分類地址系統中的分組選路算法
分類地址系統中的典型分組選路算法如圖
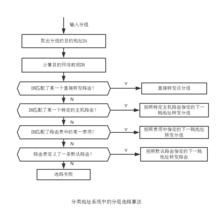 分組選路算法
分組選路算法帶有子網掩碼的分組選路算法
由於在IP的地址分配中引入了子網編址和CIDR技術後,分組的選路算法也需要進行相應的調整,為了支持子網編制和CIDR,分類地址系統中直接通過IP位址中的前三位確定地址的類型和網路前綴的長度的方式不再適用。吳類型的IP位址不再是自識別(Self-Identifying)的,僅從IP位址中無法確定網路前綴的長度,因此路由表中除了需要定義網路前綴意外,還需附加定義相應網路的子網掩碼。由於子網掩碼是可變長的,在選路算法中還需要子網掩碼確定目的地址中的網路前綴,以便進行路由查找,改進以後的分組選路算法如圖所示。
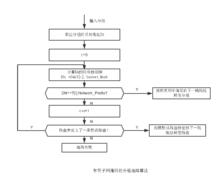 分組選路算法
分組選路算法混合選路算法
為了支持各種肯能的編制方式(分類地址、子網和CIDR),在實際的Internet中採用的是一種混合的選路算法,以便同時支持各種選路類型。由於存在著多種地址類型(分類的和無類型的)同時存在於路由表中,在進行路由表查詢時就不能簡單地使用上述兩種分組選路算法。這是由於在路由表中有不同類型的地址表項,存在著一個目的IP位址匹配了多個表項的可能性,而這些表項分別指向不同的路由。這種情況經常會發生,因為路由表中可能包含了對同一個網路的一般性的路由藐視和具體的路由描述。
選路決策時選擇,IP協定規定,在搜素路由表示採用最長前綴匹配表項來轉發。顯然從邏輯上看,使用最長前綴匹配才是最佳的分組選路的處理方式。
最長前綴匹配方式為路由表的搜尋帶來了一定難度,因為簡單的順序搜尋並不能夠高效地查找到路由表中的最佳匹配。當前Internet中的路由表都具有相當的規模,例如骨幹路由器中路由表項的數量超過10萬條,我們需要針對這個問題來設計快速的最長前綴匹配算法。算法的設計既需要考慮搜尋的速度,也需要最佳化存儲空間的使用。通常使用的算法是基於二叉樹的前綴匹配的最佳化算法,如Patricia的壓縮二叉樹(Level Compressed Trie)。
