
源流
軍事戰略家John Boyd在研究如何打勝仗時,創建了一種換裝模型OODA,即觀察(observe),定向(orient),決策(decide)和行動(act)。他認為獲勝需要兩件事,更好地收集和分析信息,並能夠對這些信息採取快速的行動。今天,這一模型幾乎適用於所有事情。
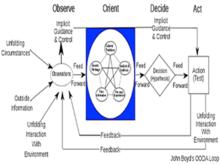 John Boyd's OODA Loop
John Boyd's OODA Loop日常生活中我們很容易被廉價、過剩的信息淹沒。Clay Johnson認為人們需要“信息節食”,有意識地選擇和浪費一些信息。同時,過去的20年,人類大部分的互動由物理接觸向數據交換轉變,當互動實現了數位化,速度更快,互動性更強,更容易被複製。大眾傳播可以做到和人際傳播一樣快,甚至更快,數位化意味著OODA模型的加速運轉。
“反饋經濟”是“信息經濟”的進一步發展。與智慧型手機捆綁每一個人,既是感測器,又是一個終端,在日常決策、工作生活中需要更好的方式觀察、定向,並作出快速的決策和行動,把所學所得的只是、經驗、技能反饋到日後的行為中。
我們正在進入“反饋經濟”時代。
原理
如“大數據供應鏈”圖所示,公司按照一定步驟收集、分析數據,繼而採取行動。其中的要素如下:
數據收集
第一步是獲取第一手的原始數據。信息的來源包括公共和私有的。網際網路是一個混雜的社會,隨著廉價數據交易市場的出現,幾乎任何數據都是可購買的。從社交網路上的情緒,天氣報告,到經濟指標,公共信息,都成了大數據磨機中的穀子。另外,我們還擁有組織特定的數據,如零售業務,呼叫中心流量,產品召回,或客戶忠誠度的指標。
收集的合法性也許比得到的數據限制更多。有些數據是嚴格管制的,如HIPAA管理醫療保健,而PCI限制金融交易。在其他情況下,結合數據的行為是違法的,因為它會泄露個人身份信息(PII) 。法院對IP位址是否屬於PII 有不同的裁定,像加州最高法院就認為郵政編碼屬於個人身份信息。這些法規嚴格限制了哪些數據可以被收集和聯繫。
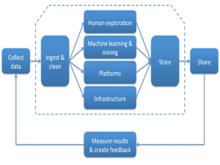 大數據供應鏈
大數據供應鏈計算機的普及意味著每個人都是一個潛在的數據來源。一個現代的智慧型手機可以感知光線,聲音,動作,位置,附近的網路和設備,以及更多,使其成為一個完美的數據採集器。消費者一旦選擇安裝或忠於某個應用程式,他們就成為感測器,向數據供應鏈提供數據。
攝取和清除
一旦數據被收集,它必須被攝入。在傳統的商務智慧型(BI )術語中,這就是所謂的提取,轉換和載入(ETL ) :把正確的信息放置資料庫模型中的正確位置並操縱特定的領域,使它們更易於使用。
然而,大數據的一個顯著特點,就是這些數據往往是非結構化的。這意味著我們在分析之前不知道的信息的固有模式。我們可以變換的信息的形式,比如用 一個城市的名稱替換IP位址,但保留的依然是原始數據,只能在分析的時候定義它的結構。
硬體
我們所攝入的信息需要通過人與機器進行分析。這意味著計算,存儲和網路等形式的硬體。大數據不會改變這一點,但它確實改變了如何使用硬體。例如,虛擬化,使運營商能夠同步虛擬運行多台機器,一旦處理結束,便摧毀這些機器。
雲計算也是大數據的福音。收費模式打破了許多組織因沒有前期投資不能參與大數據“遊戲”的障礙。在許多方面,大數據為雲提供了用武之地。
平台
大數據的新鮮之處在於在我們創建的平台和框架中快速壓縮大量的信息。加快數據分析的方法之一是將數據分拆成可以同步分析的塊。另一種方法是,建立一個文檔處理步驟的路徑,每個步驟對特定的任務進行最最佳化。
大數據常常需要迅速出結果而不僅僅是處理大量的數據。這一點很重要,原因有二:
大多數現今需要處理的大數據與用戶界面和網路有關。如建議哪種書好看,或得出搜尋結果或找出最好的航班等,這些均是要求在下載一頁紙的內容所需時間內給出答案。實現這種目標的唯一方法在於把任務分派出去。這就是為何谷歌有將近一百個伺服器的原因之一。
我們反覆地分析非結構化數據。正如我們首次探索資料集,不知道哪一項數據是重要的。如果按年齡劃分會怎樣?按國家過濾呢?按買價排序?按性別分別出結果?這種“如果”式的分析,本質上是探索性的;且只有分析員能自由發揮潛能進行探索時,他們的分析才有成效。大數據有可能非常龐大。但如果不迅速進行處理則這只是一堆晦澀難懂的數據而已。
機器學習
理解大數據的一種方法是,它是“比你可以經手的數據多更多“。 ”對於我們今天要分析的大部分數據,我們需要一台機器的幫助。
機器的幫助一部分發生在攝入階段。例如,自然語言處理器嘗試讀取非結構化的文本,並推斷出這是什麼意思:該Twitter的用戶高興還是難過?這家呼叫中心記錄好嗎?或者這個顧客生氣了嗎?
