
擁塞成因
端到端TCP擁塞控制的本質思想是通過調整傳送端的傳送速率來控制網路的負荷量。具體地說,TCP不斷地通過加大傳送的速率來對當前網路的實際承載能力進行探測,並隨時準備對網路發回的擁塞信息做出回響,即迅速減小向網路中傳送信息的速率,並在新的起點上繼續對網路進行試探。
那么,是什麼原因導致數據吞吐量如此嚴重的下降呢?原來在TCP的控制機制裡面只考慮到了接收端的接收能力,但是受很多因素的影響無法考慮另一個很重要的方面,那就是網路自己的傳輸能力不足,從而造成了整個網路崩潰的發生。
就網際網路體系結構而言,網路擁塞必然會發生。因為在沒有進行任何預先請求(Prior Request)和協商(Prior Consult)許可機制的共享資源網路中,幾個數據分組可能會同時到達中間節點,並希望經同一個輸出連線埠同時轉發。顯然,不是所有數據分組都可以同時進行轉發,必須有一個服務順序。網路中間節點上的快取佇列為等候服務的數據分組提供一定的過載保護。然而如果此種狀態具有一定的持續性,當中間節點的快取佇列空間耗盡時,中間節點只有將後到的數據分組丟棄。從表面上看,增大快取佇列容量就可以防止由於網路擁塞引起的數據分組丟棄,但隨著快取佇列容量的增加,端到端的往返時延(RTT)也相應增大。而數據分組的傳輸持續時間是有限的,同時需要重傳逾時的數據分組。
正是由於這部分數據分組浪費大量的網路可用頻寬,過大的快取佇列容量反而可能妨礙網路擁塞的恢復。網路擁塞導致的直接結果是數據分組丟失率不斷提高、端到端時延不斷加大,甚至有可能使整個網路系統陷入癱瘓。當網路處於擁塞狀態時,即便只是微量的負載增量都可能使網路的有效吞吐量急劇下降。網路處於擁塞崩潰狀態時對網際網路產生的威脅可以追溯到其早期的發展中。
為了最大限度地利用資源,網路工作在輕度擁塞狀態時是較為理想的,但是如果沒有一定的擁塞控制機制加以約束和限制,必將增加滑向重度擁塞狀態的可能性。網路擁塞控制是確保網路魯棒性的關鍵因素,擁塞控制算法最基本和最重要的要求就是防止網路出現擁塞崩潰,使網路運行在輕度擁塞的最佳狀態,這樣擁塞控制模型或算法既能保證網路效率,又不會出現網路欠載或過載,同時又能保證流量間的公平性。
網路產生擁塞的根本原因是“供求關係”失衡,即網路負載大於網路資源容量和處理能力,結果導致數據包時延增加,丟失機率增大,套用系統性能下降等。
產生擁塞的原因可以歸結為以下幾方面。
(1)瓶頸鏈路快取容量不足。多個分組同時到達路由器,並期望經同一個輸出連線埠轉發時,分組序列自動進入中間節點的快取等待處理。如果這種情況持續發生,當快取空間被耗盡時,如果幾個輸入數據流共同需要同一個輸出連線埠,那么這些數據流在輸出連線埠上排隊等待。如果沒有足夠的存儲空間,數據包就會被丟棄,這對突發數據流更是如此。
(2)瓶頸鏈路頻寬容量受限。根據香農信息理論,任何信道頻寬最大值(即信道容量)為
式中, B為信道頻寬;Source為信源的平均功率;Noise為信道白噪聲的平均功率。
要求所有信源傳送的速率 R必須小於或等於信道容量 C。如果 R大於 C,則在網路低速鏈路處就會形成頻寬瓶頸,一旦鏈路滿足不了所有通過它的源端頻寬的需求時,網路就會發生擁塞。
(3)處理器處理能力受限。如果網路設備在執行排隊快取、更新路由表等功能時,處理速度跟不上高速鏈路,也會產生擁塞。雖然擁塞源於資源短缺,但增加資源並不能避免擁塞的發生,有時甚至會加重擁塞程度。當增加路由器快取時,表面上看可以防止與緩解由於擁塞引起的分組丟棄,但隨著快取的增加,端到端的時延也相應增大。因為分組的持續時間(life-time)是有限的,逾時的分組同樣需要重傳,因此,過大的快取空間有可能使總延遲超過端系統重傳計時器的值,從而導致分組重傳,這些分組白白浪費了網路的可用頻寬,反而會加劇網路擁塞。
