
實現方式
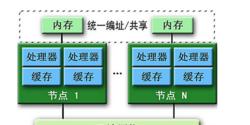 分散式共享記憶體
分散式共享記憶體DSM的實現有三種方式:
①用硬體實現。實際上是傳統的高速快取(cache)技術在可擴展體系結構中的延伸。
②作業系統和程式庫的實現方法,通過虛擬記憶體管理機制實現共享和一致性。
③編譯實現,自動將共享訪問轉變為同步和一致性原語。
複製問題
在DSM中,共享數據的位置可以是固定不動的、遷移的、複製的三種情況.複製要考慮解決以下幾個問題:
(1) 共享數據的粒度
數據的共享粒度是指系統對數據訪問故障複製的數據大小,不僅包括一次讀數據要傳輸多少數據,還包括一次寫數據會影響多少數據的有效性。一定的數據共享粒度可以使應用程式中的訪問開發其局部性,使多次訪問分擔傳送數據的開銷。
(2) 一致性協定
對於數據複製的情況有兩種基本的協定。即寫無效和寫更新協定.對於寫無效與寫更新的選擇,利用競爭算法可以有自適應的優點。其結果在某些情況達到最憂結果,最壞也不超過全用寫更新方式開銷的兩倍。
(3) 顛簸和替換
顛簸是指當兩個結點同時對數據頁進行寫訪問時引起的頁面在兩個結點之間頻繁的傳輸,這種情況嚴重影響了系統的性能。
存儲一致性(coherence)模型
有效地提供記憶體一致性是DSM系統的一個重要任務。為了能對存儲器的性能進行最佳化,即利用寫快取技術、存儲訪問重疊技術、流水線技術等嚴格的一致性,無法開發程式的語義,因而出現了減弱了的一致性模型。其目的是為了解決三個問題:減少昂貴的訊息傳送次數;掩蓋對非本地記憶體訪問的長等待時間;解決因為一致性單元而潛在引起的假共享問題。
已有的一致性模型有:原子一致性、順序一致性、處理機一致性、弱一致性、釋放一致性、進入一致性。
實現方法
硬體實現
具有單一匯流排的共享記憶體多處理機系統具有不易擴展的缺點。為了解決這個問題,DSM系統如DASH,WillowH,ASURA等在體系結構、處理機及記憶體的組織上有了變化.即由幾個處理機形成一個cluster,cluster內的處理機由匯流排相連,而cluster之間由互連網路相連,每個cluster有自己的共享記憶體。
另一種新的DSM的體系結構是COMA(cache only memory architecture),COMA的所有記憶體都是以大的cache形式組織的.這個記憶體除了作為處理機的cache以外,它也包括有它永遠不會訪問的共享數據,它既是一個cache又是一共享存儲的虛擬部分。
軟體實現
在軟體的開發上有三種途徑。
①在語言層上開發,比如雅典的OCCAM2++,通過預編譯器將對共享變數的訪問轉化為利用虛擬通道進行的通信原語。
②編譯實現,即將對共享變數的訪問轉化為向頁面所有者請求頁面的語句。
③在作業系統層實現,一般要通過對作業系統某些調用進行修改實現,比如IBM Research的DSVM6K就是對原有作業系統AIX v3作儘量少的修改完成的.IVY也屬於此類。
軟硬體結合
在系統實現中,硬體實現具有速度快的優點,但價格比較昂貴.軟體速度不如硬體快,但其價格相對比較便宜.因而要設計一個比較合算的系統,要考慮二者的結合.Limit—LESS系統的目錄實現中,硬體實現一定量的目錄項,少量的目錄可以存儲在其中.但當目錄項增大時,就要有一部分目錄存儲在記憶體中,由軟體進行相應的處理.在Galatica—Net的實現中,將性能比較關鍵的部分(寫更新)由硬體實現,而其它部分(如結點間頁面的共享)則由作業系統軟體實現.FLASH在死鎖的避免上,對於所需空間多於可使用的輸出佇列空間的訊息,設定軟體佇列,在輸出佇列有空閒空間時再從軟體佇列中將要傳送的訊息放在輸出佇列中.
