
死鎖的規範定義:集合中的每一個進程都在等待只能由本集合中的其他進程才能引發的事件,那么該組進程是死鎖的。
 死鎖
死鎖一種情形,此時執行程式中兩個或多個執行緒發生永久堵塞(等待),每個執行緒都在等待被其他執行緒占用並堵塞了的資源。例如,如果執行緒A鎖住了記錄1並等待記錄2,而執行緒B鎖住了記錄2並等待記錄1,這樣兩個執行緒就發生了死鎖現象。
計算機系統中,如果系統的資源分配策略不當,更常見的可能是程式設計師寫的程式有錯誤等,則會導致進程因競爭資源不當而產生死鎖的現象。
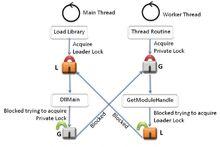
在兩個或多個任務中,如果每個任務鎖定了其他任務試圖鎖定的資源,此時會造成這些任務永久阻塞,從而出現死鎖。例如:事務A 獲取了行 1 的共享鎖。事務 B 獲取了行 2 的共享鎖。
排他鎖,等待事務 B 完成並釋放其對行 2 持有的共享鎖之前被阻塞。
排他鎖,等待事務 A 完成並釋放其對行 1 持有的共享鎖之前被阻塞。
事務 B 完成之後事務 A 才能完成,但是事務 B 由事務 A 阻塞。該條件也稱為循環依賴關係:事務 A 依賴於事務 B,事務 B 通過對事務 A 的依賴關係關閉循環。
 死鎖
死鎖除非某個外部進程斷開死鎖,否則死鎖中的兩個事務都將無限期等待下去。Microsoft SQL Server 資料庫引擎死鎖監視器定期檢查陷入死鎖的任務。如果監視器檢測到循環依賴關係,將選擇其中一個任務作為犧牲品,然後終止其事務並提示錯誤。這樣,其他任務就可以完成其事務。對於事務以錯誤終止的應用程式,它還可以重試該事務,但通常要等到與它一起陷入死鎖的其他事務完成後執行。
在應用程式中使用特定編碼約定可以減少應用程式導致死鎖的機會。有關詳細信息,請參閱將死鎖減至最少。
死鎖經常與正常阻塞混淆。事務請求被其他事務鎖定的資源的鎖時,發出請求的事務一直等到該鎖被釋放。默認情況下,除非設定了 LOCK_TIMEOUT,否則 SQL Server 事務不會逾時。因為發出請求的事務未執行任何操作來阻塞擁有鎖的事務,所以該事務是被阻塞,而不是陷入了死鎖。最後,擁有鎖的事務將完成並釋放鎖,然後發出請求底事務將獲取鎖並繼續執行。
 死鎖
死鎖不只是關係資料庫管理系統,任何多執行緒系統上都會發生死鎖,並且對於資料庫對象的鎖之外的資源也會發生死鎖。例如,多執行緒作業系統中的一個執行緒要獲取一個或多個資源(例如,記憶體塊)。如果要獲取的資源當前為另一執行緒所擁有,則第一個執行緒可能必須等待擁有執行緒釋放目標資源。這就是說,對於該特定資源,等待執行緒依賴於擁有執行緒。在資料庫引擎實例中,當獲取非資料庫資源(例如,記憶體或執行緒)時,會話會死鎖。
在示例中,對於 Part表鎖資源,事務 T1 依賴於事務 T2。同樣,對於 Supplier表鎖資源,事務 T2 依賴於事務 T1。因為這些依賴關係形成了一個循環,所以在事務 T1 和事務 T2 之間存在死鎖。
當表進行了分區並且 ALTER TABLE 的 LOCK_ESCALATION 設定設為 AUTO 時也會發生死鎖。當 LOCK_ESCALATION 設為 AUTO 時,通過允許資料庫引擎在 HoBT 級別而不是 TABLE 級別鎖定表分區會增加並發情況。但是,當單獨的事務在某個表中持有分區鎖並希望在其他事務分區上的某處持有鎖時,會導致發生死鎖。通過將 LOCK_ESCALATION 設為 TABLE 可以避免這種類型的死鎖,但此設定會因強制某個分區的大量更新以等待某個表鎖而減少並發情況。
產生條件
雖然進程在運行過程中,可能發生死鎖,但死鎖的發生也必須具備一定的條件,死鎖的發生必須具備以下四個必要條件。
1 )互斥條件:指進程對所分配到的資源進行排它性使用,即在一段時間內某資源只由一個進程占用。如果此時還有其它進程請求資源,則請求者只能等待,直至占有資源的進程用畢釋放。
2 )請求和保持條件:指進程已經保持至少一個資源,但又提出了新的資源請求,而該資源已被其它進程占有,此時請求進程阻塞,但又對自己已獲得的其它資源保持不放。