(4)從套用的角度來看,多條流入線路可能會分組到達,並需用同一輸出線路。此時,如果路由器沒有足夠的記憶體來存放所有這些分組,那么有的分組就會丟失。
因此,為了解決網路擁塞問題,除了適當地增加快取容量、儘可能地增加鏈路頻寬和提高處理器的能力以外,還需要採用擁塞控制機制。
算法改進
1985年Nagle報告了由於傳輸控制協定(TCP)中沒必要的重傳所引發的網路擁塞崩潰。
1986年10月,從美國勞倫斯伯克利國家實驗室(Lawrence Berkeley National Laboratory,LBL,簡稱伯克利國家實驗室,隸屬於美國能源部,從事非絕密級的科學研究,坐落在加州大學伯克利分校的中心校園內,位於伯克利山的山頂,現由美國能源部委託加州大學代為管理)到加州大學伯克利分校(University of California,Berkeley,簡稱UC Berkeley)的數據吞吐量從32Kbps下降到40bps(具體內容請參考V.Jacobson的論文 Congestion Avoidance and Control)。這是被明確記載並研究的第一次網路擁塞崩潰事件。從這以後,TCP的研究課題就開始多了一個方向,那就是擁塞控制,因為擁塞控制算法對保證網際網路的穩定性具有十分重要的作用,其中以V. Jacobson的那篇論文為標誌開創了網際網路擁塞控制領域的工作。
這個事件的發生,也使得研究人員重新認識TCP傳輸的性能瓶頸。隨著技術的發展,網路在日常生活中成了必需品。越來越深入的研究發現,單純提高網路的傳輸頻寬,並不能提高網路傳輸性能。因此,如何提高網路傳輸性能,成了一個重要的研究課題。目前的研究主要涉及以下兩個主要方面:一方面,從網路本身出發,努力提高網路的頻寬,如目前在大型數據中心廣泛採用的萬兆乙太網、光纖網路等;另一方面各種傳輸控制理論層出不窮,儘量占用可用頻寬。
擁塞崩潰的發生嚴重降低網路的性能,自此,人們在擁塞控制領域開展了大量的研究工作。1986年Jacobson最早提出擁塞避免機制,並在其1988年的論文中做了詳細討論,慢啟動、快速重傳及擁塞避免算法構成了AIMD(Additive Increase Multiplieative Decrease)機制的基礎。1997年,這些算法合併作為RFC公布。在此基礎上後人經過十幾年的討論和研究,TCP的擁塞控制機製得到很大改進。
最初由V. Jacobson在1988年的論文中提出的TCP的擁塞控制由“慢啟動(Slow start)”和“擁塞避免(Congestion avoidance)”組成,後來TCP Reno版本中又針對性地加入了“快速重傳(Fast retransmit)”、“快速恢復(Fast Recovery)”算法,再後來在TCP NewReno中又對“快速恢復”算法進行了改進,出現了選擇性應答(selective acknowledgement,SACK)算法,還有其他方面大大小小的改進。擁塞控制機製成為網路研究的一個熱點。
算法發展
1994年,Brakmo提出了一種新的擁塞控制機制TCP Vegas,從數據包傳輸時間的角度來進行擁塞控制。但是,由於和已經廣泛使用的控制機制之間出現了競爭問題,因此並沒有得到廣泛的套用。