機器學習數據供應鏈中也很重要。在分析信息時,我們試圖噪音中尋找信號,辨別樣式。人類自己無法很好地找到信號。機器可以在比人類更低的信噪比中工作。
人類探索
儘管機器對數據分析很重要,人類眼睛和耳朵的作用是無法替代的。
提倡改善人機互動的先行者——柯越夫·梅普爾斯(Creve Maples),設計出利用幾十個獨立的數據源的系統,且在可操作的3D環境下對系統進行顯示,並輔之聲音和其他信號。梅普爾斯的研究表明,如果我們用這種方式輸入數據,分析員常不用花幾個小時,而是只需幾分鐘便能尋找到答案。
這種人機互動要求上述所闡明的速度與並行性;另外還需要新的界面和多重感應環境以便分析師與機器一起埋頭處理數據。
存儲
大數據需要大量的存儲空間。除了在其原始形式的實際信息,還有的轉換的信息。通常情況下,存儲是雲和內部預置存儲相結合,採用傳統的平面檔案資料庫和關係資料庫,以及後SQL存儲系統。
在分析過程中和之後,大數據的供應鏈需要一個倉庫。數據相比上一年同期的進度或隨時間的變化意味著我們必須保持一切的副本,使用算法和查詢不斷分析它。
共享和行動
如果不付諸於行動,所有的這些分析則是白廢心機。至於數據的收集,這不僅僅關係到技術——還涉及到法律法規、組織策略和付諸實驗的意願。分析得出的數據有可能與全世界共享也有可能被嚴加保護起來。
最佳企業與大數據聯姻則可做出所有的決定,不管是僱傭和解僱的決定,還是戰略規劃或市場信息定位等。儘管要收購能處理大數據的科技公司易如反掌,但要改變一家企業的文化卻難上加難。從許多方面看,採用大數據處理並不關乎擯棄硬體的問題而是關乎雇員是否要退休的問題。
每次信息技術要發生重大變革時,必然會出現一些似曾相識的拒絕變革的行為。大型主機、客戶服務端計算,封包式網路服務架構(packet-based networks)及網路等各新科技的誕生,無一例外面臨著詆毀者的攻擊。美國宇航局(NASA)研究了艾達(Ada)——第一個面向目標的語言——的失敗後,得出的結論是:該項目的支持者盲目樂觀自信,且缺乏一種支持性的生態系統以協助進一步推廣該語言。大數據及其旁系親屬——雲計算——有可能會遭遇類似的人為阻撓。
大數據思維是:實驗性的思維;冒的是已衡量過風險且快速地評估風險影響的思維。這與精益創業運動大同小異。這一運動提倡的是快速、反覆地學習並與顧客緊密聯繫。小企業能達到精益,是因為其處於發展初期且其緊貼市場的需求。但大型企業需要大數據和OODA循環以便做出有效應對並加速其循環。
大數據供應鏈是有組織的OODA迴環;是大企業應對精益創業企業的措施。
估量和收集反饋
正如約翰·博伊德(john boyd)的OODA循環大部分與循環有關,故大數據的大部分內容也與反饋有關。僅限於分析信息並無什麼特別的過人之處。為了運轉起來,組織必須從數據分析結果中選擇一條行動路線,之後觀察究竟發生了什麼,再利用這一信息收集新數據或用不同的方法進行分析。這是一個持續最佳化的過程。這一最佳化過程將影響到企業的方方面面。
影響
用數據代替一切
軟體正在影響著整個世界。一些垂直市場,包括出版、音樂、房地產和銀行曾設立很高的行業準入門檻。因消除了中間商,森嚴的壁壘也隨之被打破了。最後一架電影放映機於2011年結束了其使命,從相機至放映機都採用數位化製作電影。即便聯邦快遞(FederalExpress)已融入全球供應鏈,而郵局卻舉步維艱,原因在於沒人寫信。
那些用反饋系統來武裝自己的公司能以較低的成本創建更快更好的東西,從而將成為其所在行業的主宰。那些未能效仿的企業則快走到了生命盡頭,很快便成為僅供研究的案例並成為一段活生生的軼事。大數據、新界面和普適計算給我們的生活與工作方式帶來結構性的調整。
