
簡介
最近鄰居法是一種基於實例的學習,或者是局部近似和將所有計算推遲到分類之後的惰性學習。k-近鄰算法是所有的機器學習算法中最簡單的之一。
無論是分類還是回歸,衡量鄰居的權重都非常有用,使較近鄰居的權重比較遠鄰居的權重大。例如,一種常見的加權方案是給每個鄰居權重賦值為1/ d,其中d是到鄰居的距離。
鄰居都取自一組已經正確分類(在回歸的情況下,指屬性值正確)的對象。雖然沒要求明確的訓練步驟,但這也可以當作是此算法的一個訓練樣本集。
最簡單最初級的分類器是將全部的訓練數據所對應的類別都記錄下來,當測試對象的屬性和某個訓練對象的屬性完全匹配時,便可以對其進行分類。但是怎么可能所有測試對象都會找到與之完全匹配的訓練對象呢,其次就是存在一個測試對象同時與多個訓練對象匹配,導致一個訓練對象被分到了多個類的問題,基於這些問題呢,就產生了KNN。
KNN是通過測量不同特徵值之間的距離進行分類。它的思路是:如果一個樣本在特徵空間中的k個最相似(即特徵空間中最鄰近)的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別,其中K通常是不大於20的整數。KNN算法中,所選擇的鄰居都是已經正確分類的對象。該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
下面通過一個簡單的例子說明一下:如下圖,綠色圓要被決定賦予哪個類,是紅色三角形還是藍色四方形?如果K=3,由於紅色三角形所占比例為2/3,綠色圓將被賦予紅色三角形那個類,如果K=5,由於藍色四方形比例為3/5,因此綠色圓被賦予藍色四方形類。
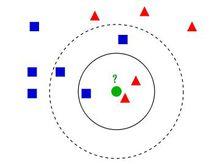 效果圖
效果圖由此也說明了KNN算法的結果很大程度取決於K的選擇。
在KNN中,通過計算對象間距離來作為各個對象之間的非相似性指標,避免了對象之間的匹配問題,在這裡距離一般使用歐氏距離或曼哈頓距離:
 最近鄰居法
最近鄰居法歐式距離:
 最近鄰居法
最近鄰居法曼哈頓距離:
同時,KNN通過依據k個對象中占優的類別進行決策,而不是單一的對象類別決策。這兩點就是KNN算法的優勢。
流程介紹
在訓練集中數據和標籤已知的情況下,輸入測試數據,將測試數據的特徵與訓練集中對應的特徵進行相互比較,找到訓練集中與之最為相似的前K個數據,則該測試數據對應的類別就是K個數據中出現次數最多的那個分類,其算法的描述為:
1)計算測試數據與各個訓練數據之間的距離;
2)按照距離的遞增關係進行排序;
3)選取距離最小的K個點;
4)確定前K個點所在類別的出現頻率;
5)返回前K個點中出現頻率最高的類別作為測試數據的預測分類。
參數選擇
如何選擇一個最佳的K值取決於數據。一般情況下,在分類時較大的K值能夠減小噪聲的影響, 但會使類別之間的界限變得模糊。一個較好的K值能通過各種啟發式技術來獲取。
噪聲和非相關性特徵的存在,或特徵尺度與它們的重要性不一致會使K近鄰算法的準確性嚴重降低。對於選取和縮放特徵來改善分類已經作了很多研究。一個普遍的做法是利用進化算法最佳化功能擴展,還有一種較普遍的方法是利用訓練樣本的互信息進行選擇特徵。
在二元(兩類)分類問題中,選取 k為奇數有助於避免兩個分類平票的情形。在此問題下,選取最佳經驗 k值的方法是自助法。
屬性
原始樸素的算法通過計算測試點到存儲樣本點的距離是比較容易實現的,但它屬於計算密集型的,特別是當訓練樣本集變大時,計算量也會跟著增大。多年來,許多用來減少不必要距離評價的近鄰搜尋算法已經被提出來。使用一種合適的近鄰搜尋算法能使K近鄰算法的計算變得簡單許多。
近鄰算法具有較強的一致性結果。隨著數據趨於無限,算法保證錯誤率不會超過貝葉斯算法錯誤率的兩倍。對於一些K值,K近鄰保證錯誤率不會超過貝葉斯的。
決策邊界
近鄰算法能用一種有效的方式隱含的計算決策邊界。另外,它也可以顯式的計算決策邊界,以及有效率的這樣做計算,使得計算複雜度是邊界複雜度的函式。
連續變數估計
K近鄰算法也適用於連續變數估計,比如適用反距離加權平均多個K近鄰點確定測試點的值。該算法的功能有:
從目標區域抽樣計算歐式或馬氏距離;
在交叉驗證後的RMSE基礎上選擇啟發式最優的K鄰域;
計算多元k-最近鄰居的距離倒數加權平均。
1.從目標區域抽樣計算歐式或馬氏距離;
2.在交叉驗證後的RMSE基礎上選擇啟發式最優的K鄰域;
3.計算多元k-最近鄰居的距離倒數加權平均。
發展
然而k最近鄰居法因為計算量相當的大,所以相當的耗時,Ko與Seo提出一算法 TCFP( text categorization using feature projection),嘗試利用特徵投影法來降低與分類無關的特徵對於系統的影響,並藉此提升系統性能,其實驗結果顯示其分類效果與k最近鄰居法相近,但其運算所需時間僅需k最近鄰居法運算時間的五十分之一。
除了針對檔案分類的效率,尚有研究針對如何促進 k最近鄰居法在檔案分類方面的效果,如Han等人於2002年嘗試利用貪心法,針對檔案分類實做可調整權重的k最近鄰居法( weighted adjusted k nearest neighbor),以促進分類效果;而Li等人於2004年提出由於不同分類的檔案本身有數量上有差異,因此也應該依照訓練集合中各種分類的檔案數量,選取不同數目的最近鄰居,來參與分類。