從此,TCP的擁塞控制進入了新的階段,百花齊放,出現了很多研究熱點,其中比較集中的方面有:“慢啟動”過程的改進,基於速率的擁塞控制,ECN,針對特殊網路(無線網路和衛星網路)的擁塞控制。最初提出了HSTCP,後來又出現了TCP BIC、TCP CUBIC、FAST TCP、TCPWestwood等一系列的改進,比較具有代表性的方案主要有針對高速網路的TCP BIC/CUBIC、High Speed TCP、Scalable TCP、MulTCP和針對媒體套用的TFRC等。該類算法沿用TCP Reno“丟包即擁塞”的傳統假設,只是對AIMD的擁塞控制視窗調節過程進行了最佳化。儘管這些最佳化改進在某種程度上提高了TCP Reno的擁塞控制協定性能,但是Reno算法在無線網路中的傳輸性能問題同時也被繼承了下來,限制了該類方案在無線網路環境中的部署和套用。
另一類擁塞控制方案採用數據包在網路瓶頸節點緩衝區中的排隊延遲(即由擁塞造成的網路延遲增加量),作為網路擁塞的信號。當網路中的分組數量超出了網路瓶頸節點的傳輸能力時,網路轉發節點並不會馬上將多餘的分組丟棄,而是將其暫時保存在自身的緩衝區中進行排隊等待。數據包在轉發節點的緩衝區中堆積排隊,將會引起網路端到端延遲的增加,基於延遲的擁塞控制方案就根據延遲的增加量,設計不同的算法來控制網路擁塞。典型的基於延遲的擁塞控制方案主要有TCP vegas和FAST TCP等。
為了綜合利用這兩類擁塞控制方案的優勢,研究人員們提出了混合型擁塞控制方案,比較典型方案的有針對無線網路的TCP Veno、TCP Westwood/Westwood+方案,以及針對高速網路的Compound TCP、H-TCP、TCP Illinois、UDT和針對媒體傳輸套用的TFRC Veno等。
概念術語
擁塞現象是指到達通信子網中某一部分的分組數量過多,使得該部分網路來不及處理,以致引起這部分乃至整個網路性能下降的現象,嚴重時甚至會導致網路通信業務陷入停頓即出現死鎖現象。
(1)擁塞視窗(cwnd):擁塞控制的關鍵參數,控制源端在擁塞情況下一次最多能傳送多少個數據包。
(2)接收視窗(rwnd):接收端對源端傳送視窗大小所做的限制,在建立連線時接收方通過ACK確認帶給源端。
(3)通告視窗(awnd):接收方TCP快取當前的大小,此視窗就是TCP核心的緩衝區大小,通常要求其為MSS的偶數倍。
(4)慢啟動閾值(ssthresh):擁塞控制中用來限制傳送視窗大小的閾值,它是慢啟動階段與擁塞避免階段的分界點,初始值設為65535B或awnd的大小。
(5)往返時延(RTT):從傳送端傳送數據開始,到傳送端接收到來自接收端的確認(接收端接收到數據後便立即傳送確認),總共經歷的時延。
(6)逾時重傳計時器(RTO):描述數據包從傳送到失效的時間間隔,是源端用來判斷數據包是否丟失和網路擁塞的重要參數,通常設為2RTT或5RTT。
(7)頻寬時延乘積(Bandwidth Delay Product,BDP):表示一個連線的通道容量,表示為BDP = Capacity(b) = Bandwidth(b/s)*RTT(s)。
TCP實現
最早的TCP使用簡單的停等協定,每傳送一個報文段都要等待收到確認,才能順序傳送下一個報文段,因此效率很低,網路資源不能得到充分利用。如果發生報文段丟失,必須等待重傳定時器逾時才能重新傳送丟失的報文段,對網路擁塞沒有採取有效的措施。
具體的實現,可以參考第1章的數據鏈路層的介紹。
Tahoe
