評價指標
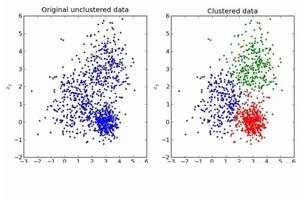 無監督聚類
無監督聚類對於無類標的情況,沒有唯一的評價指標。對於數據凸分布的情況我們只能通過類內聚合度、類間低耦合的原則來作為指導思想,如下如:
當然,有這些還不夠,對於如下圖所示的數據在N維空間中的不是凸分布的情況下,此時我們就需要採用另外的一些評價指標。典型的無監督聚類算法也很多,例如基於局部密度的LOF算法,DBSCAN算法等,在此種情況下的聚類效果就非常的優秀。
目標最佳化
在大多數我們已經學到的監督學習算法中類似於線性回歸邏輯回歸以及更多的算法,所有的這些算法都有一個最佳化目標函式或者某個代價函式需要通過算法進行最小化處理。事實上 K均值也有 一個最佳化目標函式或者需要最小化的代價函式。
算法的第一步就是聚類中心的分配,在這一步中我們要把每一個點劃分給各自所屬的聚類中心,這個聚類簇的劃分步驟實際上就是在 對代價函式進行最小化。
隨機初始化
如何初始化K均值聚類的方法將引導我們討論如何避開局部最優來構建K均值,我們之前沒有討論太多如何初始化聚類中心,有幾種不同的方法可以用來隨機初始化聚類中心,但是事實證明有一種效果最好的一種方法。
1.當運行K-均值方法時,需要有一個聚類中心數量K,K值要比訓練樣本的數量m小;
2.通常初始化K均值聚類的方法是隨機挑選K個訓練樣本;
3.設定μ1到μk讓它們等於這個K個樣本。
