
發展概況
隨著Internet的蓬勃發展,網路業務量的不斷增長,人們對網路的服務質量 (QOS) 的要求越來越高。現有的Internet採用的是傳統的“盡力而為”的服務機制,這種機制的優勢是設計簡單,但是存在一個主要的問題就是會產生擁塞崩潰現象,使得鏈路利用率大大下降。所以網際網路必須提供擁塞控制機制。而傳統的TCP端到端的擁塞控制並不能避免擁塞的發生。所以網路本身的節點就必須自主地參與到擁塞控制中。依靠網路結點主動感知緩衝區的占有率來管理快取。從而有效地避免擁塞的發生。佇列管理是指在網路發生擁塞時。通過丟包來管理佇列長度。調節緩衝區的占有率。對佇列長度進行管理將直接影響到網路結點的擁塞控制能力和網路的QOS。而目前佇列管理機制主要有兩大類: 被動佇列調度機制 (PQM)與 主動佇列調度機制(AQM)。 PQM在網際網路上得到了廣泛的套用,但是存在兩個重要的問題:死鎖和滿佇列。由於網際網路的數據具有突發性,在滿佇列的狀態下導致了 “TCP全局同步”現象,導致了整個鏈路的利用率在下降。為此IETF又提出了AQM,AQM方法是根據佇列長度的變化對佇列滿行提前丟包,從而預先告之網路擁塞,使得傳送節點在鏈路快取溢出前作出反映,有效減少和避免擁塞的發生。
AQM 研究現狀
自1998年IETF的RFC2309建議路由器使用AQM機制之後,AQM 成為計算機網路領域的熱點之一。在各種文獻中共提出了幾十種算法,主要有以下幾種算法:RED 算法及其變種算法;基於控制理論的主動佇列管理機制等。
隊尾丟棄算法(Tail Drop)
隊尾丟棄算法(Tail Drop)又稱FIFO即先進先出,是一種被動的佇列管理機制, 也是當前網路上採用的重要的佇列管理方法。其基本的思想就是當網路結點快取佇列長度達到最大值時,通過丟棄分組來指示擁塞,先到達路由器的分組首先被傳輸。
數據包到達路由器後,需要在不同的輸出連線埠緩衝區中進行排隊;這樣當網路發生擁塞的時候,所有新到達又來不及處理的數據包都會保存在緩衝區中,當系統空閒時再來處理這些保存起來的數據包。由於網路結點的快取有限,如果分組到達時快取已滿,那么網路就丟棄該分組。一旦發生丟包,傳送端立即被告知網路發生擁塞,從而調 整傳送速率。這種佇列管理機制目前仍然是網際網路上使用最為廣泛的分組排隊、丟棄的方式。但是它將網路發生擁塞的責任全部都推給了網路邊緣。所以TCP假設網路中的節點( 如路由器)對擁塞起不了任何作用,而由協定本身獨立承擔檢測和回響擁塞的全部責任。這種方式最大的優點是實現很簡單;缺點是容易造成佇列死鎖,進而導致TCP全局同步:當緩衝區被填滿後,所有新到達的數據包都會被丟棄,所有傳送方會同時降低傳送速率;當擁塞消除後,所有傳送方又會同時增大傳送速率,這樣就導致了所有傳送方傳送速率同步化。同時緩衝區很容易被填滿, 無法容納突發的數據流,降低了網路的利用率。
主動佇列管理算法的分類
針對現有的 AQM 算法,從它們的設計原理出發,可以歸為如下3類:
基於(平均)佇列長度的 AQMs
這類基於佇列長度的 AQM 算法在較輕網路負載下能穩定佇列長度在某個範圍內,但在特定的網路環境中依然會造成多個TCP的同步,造成佇列震盪、吞吐量降低和時延抖動加劇。RED、ARED、CHOKe和 PI都屬於這一類算法。
基於網路負載的 AQMs
這類算法通過測量業務流量的輸入速率或根據分組的丟失情況及鏈路使用歷史情況來衡量擁塞的程度。這類基於速率的 AQM 算法提高了算法的回響時間,獲得了較高的吞吐量,但由於沒有對佇列長度的顯示控制,使得算法不能有效地穩定佇列長度,導致時延增大。BLUE]和AVQ屬於這一 類算法。
同時基於佇列長度和網路負載的 AQMs
這類算法的穩定性獲得了很大的提高,穩定佇列長度和端到端時延的能力也較強,但算法的瞬時回響性能以及在實際網路環境中的穩定性還有待加強。REM屬於這一類算法。
理想 AQM 算法的品質
因為RED在穩定性和公平性方面存在問題,目前大多數的AQM 研究格外重視這兩方面的問題,但一個真正可 以實踐的路由器佇列管理算法需要同時滿足多方面的要求,技術指標固然重要,但其他因素也需要給予一定的考慮。綜合各個方面,一個理想的 AQM 算法需要同時具備以下品質。
有效性