Tahoe算法是TCP的早期版本。它的核心思想:讓cwnd以指數增長方式迅速逼進可用信道容量,然後慢慢接近均衡。Tahoe 包括3 個基本的擁塞控制算法:“慢啟動”、“擁塞避免”和“快速重傳”。同時Tahoe算法實現了基於往返時間的重傳逾時估計。
(1)TCP Tahoe在連線建立後,cwnd初始化為一個報文段,開始慢啟動,如果沒有丟包和擁塞發生,直到cwnd等於ssthresh,然後進入擁塞避免。
(2)若重傳定時器逾時,cwnd重新設定為一個報文段大小,重新開始慢啟動,同時ssthresh為當前cwnd的一半。
(3)若傳送端收到3個重複ACK,不等到重傳定時器逾時就執行快速重傳,即立刻重傳丟失的報文段。
重傳逾時估計是對重傳定時器的逾時時間取值的估計。重傳定時器是判斷報文段丟失的依據,傳送端傳送一個報文段同時啟動重傳定時器,如果重傳定時器逾時,但傳送端還沒有收到接收端的ACK,就判斷該報文段丟失,重傳丟失報文段並重新啟動重傳定時器。每一個TCP連線都維護一個變數,用於計算往返時間RTT。TCP採用動態重傳逾時估計,即以往返時間RTT為基礎來確定重傳逾時時間。其中最常用的是設定重傳逾時時間為往返時間RTT的兩倍,即
重傳逾時時間= 2×RTT
另外,往返時間RTT的計算也是動態的,通常可以按下列式子計算:
RTT= a×最近RTT+(1- a)×當前RTT
其中, a的取值為0~1,一般取值0.8~0.9。
在檢測到報文段丟失後,希望能迅速地將該報文段重傳,減少不必要的等待時間,提高TCP的吞吐量。如果設定重傳逾時時間等於往返時間RTT,那么當網路中的時延變化引起當前往返時間RTT值略大時,就會使重傳逾時時間小於往返時間RTT,導致不必要的重傳,因此一般使用重傳逾時時間為往返時間RTT的兩倍。
Tahoe算法的不足之處在於,收到3個重複ACK或在逾時的情況下,Tahoe設定cwnd為1,然後進入慢啟動階段。這一方面會引起網路的激烈振盪,另一方面大大降低了網路的利用率。
Reno
針對Tahoe算法的不足,提出了Reno算法,主要有兩方面改進:一是對於收到連續3個重複的ACK確認,算法不經過慢啟動,而直接進入擁塞避免階段;二是增加了快速重傳和快速恢復機制。Reno算法以其簡單、有效和魯棒性好成為TCP控制算法的主流,被廣泛套用。
TCP Reno在TCP Tahoe版本上加入“快速恢復”算法。TCP Reno中,如果傳送端收到3個重複ACK,不必等到重傳定時器逾時,就會執行快速重傳,然後執行快速恢復算法,進入擁塞避免。
TCP Reno的狀態轉換圖如圖1所示。
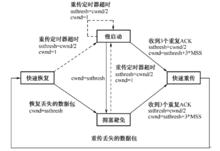 圖1 TCP Reno狀態轉換圖
圖1 TCP Reno狀態轉換圖儘管Reno算法對Tahoe算法做出了改進,但Reno算法仍然存在不足。
(1)首先傳送端在檢測到丟包或擁塞後,重傳從數據丟失到檢測到丟失這段時間傳送端傳送的所有報文段,但是其中有些報文段被接收端正確收到,可以不必重傳。
(2)其次,準確測量往返時間RTT是很重要的。理論上往返時間RTT的測量比較簡單,是指報文段從發出到ACK返回傳送端的時間,但是由於TCP是使用一個ACK確認所有已經收到的報文段的“累積”確認方式,往返時間RTT的估值在實際中往往比較複雜,因此準確測量往返時間RTT也是研究問題之一。
(3)Reno算法的另一個不足之處在於,它不能有效地處理多個報文分組從同一數據視窗丟失的情況。
NewReno