3 )不剝奪條件:指進程已獲得的資源,在未使用完之前,不能被剝奪,只能在使用完時由自己釋放。
4 )環路等待條件:指在發生死鎖時,必然存在一個進程——資源的環形鏈,即進程集合{P0,P1,P2,···,Pn}中的P0正在等待一個P1占用的資源;P1正在等待P2占用的資源,……,Pn正在等待已被P0占用的資源。
產生原因
競爭資源引起進程死鎖
當系統中供多個進程共享的資源如印表機、公用佇列的等,其數目不足以滿足諸進程的需要時,會引起諸進程對資源的競爭而產生死鎖。
可剝奪資源和不可剝奪資源
系統中的資源可以分為兩類,一類是可剝奪資源,是指某進程在獲得這類資源後,該資源可以再被其他進程或系統剝奪。例如,優先權高的進程可以剝奪優先權低的進程的處理機。又如,記憶體區可由存儲器管理程式,把一個進程從一個存儲區移到另一個存儲區,此即剝奪了該進程原來占有的存儲區,甚至可將一進程從記憶體調到外存上,可見,CPU和主存均屬於可剝奪性資源。另一類資源是不可剝奪資源,當系統把這類資源分配給某進程後,再不能強行收回,只能在進程用完後自行釋放,如磁帶機、印表機等。
競爭不可剝奪資源
在系統中所配置的不可剝奪資源,由於它們的數量不能滿足諸進程運行的需要,會使進程在運行過程中,因爭奪這些資源而陷於僵局。例如,系統中只有一台印表機R1和一台磁帶機R2,可供進程P1和P2共享。假定PI已占用了印表機R1,P2已占用了磁帶機R2,若P2繼續要求印表機R1,P2將阻塞;P1若又要求磁帶機,P1也將阻塞。於是,在P1和P2之間就形成了僵局,兩個進程都在等待對方釋放自己所需要的資源,但是它們又都因不能繼續獲得自己所需要的資源而不能繼續推進,從而也不能釋放自己所占有的資源,以致進入死鎖狀態。
競爭臨時資源
上面所說的印表機資源屬於可順序重複使用型資源,稱為永久資源。還有一種所謂的臨時資源,這是指由一個進程產生,被另一個進程使用,短時間後便無用的資源,故也稱為消耗性資源,如硬體中斷、信號、訊息、緩衝區內的訊息等,它也可能引起死鎖。例如,SI,S2,S3是臨時性資源,進程P1產生訊息S1,又要求從P3接收訊息S3;進程P3產生訊息S3,又要求從進程P2處接收訊息S2;進程P2產生訊息S2,又要求從P1處接收產生的訊息S1。如果訊息通信按如下順序進行:
P1: ···Relese(S1);Request(S3); ···
P2: ···Relese(S2);Request(S1); ···
P3: ···Relese(S3);Request(S2); ···
並不可能發生死鎖。但若改成下述的運行順序:
P1: ···Request(S3);Relese(S1);···
P2: ···Request(S1);Relese(S2); ···
P3: ···Request(S2);Relese(S3); ···
則可能發生死鎖。
2.進程推進順序不當引起死鎖
由於進程在運行中具有異步性特徵,這可能使P1和P2兩個進程按下述兩種順序向前推進。
1) 進程推進順序合法
當進程P1和P2並發執行時,如果按照下述順序推進:P1:Request(R1); P1:Request(R2); P1: Relese(R1);P1: Relese(R2); P2:Request(R2); P2:Request(R1); P2: Relese(R2);P2: Relese(R1);這兩個進程便可順利完成,這種不會引起進程死鎖的推進順序是合法的。
2) 進程推進順序非法
若P1保持了資源R1,P2保持了資源R2,系統處於不安全狀態,因為這兩個進程再向前推進,便可能發生死鎖。例如,當P1運行到P1:Request(R2)時,將因R2已被P2占用而阻塞;當P2運行到P2:Request(R1)時,也將因R1已被P1占用而阻塞,於是發生進程死鎖。
預防
理解了死鎖的原因,尤其是產生死鎖的四個必要條件,就可以最大可能地避免、預防和解除死鎖。只要打破四個必要條件之一就能有效預防死鎖的發生:打破互斥條件:改造獨占性資源為虛擬資源,大部分資源已無法改造。打破不可搶占條件:當一進程占有一獨占性資源後又申請一獨占性資源而無法滿足,則退出原占有的資源。打破占有且申請條件:採用資源預先分配策略,即進程運行前申請全部資源,滿足則運行,不然就等待,這樣就不會占有且申請。打破循環等待條件:實現資源有序分配策略,對所有設備實現分類編號,所有進程只能採用按序號遞增的形式申請資源。
