1. PTN的層次化OAM
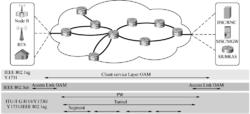
PTN相對於傳統的分組設備,強化了OAM能力。PTN技術的層次化OAM情況如圖1描述。
 PTN的運行維護
PTN的運行維護圖1 PTN的層次化OAM
在客戶業務層面,可以採用IEEE 802.1ag或ITU Y.1731進行監視,同時採用IEEE 802.3ah進行鏈路狀態監視,這部分PTN與傳統的分組設備無明顯區別,但在PW、Tunnel、Segment幾個層次,PTN借鑑了SDH OAM的思想,支持豐富的告警、性能監視。下面介紹幾種主要的OAM。
1)故障管理OAM
® CC:連續性和連通性檢查。
® AIS/FDI:前向缺陷指示,FDI報文由第一個檢測到缺陷的節點產生並向下游傳送,報文中會攜帶缺陷的類型和位置,其主要目的是抑制受影響的客戶LSP層產生告警。
® BDI:後向缺陷指示,LSP的宿端節點檢測到缺陷後,使用BDI報文,沿反向路徑將缺陷告知上游的源端節點。
® LoopBack (LB):環回功能,用於進行手動雙向連通性檢測。
® Test (TST): 測試,用於單向手動執行診斷測試,可以測試頻寬吞吐量、丟包和比特錯誤。丟包也可以通過性能部分的雙LM來完成。
® LCK:鎖定功能,由一個OAM端點向對端OAM點或者客戶層傳送LCK報文完成,用於OAM端點通告其管理鎖定的動作以及因此而發生的業務中斷,其主要目的是抑制受影響的客戶層或對端OAM點的告警。
® CSF:客戶信號失效,用於在檢測到ingress 端客戶業務信號失效時,傳遞客戶失效信號到 egress 端,以便 egress 端向客戶業務層傳送告警壓制信號(AIS)。
2)性能管理OAM
® Dual-end LM(雙端丟包(/丟包率)測量)/Single-end LM(單端丟包(/丟包率)測量):用於定時雙向和手動單向檢測丟包和丟包率。
® One-way DM(單程時延/時延抖動測量)/Two-way DM(雙程時延/時延抖動測量):用於定時雙向和手動單向檢測丟包和丟包率時延/時延抖動。
3)其他OAM
® APS:自動保護倒換,當其中一條鏈路出現故障時自動倒換到備用鏈路。
® MCC:管理信息通道,用於在 OAM 兩個端點傳送管理信息。
® SCC:信令通信通道,用於在 OAM 兩個端點間的控制層面通信。
® SSM:同步信息訊息,用於在兩個節點間傳送狀態信息,對同步狀態的具體意義不作規定。
2. 網路故障處理的基本思路和方法
PTN的組網、業務配置複雜,需網管儘快做好SDH-Like功能。為儘快恢復業務,將檢測的故障點最小化,需了解SDH原理、IP網路原理知識、告警信號流及告警產生機理、PTN設備和網管基本操作、常用儀表的基本操作,了解網路拓撲、業務配置、設備運行狀態。
網路故障處理的方法大致有3類。
® 告警、性能分析法;
® OAM/PING調試法;
® 環回法。
PTN對於Tunnel的故障可用MPLS OAM來檢測,MPLS OAM包括CV/FFD、Ping和Traceroute。通過CV(Connectivity Verification)/FFD(Fast Failure Detection)檢測可以檢測LSP的連通性。CV檢測和FFD檢測的過程基本一致,其不同在於CV檢測傳送CV報文的頻率固定為1幀/秒,並且不可設定,而FFD檢測傳送FFD報文的頻率是可以自行定義的。MPLS Ping/Traceroute為用戶提供了發現LSP錯誤,並及時定位失效節點的機制。MPLS Ping/Traceroute使用MPLS Echo Request和MPLS Echo Reply檢測LSP的可用性。MPLS Echo Request中攜帶需要檢測的FEC(Forwarding Equivalence Class)信息,和其他屬於此FEC的報文一樣沿LSP傳送,從而實現對LSP的檢測。
為了更好地理解PTN,下文把PTN與熟悉的SDH業務層面告警類比一下,與大家共享。
2.1 PTN與MSTP告警對比
對應於業務模型,PTN的告警分為物理層、數據鏈路層、Tunnel層、PW層、仿真業務層5個層次。對應SDH的物理層、再生段復用段層、服務層、路徑層。上層功能的實現依賴於相鄰下層提供的服務。低層與高層同時有故障產生時,低層故障的消除是處理高層故障的基礎,物理層故障引發的告警禁止其他層故障引發的告警。SDH的告警與PTN的最根本的區別在於SDH的告警都是由位元組承載上報的,而PTN告警則是由協定控制上報的,但有相似之處,如圖2所示。