TCP NewReno的主要改進在於一個視窗內多個報文段丟失的問題。這樣可以避免TCP Reno中的多次重傳逾時。另外,TCP NewReno算法在快速恢復中引入了部分確認(Partial ACK)。它在快速恢復階段到達並且確認新數據,但它只確認進入快速重傳之前傳送的一部分數據。
部分確認是指在快速恢復階段對新報文段的確認(不包括還在傳輸中未接收到的數據)。在Reno中,部分確認導致離開快速恢復狀態,即傳送端收到一個不重複的ACK就退出快速恢復階段。在NewReno中,只有當所有報文段的ACK都收到後才退出快速恢復。
具體來說,就是重傳定時器溢出或者重複地確認ACK到達時,TCP Reno會退出快速恢復狀態,等待,但是TCP NewReno並不退出快速恢復狀態,而是按以下步驟執行。
(1)重傳緊接著那個部分確認ACK之後的報文段,擁塞視窗減去部分確認ACK的大小;
(2)對於得到確認的新數據,設定cwnd等於其加上SMSS:
(3)對於第一個或每一個Partial ACK,重傳定時器復位。
舉例說明,序號為1的報文段丟失了,TCP傳送端又傳送了序號為2、3、4、5的報文段之後才收到3個重複的ACK。進入快速重傳,重傳序號為1及其之後的報文段,然後進入快速恢復,等待序號為1的報文段的ACK。此時,TCP傳送端記錄序號為5,就是說TCP傳送端希望收到序號為6的ACK。如果收到序號為6的ACK,那么這個ACK就確認了重傳之前的所有報文段。
但是如果收到序號小於6的ACK,那么這個ACK只是確認了重傳之前的部分報文段,也就說明此時丟失了多個報文段,這個ACK就是部分確認的ACK。例如,收到序號為3的ACK,那么能夠確定序號為1的丟失的報文段和序號為2的報文段重傳後都被接收到,也說明序號為3的報文段也丟失了,需要重傳。
如果執行TCP Reno算法,收到部分確認的ACK即序號為3的ACK就退出快速恢復回到擁塞避免,然後收到3個重複的序號為3的ACK再進入快速重傳,重傳序號為3的報文段再進入快速恢復。這樣TCP傳送端不僅增加了傳送的時間,而且擁塞視窗一直重複地減半,如果丟失的報文段更多的話,整個TCP的吞吐量就會變得很低。
如果執行TCP NewReno算法,收到部分確認的ACK即序號為3的ACK就繼續進行快速重傳,重傳序號為3的報文段,然後繼續快速恢復,如果還有報文段丟失,那么重複這個過程。這樣TCP傳送端傳送時間縮短,而且避免了擁塞視窗不必要的減小。
SACK
TCP SACK(Selective Acknowledgement)也是對TCP Reno的改進,當檢測到擁塞後,不必重傳從數據丟失到檢測到丟失這段時間傳送端傳送的所有報文段,而是對這些報文段進行有選擇的確認和重傳,避免不必要的重傳。
在連線建立階段,傳送端和接收端進行“協商”,確定是否使用SACK選項。SACK選項需要在TCP報文段中設定標識位,標識接收端最近收到的序列號連續的三個報文段。如果使用SACK選項,那么在數據傳輸中,當接收端快取佇列中出現序號不連續的報文段時,就向傳送端傳送標識SACK選項的重複ACK。傳送端得知哪些報文段已經被接收,哪些報文段丟失,從而選擇性地重傳丟失的報文段。
SACK選項已經成為Linux系統的標準選項,在目前的系統部署中,這個標準選項通常都已經選中。
Vegas
1994年,Brakmo提出了TCP Vegas算法。TCP Vegas是一種截然不同的擁塞控制算法,它採用一種更巧妙的頻寬估計策略,根據期望的流量速率與實際速率的差估計網路瓶頸處的可用頻寬。
