可以解釋語法小節中留下來的那個問題了,“為什麼一旦出現了虛基類,就必
須在沒有一個繼承類中都必須包含虛基類的初始化語句”。由上面的分析可以知道,
虛基類是被共享的,也就是在繼承體系中無論被繼承多少次,對象記憶體模型中均只會
出現一個虛基類的子對象(這和多繼承是完全不同的),這樣一來既然是共享的那么
每一個子類都不會獨占,但是總還是必須要有一個類來完成基類的初始化過程(因為
所有的對象都必須被初始化,哪怕是默認的),同時還不能夠重複進行初始化,那到
底誰應該負責完成初始化呢?C++標準中(也是很自然的)選擇在每一次繼承子類中
都必須書寫初始化語句(因為每一次繼承子類可能都會用來定義對象),而在最下層
繼承子類中實際執行初始化過程。所以上面在每一個繼承類中都要書寫初始化語句,
但是在創建對象時,而僅僅會在創建對象用的類構造函式中實際的執行初始化語句,
其他的初始化語句都會被壓制不調用。
為了實現上面所說的三種語義含義,在考慮對象的實現模型(也就是記憶體模型)時就
很自然了。在C++中對象實際上就是一個連續的地址空間的語義代表,我們來分析虛
繼承下的記憶體模型。
3.1. 存在
也就是說在對象記憶體中必須要包含虛基類的完整子對象,以便能夠完成通過地址
完成對象的標識。那么至於虛基類的子對象會存放在對象的那個位置(頭、中間、
尾部)則由各個編譯器選擇,沒有差別。(在VC8中無論虛基類被聲明在什麼位置,
虛基類的子對象都會被放置在對象記憶體的尾部)
3.2. 間接
間接性表明了在直接虛基承子類中一定包含了某種指針(偏移或表格)來完成通
過子類訪問虛基類子對象(或成員)的間接手段(因為虛基類子對象是共享的,
沒有確定關係),至於採用何種手段由編譯器選擇。(在VC8中在子類中放置了
一個虛基類指針vbc,該指針指向虛函式表中的一個slot,該slot中存放則虛基
類子對象的偏移量的負值,實際上就是個以補碼錶示的int類型的值,在計算虛
基類子對象首地址時,需要將該偏移量取絕對值相加,這個主要是為了和虛表
中只能存放虛函式地址這一要求相區別,因為地址是原碼錶示的無符號int類型
的值)
3.3. 共享
共享表明了在對象的記憶體空間中僅僅能夠包含一份虛基類的子對象,並且通過
某種間接的機制來完成共享的引用關係。在介紹完整個內容後會附上測試代碼,
體現這些內容。
由於有了間接性和共享性兩個特徵,所以決定了虛繼承體系下的對象在訪問時必然
會在時間和空間上與一般情況有較大不同。
4.1. 時間
在通過繼承類對象訪問虛基類對象中的成員(包括數據成員和函式成員)時,都
必須通過某種間接引用來完成,這樣會增加引用定址時間(就和虛函式一樣),
其實就是調整this指針以指向虛基類對象,只不過這個調整是運行時間接完成的。
(在VC8中通過打開彙編輸出,可以查看*.cod檔案中的內容,在訪問虛基類對象
成員時會形成三條mov間接定址語句,而在訪問一般繼承類對象時僅僅只有一條mov
常量直接定址語句)
4.2. 空間
由於共享所以不同在對象記憶體中保存多份虛基類子對象的拷貝,這樣較之多繼承
節省空間。