“反饋經濟”時代到來
大數據、持續的最佳化和一切以數據為中心不僅簡單地提高企業經營效率,而且還能作好準備迎接更大型、更重要的改變。他們預示著反饋經濟的到來。
用一個例子來說明。2013年初,三個斯坦福(Standford)大學的學生針對我們很多人都有的脊椎病的防治創立一個公司。脊椎病的形成與我們的坐姿有關。問題是我們經常意識不到坐姿有問題。 他們創造的解決方案是:製做一個感測器放在皮帶上,此感測器可時時監測我們的坐姿,並通過行動網路,傳輸到“雲中心”去。“雲中心”的伺服器不斷積累數據,通過經驗數據的比較分析,評估你的坐姿並計算出多長時間需要調整,然後將調整的信號發到你的手機上。不僅如此,它還可以將你坐姿狀態數據直接發給好友。你有很多朋友也帶這樣的設備,交友錄上(社交網路),大家共同知道彼此的狀態,進行分享、反饋和糾正。
這個小例子是說明利用移動網際網路、雲計算及大數據,來幫助你完成一個行為的糾正或調整。由小見大,這幾種看似分離的要素合到一起之後,一種新的經濟形態會出現。歷史上我們第一次能夠把做出的行為很快地反饋出來,而反饋的結果可以糾正我們的行為,小到個人,大到整個社會的經濟形態。其代表的經濟意義及商業模式的創新意義巨大。
首先我們的行為,無論是個體行為、群體行為,還是社會行為的調整與改變都是非常難的一件事情。最有效的方式就是反饋機制。而越有時效性的反饋就越富有意義。行為改變的有效方法也在於群體意識,尤其是與你相關的群體的反饋、共識的集體行動。上述的例子經由社交網路做到了這一點。
其次,雲計算將大規模數據不斷收集、積累、計算,將使計算模型具備學習能力,因而會越來越精確:即購買這種脊椎病糾正儀的人越多,收集的數據也越多,對你預警模型也就越精確,越有指導意義。
如果我們把這類技術套用推廣到多種設備,多個行業來看,我們對自己、對商業、對社會的認識、理解、反饋就會更有效,預測性更強,供給與需求的矛盾便更容易解決。
風險
加深對隱私的威脅
大數據時代,告知與許可、模糊化、匿名化這三大隱私保護策略都將失效。
首先,很多數據在手機的時候並無意用作其他用途,而最終產生了很多創新性用途。因此,公司無法告知個人尚未想到的用途,而個人亦無法同意未知的用途,“告知與許可”喪失了意義;
其次,如果所有人的信息已經在資料庫里,那么有意識地避免、模糊某些信息就是此地無銀三百兩。例如谷歌圖像採集受到了很多民眾抗議,因為害怕自己的房屋出現在圖片上。但是谷歌公司有意識地模糊化卻起到了反作用,因為這種模糊化可以被看到,反而突出了這些房屋的位置;
另外,隨著數據的增多,即使匿名,通過結合越來越多不同來源的數據,仍然可以確定到具體的個人。
運用大數據預測來判斷和懲罰人類的潛在行為
運用大數據分析人類的潛在行為,例如是否會實施犯罪,是否會生病,是否有能力償還貸款等。儘管能夠起到預防的作用,但是人類傾向於對預謀犯罪者實施懲戒。在犯罪之前將人逮捕、通過學歷判斷償貸能力的行為,將會引發許多社會問題。通過數據分析預判人的行為否定了人的自由權利,否定了法律系統或者說公平意識的基石——無罪推定原理,還會威脅到任何運用大數據預判未來行為的領域,如民事過失以及解僱員工的政策。
數據獨裁
過分地依賴於數據,將會忽視人類的主觀能動性,畢竟,卓越的才華並不依賴數據。就像標準化考試在很大程度上無法展示學生的全面素質,列出禁飛名單無法阻止恐怖主義一樣,數據無法解決所有問題。如果數據被誤用,就會加劇不良後果。