Vegas算法根據觀察到的TCP連線中RTT值的改變來控制擁塞視窗。如果RTT變大,TCP Vegas就認為網路發生了擁塞,減小擁塞視窗;反之,則增大擁塞視窗。
TCP Vegas改進了其中三種算法,簡要介紹如下。
(1)新的快速重傳算法。它將引發重傳的重複ACK數量從三個減少為兩個或者一個,因此TCP能夠對報文段丟失做出更快速的反應。
(2)新的擁塞避免算法。它改變了其他實現版本中通過報文段丟失來檢測網路擁塞的基本思想,而是通過觀察已傳送報文段的往返時間RTT的變化來判斷網路的擁塞狀況,即如果觀察到往返時間RTT變大,認為網路開始擁塞,因此減小擁塞視窗;相反,則認為網路暢通,增大擁塞視窗。
(3)新的慢啟動算法。改進後每隔一個往返時間RTT內擁塞視窗增大一倍,在這之間視窗固定不變。
由於TCP Vegas只和往返時間RTT的改變有關,所以往返時間RTT的準確度非常重要。實際過程中採取了許多措施來保證往返時間RTT測量的精確度,如細粒度的時間計算等。同時,TCP報文段大小也會對往返時間RTT有一定影響。
Veno
有線網路主要是由於擁塞產生數據包的丟失,稱為擁塞丟包。無線網路存在高誤碼率,無線信道由於噪聲、鏈路錯誤而產生頻繁的數據包丟失,稱為隨機丟包。在無線網路中,TCP錯誤地將隨機丟包當成擁塞丟包,採取不必要的擁塞控制,降低數據傳送速率,引起吞吐量下降。如何區分擁塞丟包和隨機丟包並採取相應的策略是無線網路中TCP的研究重點。
TCP Veno是基於Reno、Vegas這兩個版本提出的。它通過對擁塞避免、快速重傳和快速恢復的改進,判斷無線網路中的擁塞狀況,採取不同的擁塞控制策略,提升無線網路的性能。當TCP Veno認為網路的丟包是由於高誤碼率造成的時候,就採用改進的擁塞控制機制;相反,當網路的狀態處於擁塞時,就採用傳統的TCP擁塞控制機制。TCP Veno提升了TCP在單跳無線網路中的性能,大量研究已經表明,TCP Veno在蜂窩通信網路中性能得到較好的提升。
Vegas通過計算期望吞吐量和實際吞吐量的差值來估計網路瓶頸處的可用頻寬。Veno採用這種策略來判斷網路中連線是否處於擁塞狀態。
Veno在傳送端測量兩個速率,一個是傳送速率的期望值(Expected),另一個是傳送速率的實際值(Actual),計算公式如下:
Expected = cwnd/BaseRTT
Actual=cwnd/RTT
式中,cwnd是當前的傳送視窗大小,BaseRTT是測量到往返時延中的最小值,RTT是最近一次測量到的往返時延值,兩者間的差值定義為Diff:
Diff = Expected - Actual
當RTT>BaseRTT時,表明網路的瓶頸頻寬處堆積了數據包。如果用 N來表示該處堆積的數據包個數,則有如下表達式:
RTT = BaseRTT + N/Actual
上式右側表示網路瓶頸處的數據包堆積會引起往返時延的增加。重新整理後,可得到如下表達式:
N= Actual×(RTT-BaseRTT) = Diff×BaseRTT
TCP Veno中設定一個閾值 b,通過比較 N和 b判斷是否發生了擁塞,即區分隨機丟包和擁塞丟包。如果 N超過閾值 b,認定原因是擁塞丟包;反之,則認定為隨機丟包。經過實驗證明,閾值 b取3比較合理。
(1)TCP Veno的擁塞避免算法採取如下策略:
當cwnd>ssthresh時,即進入擁塞避免階段時,
如果 N< b,發生隨機丟包,則每收到1次新的ACK,使cwnd=cwnd+1/cwnd;