AQM 的技術目標可以概括為:在較高的鏈路利用率和較低的分組排隊延時之間取得一個恰如其分的平衡。較小的佇列長度允許路由器有條件在不丟棄分組的前提下最大限度的吸納突發性業務流。在正常情形下,分組經歷的 排隊時延也會小許多,這對實時性的互動式套用尤為重要。當然,片面追求小隊長,空佇列機率加大,導致鏈路利用率降低也是不期望的。最有效的方法是無論網路狀態如何,負載如何變化,始終將佇列保持在一個較小的恆定值附近。從控制理論的角度分析,AQM的技術目標是需要實現一個調節系統,因此在評價算法有效性時,收斂時間自然是一個不可忽視的指標。連線的不斷建立與拆除使得網路狀態瞬息萬變,算法必須具有很好的回響性才能充分適應快速變化的網路環境。
魯棒性
AQM算法的魯棒性包括兩個方面。一是穩定性,即AQM算法自身必須穩定,不能像RED和 AVQ那樣可能導致佇列振盪。二是抗擾性。AQM 算法應該有能力抵抗非回響性業務(如UDP)和短時間突發業務(如HTPP或Telnet) 等擾動或噪聲的干擾。
可擴展性
Internet 的快速發展表現在許多方面:用戶數急劇增加,頻寬迅猛提升,區域網路和廣域網規模不斷擴大,
理想的AQM算法必須在各個維度上具有可擴展性。不僅能工作在平均往返時延(RTT, Round Trip Time)為幾十毫秒的LAN或WAN中, 而且要能穩定工作於有數百毫秒, 甚至秒數量級RTT的WAN 環境下; 既可以支持頻寬為數兆比特的專用線路,也可以支持吉比特的光通路;在用戶較少的接入網與連線密集的核心網中都可以有效工作,不會因為需要維護單個流的狀態信息而影響算法的性能和實現的複雜度。
隨機早期檢測算法(RED)
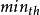 主動佇列管理算法
主動佇列管理算法 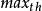 主動佇列管理算法 主動佇列管理算法 主動佇列管理算法 主動佇列管理算法 主動佇列管理算法
主動佇列管理算法 主動佇列管理算法 主動佇列管理算法 主動佇列管理算法 主動佇列管理算法  主動佇列管理算法 主動佇列管理算法
主動佇列管理算法 主動佇列管理算法 為了提高網路性能,Internet 工程任務組(IETF)推薦在路由器中使用活動佇列管理算法 RED,該算法的基本思想是通過監控路由器輸出連線埠佇列的平均長度來探測擁塞,一旦發現接近擁塞,就隨機地選擇連線來通知擁塞,使它們在佇列溢出導致丟包之前減小傳送視窗,降低數據傳送速度,從而緩解網路擁塞。算法具體描述如下:數據包到達路由器後,需要在不同的輸出連線埠緩衝區中進行排隊,每一個輸出連線埠維護一個佇列;當有新的數據包到達時,採用指數加權滑動平均的方法計算 平均佇列長度avg(這個平均是指對時間的平均),並把 avg 與 兩個預先設定的門限(最小門限 和最大門限 )相比較,若平均佇列長度 avg 小於 則不丟棄分組;若 avg 大於或等於 則丟棄所有分組;若 avg大於或等於 而小於 ,則根據平均佇列長度 avg 計算機率 ,以機率 丟棄 到達的分組。
與上面隊尾丟棄算法相比,RED 算法在擁塞發生之前通知傳送方調整速率,能夠有效地降低丟包率;RED 隨機通知傳送方而不是通知所有傳送方,能夠有效地消除全局同步;另 外,RED 還可以通過保持較短的佇列長度來容納突發的數據流。
雖然 RED 能夠有效避免擁塞,但是該算法仍然存在以下主要缺陷:
公平性問題
對於不回響擁塞通知的連線,RED 算法無法有效處理,因此這樣的連線經常會擠占大量的網路頻寬,導致了各種連線不公平地共享頻寬。
參數設定問題
主動佇列管理算法 主動佇列管理算法 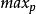 主動佇列管理算法
主動佇列管理算法 RED 算法對參數設定很敏感, 兩個閾值 、 和最大丟包機率 的細微變化經常會對網路性能造成很大影響,如何根據具體業務環境選擇最合適的參數是RED存在的一個重要問題。另外,一組參數可能會獲得 較高的吞吐量,但是可能也會造成較高的丟包率和較長的時間延遲。如何配置參數,使得算法在吞吐量、時間延遲和丟包率等各方面均獲得較好的性能也有待解決。
網路性能問題
RED 算法控制的平均佇列長度經常會隨著連線數目的增加而不斷增大,造成傳輸時延抖動,引起網路性能不穩定。