所以,在系統設計、進程調度等方面注意如何不讓這四個必要條件成立,如何確定資源的合理分配算法,避免進程永久占據系統資源。此外,也要防止進程在處於等待狀態的情況下占用資源,在系統運行過程中,對進程發出的每一個系統能夠滿足的資源申請進行動態檢查,並根據檢查結果決定是否分配資源,若分配後系統可能發生死鎖,則不予分配,否則予以分配。因此,對資源的分配要給予合理的規劃。
下面幾種方法可用以避免重裝死鎖的發生:
①允許目的節點將不完整的報文遞交給目的端系統;
②一個不能完整重裝的報文能被檢測出來,並要求傳送該報文的源端系統重新傳送;
③為每個節點配備一個後備緩衝空間,用以暫存不完整的報文。
①、②兩種方法不能很滿意地解決重裝死鎖,因為它們使端系統中的協定複雜化了。一般的設計中,網路層應該對端系統透明,也即端系統不該考慮諸如報文拆、裝之類的事。③方法雖然不涉及端系統,但使每個節點增加了開銷。
有序資源分配法
這種算法資源按某種規則系統中的所有資源統一編號(例如印表機為1、磁帶機為2、磁碟為3、等等),申請時必須以上升的次序。系統要求申請進程:
1、對它所必須使用的而且屬於同一類的所有資源,必須一次申請完;
2、在申請不同類資源時,必須按各類設備的編號依次申請。例如:進程PA,使用資源的順序是R1,R2; 進程PB,使用資源的順序是R2,R1;若採用動態分配有可能形成環路條件,造成死鎖。
採用有序資源分配法:R1的編號為1,R2的編號為2;
PA:申請次序應是:R1,R2
PB:申請次序應是:R1,R2
這樣就破壞了環路條件,避免了死鎖的發生
銀行家算法
避免死鎖算法中最有代表性的算法是Dijkstra E.W 於1968年提出的銀行家算法:
銀行家算法是避免死鎖的一種重要方法,防止死鎖的機構只能確保上述四個條件之一不出現,則系統就不會發生死鎖。通過這個算法可以用來解決生活中的實際問題,如銀行貸款等。
程式實現思路銀行家算法顧名思義是來源於銀行的借貸業務,一定數量的本金要應多個客戶的借貸周轉,為了防止銀行家資金無法周轉而倒閉,對每一筆貸款,必須考察其是否能限期歸還。在作業系統中研究資源分配策略時也有類似問題,系統中有限的資源要供多個進程使用,必須保證得到的資源的進程能在有限的時間內歸還資源,以供其他進程使用資源。如果資源分配不得到就會發生進程循環等待資源,則進程都無法繼續執行下去的死鎖現象。
把一個進程需要和已占有資源的情況記錄在進程控制中,假定進程控制塊PCB其中“狀態”有就緒態、等待態和完成態。當進程在處於等待態時,表示系統不能滿足該進程當前的資源申請。“資源需求總量”表示進程在整個執行過程中總共要申請的資源量。顯然,每個進程的資源需求總量不能超過系統擁有的資源總數, 銀行算法進行資源分配可以避免死鎖。
解決方法
在系統中已經出現死鎖後,應該及時檢測到死鎖的發生,並採取適當的措施來解除死鎖。
死鎖預防。
這是一種較簡單和直觀的事先預防的方法。方法是通過設定某些限制條件,去破壞產生死鎖的四個必要條件中的一個或者幾個,來預防發生死鎖。預防死鎖是一種較易實現的方法,已被廣泛使用。但是由於所施加的限制條件往往太嚴格,可能會導致系統資源利用率和系統吞吐量降低。
死鎖避免。
系統對進程發出的每一個系統能夠滿足的資源申請進行動態檢查,並根據檢查結果決定是否分配資源;如果分配後系統可能發生死鎖,則不予分配,否則予以分配。這是一種保證系統不進入死鎖狀態的動態策略。
死鎖檢測和 解除。
先檢測:這種方法並不須事先採取任何限制性措施,也不必檢查系統是否已經進入不安全區,此方法允許系統在運行過程中發生死鎖。但可通過系統所設定的檢測機構,及時地檢測出死鎖的發生,並精確地確定與死鎖有關的進程和資源。檢測方法包括定時檢測、效率低時檢測、進程等待時檢測等。
然後解除死鎖:採取適當措施,從系統中將已發生的死鎖清除掉。