否則 N ≥ b,發生擁塞丟包,則每2次收到新的ACK,使cwnd=cwnd+1/cwnd。
在發生隨機丟包和擁塞丟包兩種不同情況下,TCP Veno對cwnd的線性增加採取不同的控制策略。如果判斷發生隨機丟包,則cwnd線性增加的程度和TCP Reno一樣;如果判斷發生擁塞丟包,則cwnd線性增加的程度減緩。因為在預測網路中可能存在擁塞時,減緩cwnd的線性增加,即減緩數據傳輸速率的增加,可使得連線能夠儘可能長時間地處於較大的視窗值,從而提高TCP的效率。
(2)TCP Veno的快速重傳和快速恢復算法採取如下策略:
如果 N< b,此時發生隨機丟包,則使ssthresh=cwnd×(4/5),cwnd=ssthresh+3;
否則 N ≥ b,表示發生擁塞丟包,則使ssthresh=cwnd/2,cwnd=ssthresh+3。
TCP傳送端確認數據包丟失依據兩種情況:一是重傳定時器逾時;二是收到3個及以上重複的ACK。快速重傳是指收到3個重複ACK就確認數據包丟失,然後重傳丟失的數據包並調整cwnd和ssthresh的大小,快速重傳之後執行快速恢復。所以如果判斷發生隨機丟包,則只是適度降低閾值ssthresh,可以使連線從一個較大的視窗值開始執行擁塞避免,提高TCP吞吐量;若判斷發生擁塞丟包,則將閾值ssthresh減半,減小視窗緩解擁塞。
無線環境的高誤碼率對TCP性能產生很大影響。因為高誤碼率引起數據包丟失,通常被認為是擁塞,採取擁塞控制機制,但是實際網路中並沒有擁塞產生。所以頻繁的擁塞控制降低了傳輸速率,導致吞吐量下降。TCP Veno採取測量網路擁塞狀況的方法,判斷擁塞丟包還是隨機丟包,採取不同的擁塞控制機制。新的擁塞控制機制針對隨機丟包儘量保持傳輸速率,適當減小擁塞視窗,提升吞吐量。
BIC
TCP BIC由北卡羅來納州立大學(North Carolina State University)的網路研究實驗室提出,該算法在提出不久後就成為了當時Linux核心中的TCP默認擁塞算法。
BIC的提出者們發現了TCP擁塞視窗調整的一個本質問題:那就是找到最適合當前網路的一個傳送視窗。為了找到這個視窗值,一般擁塞控制算法採取的策略是緩慢探測,也就是每個RTT加1,緩慢上升,丟包時下降一半,接著再來慢慢上升。BIC算法的提出者們則直指事情的本質,認為這是一個搜尋過程,可以認為這個值是在1和一個比較大的數之間,那么顯然最好的方式就是二分搜尋。
基於這樣一個二分思想,BIC算法這樣操作的:當出現丟包的時候,說明最佳視窗值應該比這個值小,那么BIC就把此時的cwnd設定為max_win,把乘法減小後的值設定為min_win,然後BIC就開始在這兩者之間執行二分思想——也就是跳到max_win和min_win的中點。
BIC算法主要有以下兩個不足之處。首先,就是搶占性較強,在小鏈路頻寬時延短的情況下,比起標準的TCP Reno,BIC的增長函式的搶占性強。它在探測階段相當於重新啟動了一個慢啟動算法,而TCP在處於穩定後視窗就一直是線性增長的。其次,BIC的的視窗控制階段較為複雜,增加了算法上的實現難度,同時增加了分析協定性能的模型的複雜度。
CUBIC
在BIC提出後不久,北卡羅來納州立大學的研究人員根據BIC的一些缺點,再次提出了CUBIC算法,CUBIC不是簡單地修正BIC存在的問題,而是對整個算法都做了較大的調整。
