
靜態路由選擇算法
靜態路由選擇算法是指採用某種路由選擇算法預先計算出每個路由器的路由表,在路由器加電啟動時載入到路由器中。在路由器工作過程中,路由表內容保持不變。如果網路拓撲結構或其他網路參數發生變化,則需要重新預先計算出各個路由器的路由表,並重新載入到路由器中。這種路由選擇算法也稱固定路由選擇算法。
在靜態路由選擇算法中,有最短路徑(Shortest Path,SP)和基於流量的路由選擇(Flow—based Routing,FR)等。
最短路徑選擇
在最短路徑選擇中,根據網路拓撲結構將一個通信網路表示成一個加權無向圖。
圖中每個節點代表網路中的路由器,連線代表通信線路,連線上標註的數字代表線路的權值。權值可以用線路長度、信道頻寬、平均通信量、通信費用、佇列長度、線路延時以及占用可用資源數量等加權函式計算出來。SP算法就是根據線路的加權值尋找出最短路徑。SP算法最初是由Dijkstra提出的,故也稱Dijkstra算法。
SP算法是一個逐步搜尋過程,其搜尋過程如下。
(1)假如在第m步已經搜尋到一個最短路徑,該路徑上有n個距離源節點最近的節點,它們構成了一個節點集合N;
(2)在第m+1步,繼續搜尋不屬於N的距離源節點最近的節點,並搜尋到的節點加入到N中;
(3)繼續搜尋,直至到達目的節點,N中的節點集合便是從源節點到目的節點的最短路徑。
 路由選擇語句
路由選擇語句在搜尋過程中,每個節點用從源節點沿已知的最短路逕到本節點的距離來標註,例如,在B(2,A)標註中,B表示本節點名,2表示在最短路徑上源節點到本節點的距離(權值累加),A表示最短路徑上的上游節點名。在初始時,由於最短路徑是未知的,故所有節點都標註為無窮大( )。隨著算法的進展和不斷搜尋到最短路徑,節點的標註值也隨之改變,反映出一個較好的路徑。
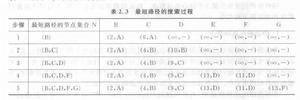 路由選擇語句
路由選擇語句每個路由器節點按照上述的SP算法計算出節點間的最短路徑,形成路由表,在路由器加電啟動時載入到路由器中。在路由器工作過程中,將根據數據分組中的目的地址查找路由表,找出最短的路徑來轉發數據分組。
基於流量的路由選擇
SP算法只是根據網路拓撲結構計算最短路徑,而沒有考慮通信流量或負載。FR算法則考慮網路拓撲結構和通信流量兩方面因素進行路由選擇。
在一些網路中,節點之間的通信流量是相對穩定和可預測的。如果預先知道節點之間平均通信流量的條件下,採用適當的算法對通信流量進行數學分析,可以最佳化路由選擇。FR算法的基本條件是:
(1)必須知道網路拓撲結構;
(2)必須知道節點之間平均通信流量;
(3)必須知道各條線路的容量;
FR算法的基本原理是:對於一個給定的線路,如果已知該線路的負荷量和平均流量,則可以用佇列理論計算出該線路的平均分組延遲。由所有的線路平均延遲可直接計算出流量加權平均值,從而得到整個網路的平均分組延遲。於是,路由選擇問題就可歸結為如何找出產生網路最小延遲的路由選擇算法。
動態路由選擇算法
網路的拓撲結構和通信量是動態變化的,如路由器的加入或退出,網路發生擁擠或阻塞等。如果路由器能夠及時獲得這些網路動態變化情況,並以此作為路由選擇的依據,則會有助於路由器最佳化路由選擇。動態路由選擇算法就是採用這一機理進行路由選擇的.它也稱自適應路由選擇算法。
現代計算機網路系統通常採用動態路由選擇算法。在動態路由選擇算法中,最常用的有距離矢量路由選擇和鏈路狀態路由選擇兩種算法。
距離矢量路由選擇
距離矢量路由選擇(Distance Vector Routing,DVR)算法的基本原理是每個路由器都維護一個路由表,表中記錄有通向目的節點的最佳距離和線路,每個路由器都要與相鄰的路由器交換路由信息來更新路由表,使路由表中的信息總是反映網路最新的動態變化情況。
DVR算法最初套用於ARPANET中,後被其他網路所採用,如DECnet、Novell的IPX協定、Apple的AppleTalk協定以及Cisco路由器等。著名的路由選擇信息協定(Routing Information Protocol,RIP)也是基於該算法開發的。
在DVR算法中,每個路由器都維護一個路由表,表中的每個表項都對應網路中的一個路由器,每個表項包含兩部分內容:一是通往目的節點的輸出線路;二是到達目的節點的距離或所需時間估算值,估算值的度量標準可以是節點數、時間延遲估算值、該路由的佇列長度等。路由器要選擇一種度量標準來估算本節點與目的節點之間的距離,如果選擇節點數,則一個距離長度為一個節點;如果選擇佇列長度,則路由器檢查每個佇列;如果選擇時間延遲,則路由器可以通過向相鄰路由器傳送一個特殊的回應(Echo)分組請求對方回送帶有時間標記的分組來獲得時間延遲值。
