概述
產生
該理論的產生是基於經典測量理論的局限和不足,其不足表現在以下幾方面:按經典測量理論所求出的難度、區分度、信度和效度等質量指標,嚴重依賴於樣本,樣本的代表性好壞直接影響著這些參數。經典測量理論中測驗信度的估計是真分數方差與測驗總方差之比,但這是建立在兩個前提假設的基礎之上,即個體的測驗總分僅線性分解為真分數和誤差分數兩部分,並且這兩個部分是相互獨立的。經典測量理論認為人的測驗總分是這個人在些特質上的真分數和測量誤差之和。經典測驗理論多是使用匹配和隨機化來進行誤差控制。
含義
項目反應理論也稱項目特徵曲線理論或潛在特質理論,它是依據一定的數學模型,用項目特徵參數估計潛在特質的一種測量理論。該理論中最重要的兩個基本概念是“潛在特質”和“項目特徵曲線”。
發展
雖然早期的項目反應模型主要是單維度模型而且更強調雙岐項目模式(如拉希模型和三參數邏輯斯蒂模型),而如今一些多維度項目反應模型也逐步發展起來,向其他項目模式的拓展使得它能套用於更多的領域。今天,項目反應理論模型已發展出了等級量表模型、分部評分模型和多重選項計分模型等等。
項目反應理論基礎模型例舉
邏輯斯蒂模型有單參數、雙參數及三參數之分,其函式表達式分別如公式1/2/3:
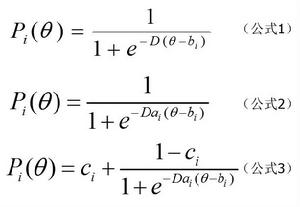 潛在特質理論
潛在特質理論式中,P表示能力為 θ 的被試在項目上正確作答的機率;θ 表示被試的能力;b表示項目 i 的難度參數;e表示自然對數之底=2.71828;D 表示量表因D=1.7;a表示項目 i 的區分度參數;c表示項目 i 的偽隨機水平參數,習慣稱猜測參數。上述三個模型中以三參數邏輯斯蒂模型套用最為廣泛。
項目反應模型的參數估計
套用項目反應理論模型對項目的不同參數進行估計是連線項目反應理論與套用的最關鍵的環節。所謂參數估計是指根據被試的作答反應矩陣, 也就是所有的被試對所有的題目 (或項目 )的作答反應情況, 估計出被試的能力參數和每個項目的參數。參數估計的方法有很多, 我們主要介紹極大似然估計法和貝葉斯估計法。
(一)極大似然估計法 (maximum likelihood estimation)
極大似然估計法是根據被試的作答反應矩陣, 在局部獨立性的條件下, 導出參數估計的似然函式, 然後通過求取似然函式的極大值, 估計項目參數和被試能力參數。因為一個隨機變數可能會有各種分布, 或者說可能會以各種機率出現, 在這些機率中, 可能會有一個最可能的最大的機率。因此, / 極大似然估計0就是估計出機率的最可能的極大值。當參數變化時, 機率的非極大值可能不止一個, 但極大值一般只有一個。參數估計時需要估計出兩方面的參數:項目參數和能力參數。首先假設項目參數已知, 只對能力參數進行估計, 然後將估計出來的能力值假設為真實值, 只對項目參數進行估計, 將這一過程反覆循環進行, 直至參數估計值達到穩定為止。
極大似然估計具有許多優點, 具有一致性、漸進正態性和有效性等基本性質, 成為一種套用最為廣泛的參數估計方法, 但它也有兩條明顯的缺點: ( 1)沒有利用關於被試能力的先驗知識; ( 2)對於滿分和零分的被試無法進行參數估計。極大似然估計法又可細分為聯合極大似然估計法( JMLE ) 、條件極大似然估計法 ( CMLE ) 和邊際極大似然估計法 (MMLE)。
1. 聯合極大似然估計法 ( JMLE )
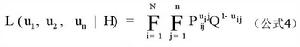 潛在特質理論
潛在特質理論在測量實踐中, 一般的情況是既不知道被試的能力 H,也不知道項目參數, 因此只能同時對這兩個參數進行聯合極大似然估計。該方法是 Birnbaum首先採用的,其基本公式如公式4: 其中 uij是考生 i 對反應模式為 ( 1, 2, 3, 4, 5)的第 j 題的反應。Pij表示能力為 Hi的被試答對第 j題的機率, Qij= 1- Pij表示能力為 Hi的被試答錯第 j 題的機率。
2. 條件極大似然估計法 ( CMLE )
這也是一種同時估計被試潛在特質水平參數與項目參數的方法。運用該方法的前提是得到能力參數的充分統計量。因為 Rasch模型的實得分數是被試能力參數的充分統計量, 所以, 對於 Rasch模型可以採用條件極大似然法進行參數估計。但是對於二值計分的雙參數模型和三參數模型以及多值計分模型都不能運用這一種方法, 以前, 該算法還只在少於 30或 40個項目的測驗中使用, 當項目數量超過 60個時, 參數估計過程將非常緩慢, 當項目數量超過 80個時, 條件極大似然估計方法失效。然而, 後來 Gusta2fasson已將這種方法加以發展並可運用到 80到 100個項目之多的測驗之中。
3. 邊際極大似然估計法 (MMLE )
對 Rasch模型來說, 條件極大似然估計的效果基本上和邊際極大似然估計相近。但邊際極大似然估計的一個最大缺點是運算量太大, 需要進行大量的積分運算, 因而只要項目數稍大一點, 這個方法就無法使用。
( 二 )貝葉斯估計法 ( Bayesian estimation)
為了克服極大似然估計的兩個缺點, 貝葉斯估計方法應運而生。貝葉斯估計方法是指利用貝葉斯原理, 確定項目參數和被試能力參數的先驗分布, 建立聯合極大似然函式, 然後通過求取聯合極大似然函式的極大值, 估計出項目參數和被試能力參數。貝葉斯估計的關鍵是指定各參數的先驗機率分布, 這一點對於能力參數似乎還有可能的, 因為如果對一個測驗使用的時間長了, 那么對被試相應能力的先驗機率分布還有可能做出較為客觀的估計, 但是對項目參數先驗機率分布的估計則純粹是主觀的。各參數的先驗機率分布確定之後, 貝葉斯估計和極大似然估計的方法大致是差不多的。貝葉斯估計方法運用於二值計分模型, 似乎還有可能, 但是對於等級計分模型, 由於每題有多個難度值, 而且這多個難度值有可能是逐漸增大, 也有可能是沒有變化規律的, 因此項目參數的先驗分布難以確定。貝葉斯估計方法運用到 IRT模型參數當中, 仍有許多理論上和技術上的問題未解決, 而且關於估計方法的穩定性還缺乏證據。