CUBIC在設計上簡化了BIC的視窗調整算法,CUBIC的模型使用了一個三次函式(即立方函式)。在三次函式曲線中同樣存在一個凹和凸的部分,該曲線形狀和BIC模型的曲線圖十分相似。另外,CUBIC中最關鍵的點在於它的視窗增長函式僅僅取決於連續的兩次擁塞事件的時間間隔值,從而視窗增長完全獨立於網路的往返時延RTT。由此CUBIC的RTT獨立性質使得CUBIC能夠在多條共享瓶頸鏈路的TCP連線之間保持良好的RTT公平性。鑒於CUBIC更出色的表現,在Linux 2.6.18版本後,CUBIC取代了BIC,成為默認的TCP算法。
當然,CUBIC也有其缺點,例如,在凸增長階段的快速增長可能導致網路流量的突發性,從而造成一定的丟包。
FAST
TCP Vegas由於使用排隊延遲作為網路擁塞的唯一標識信號,因此在應對無線網路的隨機丟包問題上有著先天的優勢。但是對於高延遲頻寬積(Bandwidth Delay Product,BDP)的高速網路,TCP Vegas每個RTT最多增加1的擁塞視窗增長速度過於緩慢。針對這一問題,加州理工學院的Steven Low教授提出了一種改進的Delay Based TCP擁塞控制算法,稱為FAST TCP (FAST AQM Scalable TCP)。和TCP Vegas相同,FAST TCP也使用網路的排隊延遲作為鏈路擁塞的唯一標識信號,並使用如下方程對傳送端的擁塞控制視窗進行調節。
其中, a和 g為預設參數,根據網路頻寬的不同 a的設定範圍為20~200,而1> g>0。
根據上面的公式可知,FAST TCP在網路排隊延遲增大時也會自適應地降低連線的數據傳輸速率。相比TCP Vegas,FAST TCP每次最多可以將擁塞控制視窗增加 g· a,因此更加適合高速網路的套用場景。
Fast TCP後來沒有對開源社區做貢獻了,因為Steven Low自己創辦了公司,把Fast TCP變成了商業產品,所以後續的學術研究就比較少了。Fast TCP是從TCP Vegas的思想發展而來,利用網路延時進行擁塞判斷。基於延遲的算法是對整個網路的擁塞控制有好處的,但是相對當前基於丟包的算法來說,兩者不公平。所以估計Steven Low後面也做了很多的改進。
Compound
Compound TCP是微軟亞洲研究院的譚焜博士提出的一種混合型TCP擁塞控制算法。該算法的設計思想是結合基於時延的算法和基於丟包的算法的優點,在充分利用高速網路頻寬的同時,仍然保持和傳統TCP Reno算法的公平性。
Compound TCP的擁塞控制模組中包含有兩個不同的擁塞控制視窗,即基於丟包的 w視窗和基於延遲的 w視窗,而算法的數據包傳送速率則由兩個視窗的總和 w= w+ w控制。 w視窗的更新方法和TCP Reno相同,遵循AIMD算法。而 w則利用網路的排隊延遲作為擁塞控制信號,依靠一種延遲控制的高速TCP算法進行視窗更新,其更新過程為
w= w+ a× w– 1, if diff < g
w= w– x ×diff, if diff ≥ g
w*(1 – b) – w/2, if loss
其中, a, b, g, ξ均為預設的參數,diff採用和TCP Vegas相同的計算方法。從式中可以看出,當diff小於一定值時,Compound TCP會像HighSpeed TCP一樣以指數形式增加其擁塞控制視窗,而當diff達到一定閾值時,又會像TCP Vegas一樣在擁塞丟包發生前將視窗降低。採用這種方法,Compound TCP除了可以在高速網路中保持較高的傳輸速率之外,還可以在低速網路中兼顧同TCP Reno的公平性。
