系統架構
cProc雲處理平台是搭建在雲存儲系統上,對業務層直接提供對外開發接口和數據傳輸接口的分散式數據處理平台。cProc雲處理平台是一種處理海量數據的並行編程模型和計算框架,用於對大規模數據集的並行計算。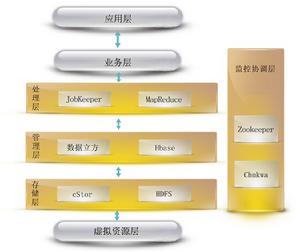
雲存儲層包括公司自主研發的雲儲存系統cStor和apache開源雲儲存系統HDFS;而在數據管理層中,包含數據立方、Hbase;數據處理層包含JobKeeper和MapReduce;最後的監控協調層則包括zookeeper和Chukwa來實現對整個系統的實時監控和數據管理。
cProc雲計算平台通過把對數據集的大規模操作分發給網路上的每個節點實現數據處理,每個節點會周期性的把完成的工作和狀態的更新報告回來。隨著節點的增多,cProc雲計算平台的處理能力將成倍數增長。cProc支持100GBps以上量級的數據流實時索引,1s內回響客戶請求,秒級完成數據處理、查詢和分析工作。
任務監控器(JobKeeper)
JobKeeper調度平台是建立於虛擬化資源層之上,統一調度,統一配置的管理平台,
套用層是一組用於管理和結果反饋的顯示組件,用於顯示任務的處理情況以及集群中機器的活動情況,同時其也是一個上層套用和底層服務的對接平台,是整個系統面向用戶和開發人員的基礎承載。
業務層是對於套用層的相關功能的業務化,數位化處理,用於將套用層的需求任務進行規則化劃分,形成統一的處理化模式。
數據處理層是獨立的數據處理程式,是對不同需求數據的統一處理方案,它的運行與監控的工作將由JobKeeper調度平台進行統一的配置管理。
存儲層是用來存儲數據存儲層的處理結果集或者其它中間結果集的單元。
虛擬化資源層是將實體的機器進行虛擬化,形成更大範圍的服務集群。
JobKeeper調度平台是由一組管理節點(Master Node)和一組處理節點(Task Node)組成,管理節點組是一組基於Webserver的RPC(RPC採用客戶機/伺服器模式。請求程式就是一個客戶機,而服務提供程式就是一個伺服器。首先,客戶機調用進程傳送一個有進程參數的調用信息到服務進程,然後等待應答信息。在伺服器端,進程保持睡眠狀態直到調用信息的到達為止。當一個調用信息到達,伺服器獲得進程參數,計算結果,傳送答覆信息,然後等待下一個調用信息,最後,客戶端調用進程接收答覆信息,獲得進程結果,然後調用執行繼續進行。)伺服器,負責對處理節點的系統信息以及任務處理信息進行實時的跟蹤和保存,對應的信息鏡像存儲在基於cStor或者NFS服務的存儲系統上,保證每個管理節點中的鏡像信息的實時同步。同時架設在管理節點上的ZooKeeper服務(ZooKeeper是一個分散式的,開放源碼的分散式應用程式協調服務,包含一個簡單的原語集。分散式套用可以使用它來實現諸如:統一命名服務、配置管理、分散式鎖服務、集群管理等功能。)用於對整個管理節點組進行統一的配置化管理。處理節點組通過RPC的遠程調用獲取各自節點的任務處理目標,並實時的和處理節點上的任務處理目標進行對比,控制程式的執行和結束。(註:這裡的程式,可以是任何語言任何形式的獨立程式,但是必須提供執行腳本,和運行參數選項)處理節點組會在一個設定的心跳間隔內主動的和管理節點組聯繫一次,報告節點存活狀態。如果在若干個心跳間隔後管理節點組仍然沒有獲取到處理節點心跳報告,那么該處理節點將會被踢出處理節點組,同時該節點處理的所有處理任務也會被重新調度。隨著集群處理數據量的不斷增大,處理節點組提供了簡單高效的自動化部署方案,當新機器加入處理集群後,會主動的與管理節點組同步心跳信息,從同一配置伺服器ZooKeeper上獲取相關配置信息,通過WebServer服務獲取任務列表,開始執行數據處理工作。
JobKeeper調度平台提供了一套基於Web的管理化界面,可以實時的觀察各個處理節點的任務運行狀態,以及任務列表的分配情況,機器的負載情況等。用戶在管理系統界面上可以完成所有的工作,如新任務的添加,任務的手動調度以及集群日誌的查看與分析等。
MapReduce可靠性設計
本方案通過使用ZooKeeper的選舉機制解決MapReduce的單點故障,當JobTracker節點宕機時,能夠在一台備用的JobTracker節點上啟動JobTracker進程,並使用虛擬IP機制將虛擬IP指向備用JobTracker節點。在JobTracker進程啟動後,ZooKeeper將未完成的MapReduce作業提交給備用JobTracker節點重新執行。產品特性
使用數據立方大數據一體機解決方案,套用平台能夠支撐千億級紀錄管理、PB級數據存儲和秒級數據查詢能力,大幅提升客戶體驗。1、英特爾Xeon E5家族系列

2、優秀的高溫承受能力及能耗管理

3、超高實時性

套用平台在高效率分散式資料庫軟體-數據立方的支撐下,可以實時完成數據處理和分析工作,如數據處理、數據查詢和統計分析等。數據處理不會出現數據堆積現象,各類分析和查詢工作基本都在秒級完成,具有前所未有的高效性。

數據立方大數據一體機具有超高可靠性,任意節點宕機,系統不停止服務;任意硬碟、網卡等部件損壞,不影響系統服務。系統能夠自動容錯,將數據分散在各個節點上,不會出現丟失數據的現象。任務處理過程中,當節點宕機,系統自動切換並保留現有進度,保障任務繼續執行下去。
5、可伸縮性

在不停止服務的情況下,增加處理節點,平台的處理能力自動增加;減少處理節點,平台的處理能力自動縮減。這樣,可以做到與資源池的無縫對接,根據計算和存儲任務動態地申請或釋放資源,最大限度地提高資源利用率。

採用X86架構超高性價比的英特爾E5家族CPU及英特爾伺服器組件構建雲計算平台,用軟體容錯替代硬體容錯,大大節省成本。在目標性能和可靠性條件下,可比傳統的小型機加商用資料庫方案節省10倍左右的成本。
7、全業務支持
採用NoSQL+關係資料庫混合模式,絕大部分海量數據存放於分散式平台並進行分散式處理,少量實時性要求

