優缺點
優點:
•極高的裝載速度 (最高可以等於所有硬碟IO 的總和,基本是極限了)
•適合大量的數據而不是小數據
•實時載入數據僅限於增加(刪除和更新需要解壓縮Block 然後計算然後重新壓縮儲存)
•高效的壓縮率,不僅節省儲存空間也節省計算記憶體和CPU。
•非常適合做聚合操作。
缺點:
•不適合掃描小量數據
•不適合隨機的更新
•批量更新情況各異,有的最佳化的比較好的列式資料庫(比如Vertica)表現比較好,有些沒有針對更新的資料庫表現比較差。
•不適合做含有刪除和更新的實時操作。
描述
資料庫以行、列的二維表的形式存儲數據,但是卻以一維字元串的方式存儲,例如以下的一個表:
| EmpId | Lastname | Firstname | Salary |
| 1 | Smith | Joe | 40000 |
| 2 | Jones | Mary | 50000 |
| 3 | Johnson | Cathy | 44000 |
這個簡單的表包括員工代碼(EmpId), 姓名欄位(Lastname and Firstname)及工資(Salary).
這個表存儲在電腦的記憶體(RAM)和存儲(硬碟)中。雖然記憶體和硬碟在機制上不同,電腦的作業系統是以同樣的方式存儲的。資料庫必須把這個二維表存儲在一系列一維的“位元組”中,由作業系統寫到記憶體或硬碟中。
行式資料庫把一行中的數據值串在一起存儲起來,然後再存儲下一行的數據,以此類推。
1,Smith,Joe,40000;2,Jones,Mary,50000;3,Johnson,Cathy,44000;
列式資料庫把一列中的數據值串在一起存儲起來,然後再存儲下一列的數據,以此類推。
1,2,3;Smith,Jones,Johnson;Joe,Mary,Cathy;40000,50000,44000; 這是一個簡化的說法。
列式資料庫的代表包括:Sybase IQ,infobright、infiniDB、GBase 8a,ParAccel, Sand/DNA Analytics和 Vertica。
MPP的列存儲數據倉庫包括:Yonghong Z-DataMart
舉例
下面以GBase 8a分析型資料庫為例,描述列存儲對數據存儲與管理的作用。
面對海量數據分析的 I/O 瓶頸,GBase 8a 把表數據按列的方式存儲,其優勢體現在以下幾個方面。
不讀取無效數據:降低 I/O 開銷,同時提高每次 I/O 的效率,從而大大提高查詢性能。查詢語句只從磁碟上讀取所需要的列,其他列的數據是不需要讀取的。例如,有兩張表,每張表100GB 且有100 列,大多數查詢只關注幾個列,採用列存儲,不需要像行存資料庫一樣,將整行數據取出,只取出需要的列。磁碟 I/0 是行存儲的 1/10或更少,查詢回響時間提高 10 倍以上。
高壓縮比:壓縮比可以達到 5 ~ 20 倍以上,數據占有空間降低到傳統資料庫的1/10 ,節省了存儲設備的開銷。
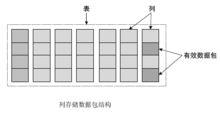 列式資料庫
列式資料庫當資料庫的大小與資料庫伺服器記憶體大小之比達到或超過 2:1 (典型的大型系統配置值)時,列存的 I/O 優勢就顯得更加明顯;
GBase 8a 分析型資料庫的獨特列存儲格式,對每列數據再細分為“數據包”。這樣可以達到很高的可擴展性:無論一個表有多大,資料庫只操作相關的數據包,性能不會隨著數據量的增加而下降。通過以數據包為單位進行 I/O 操作提升數據吞吐量,從而進一步提高I/O效率。
由於採用列存儲技術,還可以實現高效的透明壓縮。
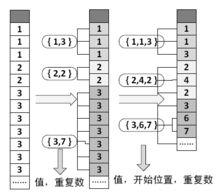 列式資料庫
列式資料庫由於數據按列包存儲,每個數據包內都是同構數據,內容相關性很高,這使得GBase 8a 更易於實現壓縮,壓縮比通常能夠達到 1:10 甚至更優。這使得能夠同時在磁碟 I/O 和 Cache I/O 上都提升資料庫的性能,使 GBase 8a 在某些場景下的運算性能比傳統資料庫快 100 倍以上。
GBase 8a 允許用戶根據需要設定配置檔案,選擇是否進行壓縮。在啟用壓縮的情況下GBase 8a 根據數據的不同特性以及不同的分布狀況,自動採用相應的壓縮算法,如:
行程編碼(適用於大量連續重複的數據,特別是排序數據);
基於數據的差值編碼(適用於重複率低,但彼此差值較小的數據列);
基於位置的差值編碼(適用於重複率高,但分布比較隨機的數據列)。