這是與檢測死鎖相配套的一種措施。當檢測到系統中已發生死鎖時,須將進程從死鎖狀態中解脫出來。常用的實施方法是撤銷或掛起一些進程,以便回收一些資源,再將這些資源分配給已處於阻塞狀態的進程,使之轉為就緒狀態,以繼續運行。死鎖的檢測和解除措施,有可能使系統獲得較好的資源利用率和吞吐量,但在實現上難度也最大。
排除方法
1、撤消陷於死鎖的全部進程;
2、逐個撤消陷於死鎖的進程,直到死鎖不存在;
3、從陷於死鎖的進程中逐個強迫放棄所占用的資源,直至死鎖消失。
4、從另外一些進程那裡強行剝奪足夠數量的資源分配給死鎖進程,以解除死鎖狀態
計算機網路的死鎖
死鎖是網路中最容易發生的故障之一,即使在網路負荷不很重時也會發生。死鎖發生時,一組節點由於沒有空閒緩衝區而無法接收和轉發分組,節點之間相互等待,既不能接收分組也不能轉發分組,並一直保持這一僵局,嚴重時甚至導致整個網路的癱瘓。此時,只能靠人工干預來重新啟動網路,解除死鎖。但重新啟動後並未消除引起死鎖的隱患,所以可能再次發生死鎖。死鎖是由於控制技術方面的某些缺陷所引起的,起因通常難以捉摸、難以發現,即使發現,也常常不能立即修復。因此,在各層協定中都必須考慮如何避免死鎖的問題。
存儲轉發死鎖及其防止
最常見的死鎖是發生在兩個節點之間的直接存儲轉發死鎖。例如,A節點的所有緩衝區裝滿了等待輸出到B節點的分組,而B節點的所有緩衝區也全部裝滿了等待輸出到A節點的分組;此時,A節點不能從B節點接收分組,B節點也不能從A節點接收分組,從而造成兩節點間的死鎖。這種情況也可能發生在一組節點之間,例如,A節點企圖向B節點傳送分組、B節點企圖向C節點傳送分組、而C節點又企圖向A節點傳送分組,但此時每個節點都無空閒緩衝區用於接收分組,這種情形稱做間接存儲轉發死鎖。當一個節點處於死鎖狀態時,所有與之相連的鏈路將被完全擁塞。
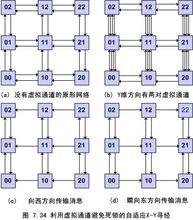
一種防止存儲轉發死鎖的方法是,每個節點設定M+1個緩衝區,並以0到M編號。M為通信子網的直徑,即從任一源節點到任一目的節點間的最大鏈路段數。每個源節點僅當其0號緩衝區空時才能接收源端系統來的分組,而此分組僅能轉發給1號緩衝區空閒的相鄰節點,再由該節點將分組轉發給它的2號緩衝區空閒的相鄰節點……最後,該分組或者順利到達目的節點並被遞交給目的端系統,或者到了某個節點編號為M的緩衝區中再也轉發不下去,此時一定發生了循環,應該將該分組丟棄。由於每個分組都是按照編號遞增規則分配緩衝區,所以節點之間不會相互等待空閒緩衝區而發生死鎖現象。這種方法的不足之處在於,當某節點雖然有空閒緩衝區,但正巧沒有所需要的特定編號的緩衝區時,分組仍要等待,從而造成了緩衝區和鏈路的浪費。
另一種防止存儲轉發死鎖的方法是,使每個分組上都攜帶一個全局性的惟一的"時間戳",每個節點要為每條輸入鏈路保留一個特殊的接收緩衝區,而其它緩衝區均可用於存放中轉分組。在每條輸出鏈路的佇列上分組按時間戳順序排隊。例如,節點A要將分組送到節點B,若B節點沒有空閒緩衝區,但正巧有要送到A節點的分組,此時A、B節點可通過特殊的接收緩衝區交換分組;若B節點既沒有空閒緩衝區,也沒有要送往A節點的分組,B節點只好強行將一個出路方向大致與A節點方向相同的分組與A節點互相交換分組,但此時A節點中的分組必須比B節點中的分組具有更早的時間戳,這樣才能保證子網中某個最早的分組不受阻擋地轉發到目的地。由此可見,每個分組最終總會成為最早的分組,並總能被一步一步地傳送到目的節點,從而避免了死鎖現象的發生。
重裝死鎖及其防止
•死鎖中比較嚴重的情況是重裝死鎖。假設發給一個端系統的報文很長,被源節點拆成若干個分組傳送,目的節點要將所有具有相同編號的分組重新裝配成報文遞交給目的端系統,若目的節點用於重裝報文的緩衝區空間有限,而且它無法知道正在接收的報文究竟被拆成多少個分組,此時,就可能發生嚴重的問題:為了接收更多的分組,該目的節點用完了它的緩衝空間,但它又不能將尚未拼裝完整的報文遞送給目的端系統,而鄰節點仍在不斷地向它傳送分組,但它卻無法接收。這樣,經過多次嘗試後,鄰節點就會繞道從其它途徑再向該目的節點傳送分組,但該目的節點已被死鎖,其周邊區域也由此發生了擁塞。
