
簡介
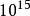 千兆級計算
千兆級計算千兆級計算是指一台計算機的峰值計算速度可以達到萬億次每秒。即一個PFLOPS(petaFLOPS)等於每秒一千兆(=)次的浮點運算。千兆級計算實現的最大推動力高性能計算和超級計算的需求。例如石油勘探、天氣預報等領域,還有社會上各種數據的不斷增長(大數據)都要求計算機有較快的計算速度。千兆級計算的實現需要有關技術支撐,如計算機水冷系統,主要解決計算機散熱問題。
每秒浮點運算次數
每秒浮點運算次數(每秒峰值速度)是每秒所執行的浮點運算次數( Floating-point operations per second; FLOPS)的簡稱,被用來估算電腦效能,尤其是在使用到大量浮點運算的科學計算領域中。因為FLOPS字尾的那個S代表秒,而不是複數,所以不能夠省略。
浮點運算實際上包括了所有涉及浮點數的運算,在某類套用軟體中常常出現,比較整數運算更用時間。現今大部分的處理器中都有浮點運算器。因此每秒浮點運算次數所量測的實際上就是浮點運算器的執行速度。而最常用來測量每秒浮點運算次數的基準程式(benchmark)之一,就是Linpack。
有關換算
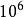 千兆級計算
千兆級計算一個MFLOPS(megaFLOPS)等於每秒一佰萬(=)次的浮點運算,
 千兆級計算
千兆級計算一個GFLOPS(gigaFLOPS)等於每秒拾億(=)次的浮點運算,
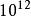 千兆級計算
千兆級計算一個TFLOPS(teraFLOPS)等於每秒一兆(=)次的浮點運算,
千兆級計算一個PFLOPS(petaFLOPS)等於每秒一千兆(=)次的浮點運算,
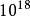 千兆級計算
千兆級計算一個EFLOPS(exaFLOPS)等於每秒一佰京(=)次的浮點運算。
超級計算
計算數學的重要概念:指超級計算機及有效套用的總稱。而超級計算機或稱巨型機(super computer)指能解決複雜計算的大型、非常快速、價格昂貴的計算機,通常這類機器還具有流水線部件和執行向量運算指令等功能。IDC(國際數據集團公司)關於超級計算與超級計算機之間差別的說法是:超級計算是用計算機去研究、設計產品及支持複雜的決策;而超級計算機則是解決上述問題的計算機.因此,超級計算不能混同於超級計算機,其內涵除了屬於最領先的計算硬體系統外,還應包括著軟體系統和測試工具、解決複雜計算的算法、套用軟體與通用庫等。
高性能計算(High Performance Computing, HPC ),指高性能計算機連同有效套用。而高性能計算機指傳統超高速計算機和多個CPU組成的並行計算機。
因此,可以說高性能計算蘊涵著超級計算而且比超級計算詞義更為廣泛。然而在實際使用上一般似乎不大區分這兩個詞。這裡指出,人們可以相仿地表述並行計算,以及並行計算與並行計算機之間的差別。
值得強調的是,上述說法中把高性能(或超級)計算機和有效套用兩件事擺在同樣重要的位置。一方面,如果沒有高性能計算機的迫切的非它不可的套用需求,發展高性能計算機就會沒有依據和市場。美國政府1991年制定“高性能計算與通信(HPCC)”計畫的核心正是確認和研究一組“重大挑戰”套用課題,這類課題涉及氣候與氣象、污染、材料、分子與原子、流體、燃燒等難以一一列舉,它們需要每秒萬億次的計算機,解決難度很大,日本政府也於1992年頒布“真實世界計算(RWC)"計畫,旨在模仿人類憑直覺判斷問題的方式,處理真實世界中那些模糊的、複雜的、不確定的信息,形成信息處理新風範,目標包括含100萬個處理機的並行計算機和有100萬個單元的神經網路系統。另一方面,即便有了高性能計算機和重大課題,也未必就能用好計算機有效解決課題。事實上多數高性能計算機好造不好用(或沒用好)而匆匆被載人史冊。因此,為發發展高性能計算,不能重硬(機器)輕軟(套用),必須給套用投資,檢驗其水平最終也應看解決了哪些重大課題。
有關技術
計算機水冷系統
計算機水冷系統,是計算機常用的液體冷卻系統。是指以高比熱係數的液體(如:水)作媒介,以協助帶走內部零件的熱量。一套完整的計算機水冷系統,一般會有:導熱金屬接觸面、
冷卻液、耐高溫軟水管、直流水泵、水流控制電路、溫度檢測電路、水位報警電路、散熱排。
而電子零件的工作熱量是以金屬接觸面傳導至冷卻液,經PU水管把加熱了的冷卻液流至散熱排處散熱降溫,水泵則在過程中不斷對液體加壓,使PU水管內液體不斷流動,就形成以液體循環冷卻的作用。
優點
循環冷卻作用下溫度波動小,被冷卻零件控溫效果明顯,長時間使用穩定可靠;
使用直流(無刷)電泵時振動小,噪音低;
整體裝配後外觀華麗,靜電吸附小。
缺點
水冷散熱器所需的加工工藝較高,且裝配後成品體積較大,占用了一定的空間;
因為系統結構繁複,且對配件質量有一定的要求,因而維保費用高;
配裝工藝較高,要求操作人員有一定的專業知識;
組成配件較多,成本較高。
安裝不當會令冷卻液流出,造成主機板短路。
非均勻訪存模型
非統一記憶體訪問架構(Non-uniform memory access, NUMA)是一種為多處理器的電腦設計的記憶體,記憶體訪問時間取決於記憶體相對於處理器的位置。在NUMA下,處理器訪問它自己的本地記憶體的速度比非本地記憶體(記憶體位於另一個處理器,或者是處理器之間共享的記憶體)快一些。
非統一記憶體訪問架構的特點是:被共享的記憶體物理上是分散式的,所有這些記憶體的集合就是全局地址空間。所以處理器訪問這些記憶體的時間是不一樣的,顯然訪問本地記憶體的速度要比訪問全局共享記憶體或遠程訪問外地記憶體要快些。另外,NUMA中記憶體可能是分層的:本地記憶體,群內共享記憶體,全局共享記憶體。
NUMA架構在邏輯上遵循對稱多處理(SMP)架構。它是在二十世紀九十年代被開發出來的,開發商包括Burruphs(後來的優利系統),Convex Computer(後來的惠普),義大利霍尼韋爾信息系統(HISI)(後來的Group Bull),Silicon Graphics公司(後來的矽谷圖形),Sequent電腦系統(後來的IBM),通用數據(EMC),Digital(後來的Compaq,現惠普)。這些公司研發的技術後來在類Unix作業系統中大放異彩,並在一定程度上運用到了Windows NT中。
首個基於NUMA的Unix系統商業化實現是對稱多處理XPS-100系列伺服器,它是由VAST公司的Dan Gielen為HISI設計。這個架構的巨大成功使HISI成為了歐洲的頂級Unix廠商。
矢量處理器
矢量處理器是專門設計的高度流水線作業的處理器。矢量處理器能夠對整個矢量個矩陣上行高效率的操作,這類處理器非常適合於能從高度並行執行中受益的應用程式。