在一個網路系統中.每個路由器都按約定(或路由協定)採用某種度量標準來估算它到達目的節點的距離,並傳送給相鄰路由器;同時,它也會從相鄰路由器中得到類似的估算值,並以此更新路由表。這樣,路由器就可以從路由表上這些估算值中找出最佳值,該估算值對應的輸出線路便是最佳路由,並選擇該路由轉發數據分組。
鏈路狀態路由選擇
DVR算法存在兩個主要缺陷:一是在選擇路由時沒有考慮線路頻寬,而線路頻寬隨著網路技術的發展在不斷地提高;二是算法在獲取路由信息時需要耗費很多的時間。因此,DVR算法後來被鏈路狀態路由選擇(Line State Routing,LSR)算法所取代。現在,各種各樣的LSR算法廣泛套用於現代網路系統中,著名的開放最短路徑優先(Open Shortest Path First,OSPF)協定採用的就是LSR算法,而OSPF協定廣泛套用於Internet中。
每個路由器上的LSR算法都要執行如下過程。
(1)發現相鄰路由器,獲取其網路地址。當一個路由器加入網路後,首先向每個相鄰路由器傳送一個特殊的Hello分組,目的是聲明它的存在,並希望得到相鄰路由器的回響。各個相鄰路由器接收到Hello分組後,都回應一個包含本路由器地址的回響分組。每個路由器地址應是一個全局唯一的地址。
(2)測量到各個相鄰路由器的時間延遲或線路開銷。一個路由器可通過傳送Echo分組來測量到各個相鄰路由器的延遲,各個相鄰路由器接收到Echo分組後,都回應一個包含時間標記的回響分組。從傳送Echo分組開始到接收到回響分組所經歷時間除以2,便是該線路的延遲時間估算值。它反映了線路頻寬狀況,線路頻寬越大,延遲時間越小;反之,線路頻寬越小,延遲時間越大。
(3)將測量值通告給其他的路由器。路由器在獲得有關路由器和鏈路狀態信息後,構造一個特殊的鏈路狀態(LS)分組來發布鏈路狀態信息,該分組包含傳送者地址、序號、生存期以及各個相鄰路由器地址和對應的延遲時間估算值等信息。該分組可以周期性地傳送。也可以在網路發生重大事件時傳送,並採用如下的傳遞機制。
①路由器採用擴散法周期地向所有的線路廣播LS分組,每傳送一個新的LS分組,分組的序號加1。
②相鄰路由器接收到LS分組後,通過核對傳送者地址和序號來判斷LS分組是否是重複的或過時的。如果是新的LS分組,則在路由表中記錄新的鏈路狀態信息,並向除輸人線路之外的所有線路擴散,傳播給其他的路由器;如果是重複的LS分組.說明它已從其他的路徑接收到了該分組,則丟棄該分組;如果LS分組的序號小於以前曾收到的來自同一傳送者的LS分組序號,說明該分組是一個過時的LS分組,則丟棄該分組。為了避免序號衝突問題。序號採用較長位數,如32位,序號以232為模,循環周期為232。
③鏈路狀態信息以軟狀態方式保存在路由器中,路由器定期地(如每隔ls)檢查它所記錄的LS分組的生存期,並減1。如果一個LS分組的生存期減至0,則刪除來自該LS分組的鏈路狀態信息。這樣就避免了無效的或出錯的鏈路狀態信息長期占據路由器的存儲空間。
這樣,一個路由器所測量的鏈路狀態信息通過上述的傳遞機制發布給網路中所有的路由器。每個路由器用接收到的LS分組來建立和更新其路由表。
(4)最短路徑。各個路由器在建立路由表後,可採用Dijkstra算法計算到達目的節點的最短路徑,並按該路徑轉發數據分組。
特點
在路由器啟動之後,立刻與其相鄰路由設備建立路由關係。該初始通信的目的是為了識別相鄰設備,開始進行通信並學習網路結構。建立相鄰關係的方法和對拓撲結構的初始學習隨路由選擇協定選擇的不同而不同。
路由選擇協定會定期交換HELLO訊息或路由更新數據包,以維持相鄰設備間的可達性。一個理想的路由選擇算法應具有以下特點:
(1)路由算法必須具有正確性和完整性。一個數據包能根據路由算法所生成的路由表把該數據包指引到最終的目的網路和目的主機。
(2)簡單性。路由選擇算法在生成路由表時在計算上應該簡單,且不應使網路的通信流量增加太多的額外開銷。
(3)適應性。路由選擇算法能根據目前網路的狀態和網路的流量動態地改變路由以均衡網路各鏈路的負載。即當網路的某個節點、鏈路發生故障不能正常工作時,或者修理好了再投入運行時,算法也能及時地改變路由。
(4)穩定性。在網路通信量和網路拓撲相對穩定的情況下,路由算法應收斂於一個可以接受的解,而不應使路由不停地變化。
(5)公平性。路由選擇算法對所有用戶都是平等的。
(6)最佳性。最佳性是指以最低的代價來實現路由算法。這裡的代價是指由一個或幾個綜合因素決定的度量(Metric),如鏈路長度、數據率、鏈路容量、傳播時延等。所以這裡的最佳性只能是相對於某一種特定要求下得出的較為合理的選擇而已。