針對 RED 靜態參數配置的局限性,Wu-chang Feng等提出了自配置 RED、Sally Floyd 提出了自適應 RED(ARED)。James A採用線性系統理論分析了RED 模型,指出 RED 在網路條件大範圍變化的情況下,不能穩定佇列長度的原因在於沒有提出明確的控制目標-目標佇列長度,提出了動態RED(DRED)算法,根據佇列長度與目標值的誤差調節丟棄率, 從而將佇列長度控制在目標值附近。 此外,許多學者對 RED 在設計時沒有考慮到的細節問題進行了補充。例如,RED 在計算報文丟棄機率時沒有考慮報文大小對流的吞吐量和丟棄率的影響,導致 RED 對 MTU比較大的連線丟棄率較高。如果用報文長度與MTU的比值對 RED 的丟棄機率進行調節,能夠保證不同流之間在吞吐量和 丟棄率方面的“公平性” 。 雖然 RED 是為了改善盡力服務網路的擁塞控制而提出來的, 但是 RED 及其改進算法還被廣泛套用於區分服務體系結構中。David D. Clark 等人提出了區分服務體系結構中的 RED 改進算法 RIO(RED with In and Out),在網路邊緣將報文標記為in或 out,對兩類流量採用不同的 RED 參數和丟棄機率,以區分它們的優先權。
FRED
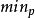 主動佇列管理算法 主動佇列管理算法
主動佇列管理算法 主動佇列管理算法 FRED(Flow Random Early Drop)是最早提出來的基於RED的近似公平分配算法。其基本的思想是通過考察某個流的當前佇列快取占用量來決定該流的分組被丟棄的機率。所謂流的當前佇列快取占用量是指在當前的佇列快取中屬於某個流的分組的個數。FRED最大的特點是通過在路由器維持活動流的狀態信息。即維持活動流的當前佇列快取占用量來獲得一定的公平性。即針對不同的流計算不同的丟棄機率。相對於RED來說,在FRED中通過維持活動流的狀態信息,在發生擁塞時,一方面保護一些“小”流在發生輕度擁塞時,它們的分組也不會被丟棄;另一方面,限制某些流占用過多的頻寬"。但是當不同的流的佇列快取占用量介於 和 之間時,對於這些不同流的分組的丟棄機率的計算與RED中是一樣的。這體現出一些隨意性和不公平性。
另外FRED最大的問題在於它要求在路由器維持活動流的狀態信息。這需要占用路由器的大量快取空間和處理時間。隨著通過路由器的流的數目的增多,會給路由器帶來沉重的負擔。 因此FRED算法的可擴展性較差。
基於控制理論的主動佇列管理機制
通常 RED 的改進方法在增強 RED 性能的同時,增加了算法的複雜度。不論是對 RED 參數設定的研究還是在 RED 基礎上的改進最終都不能得到令人滿意的效果,學術界開始擺脫 RED 結構框架的束縛,尋找新的簡單、魯棒的AQM 控制器。 隨著對TCP協定運行機制認識的深入和計算機網路建模技術的發展,將控制理論套用於主動佇列管理機制的設計成為可能,並且已經成為目前研究的熱點。2000 年,Vishal Misra 等建立了 TCP 與佇列變化的非線性微分方程模型。2001 年, C.V.hollot 採用小信號線性化方法將該模型線性化,並且導出了線性模型的傳遞函式,在此基礎上分析了 RED 的參數設定並設計了比例積分(PI)控制器。基於控制理論設計主動佇列管理機制具有許多優越性:
(1)設計方法更加科學,參數配置變得容易。控制理論是在系統數學模型的基礎上建立起來的完善的理論體系,可以根據系統的穩態和動態性能要求選擇合適的控制器,根據系統的穩定性、準確性、快速性、魯棒性等要求決定控制器的參數。
(2)算法的性能對網路條件的敏感性降低,在控制器的設 計階段就已經將系統的穩態精度、回響速度、穩定裕度、抗干擾能力等作為設計目標。
(3)大部分基於控制理論設計的 AQM 機制的複雜程度與 RED 相當,實現簡單,適用於高速網路。特別是從經典控制理論推導出的控制器,其報文丟棄機率通常是瞬時佇列長度的線性函式。
(4)具有明確的控制目標,消除了佇列長度與負載的耦合,減小了佇列振盪。
套用控制理論設計主動佇列管理機制是目前學術界研究的熱點。許多常用的控制方法被套用到 AQM 設計中來,例 如比例控制器(P)、比例積分控制器(PI)、比例積分微分控制器(PID)、比例微分控制器(PD)等。此外,許多先進控制理論也被用於 AQM 機制的設計,例如魯棒控制、模糊控制、基於狀態反饋的現代控制、神經網路控制等,這些控制器的性能有待進一步的分析和證明。