 PTN的運行維護
PTN的運行維護圖2 PTN與MSTP的告警對比
業務模型中,PW可類比VC12,Tunnel類比VC4管道;CES即電路仿真業務,也就是傳統的E1;告警可劃分為業務類告警、系列類通用類告警。表1按業務告警種類與SDH進行類比。
表1 各業務層告警對比
| MSTP告警 | SDH、PTN類比 結果 | PTN告警 | ||
| 業務層(VC12)(ETH/CES/IMA/ ATM) | TU_AIS、 T_ALOS、 UP_E1_AIS、 DOWN_E1_AIS等 | 繼承了SDH E1、ATM、IMA業務告警的特點 | PW_DOWN、 T_A LOS、 TU_AIS_VC12、 UP_E1_AIS、 DOWN_E1_AIS等 | PW&業務層(ET H/CES/IMA/ATM) |
| 服務層(VC4) | HP_SLM、 HP_UNEQ | 繼承了服務層SDH告警,新 增加了MPLS Tunnel類告警 | MPLS_TUNNEL_LOCV、 HP_SLM、 HP_UNEQ | Tunnel層(Tun nel/PW/MPLSAPS) |
| 再生段復用段層(開銷) | B1、B2誤碼檢測 告警; 復用段告警; IMA業務告警 | 繼承了SHD誤碼類,復用段類告警(線性),增加了多協定標籤交換(MPLS)告警,LAG類告警 | B1、B2誤碼檢測; 線性復用段告警; IMA業務告警; LAG_DOWN; MP_DOWN; ETH_APS_LOST; ETH_APS_PATH_MISMATCH; ETH_APS_SWITCH_FAIL; ETH_CFM_MISMERGE | 數據鏈路層(MLPPP / STM / LAG) |
| 物理層(單板 / ETH連線埠/SDH連線埠/ E1口) | R_LOS、 ETH_LOS、 T_ALOS、 LASER_MOD_ERR、 ETH_LINK_DOWN | 物理層告警與SDH相同,完全繼承了SDH光口、ETH電口、光口的習慣 | R_LOS、 ETH_LOS、 T_ALOS、 LASER_MOD_ERR、 ETH_LINK_DOWN | 物理層(單板/ ETH端/SDH連線埠/E1口) |
2.2 常見告警故障的處理方法
(1)CES業務常見告警故障的處理方法見表2。
表2 CES業務常見告警處理方法
| 告警名稱 | 產生原因 | 處理方法 |
| T_ALOS | E1信號丟失,主要上報在支路接口板上 | 環回E1 |
| UP_E1_AIS DOWN_E1_AIS | 分別是上行2M信號指示和下行2M信號指示,產生原因和SDH的相同 | 查看對端是否有TU_LOP_VC12、T_ALOS 或TU_AIS_VC12 告警。或者E1環回方式 |
| MPLS_TUNNEL_LOCV | MPLS_TUNNEL_LOCV為Tunnel 連通性丟失告警。連續3個周期內沒有收到希望的CV/FFD 報文時出現此告警。產生該告警時,該TUNNEL承載的業務已中斷。 原因1:往往是下層網路異常引起,例如物理鏈路故障、光模組故障等。 原因2:網路出現嚴重的擁塞 | 原因1:物理鏈路故障。①在網管上檢查該鏈路兩端網元是否存在單板或光模組相關的告警。若存在,消除這些告警,查看告警是否消除。 ②若告警未消除,查看光纖是否故障,更換故障的光纖。 原因2:網路出現嚴重擁塞。①選擇較大的“CC 測試傳送周期”的參數值,具體操作見本文的創建維護聯盟。 ②檢查故障Tunnel 的頻寬占用情況,如發現已滿,請增大Tunnel 頻寬配置或消除非法傳送大數據量的根源,查看告警是否消除 |
| TU_AIS_VC12 | 系統中存在更高階的告警,如R_LOS、R_LOF、HP_SLM、AU_AIS上游站點存在硬體故障告警; 交叉板故障; 對端站對應通道失效 | 按照產生原因點,逐步排除。先看是否有高級別的R_LOS、R_LOF、HP_SLM、AU_AIS 告警,然後看是否存在硬體故障支路板?交叉?最後對端對應通道?需要用到經驗法、替換法等。與SDH類似 |
業務中斷類常見告警原因:光纖、電纜故障,環境溫度變化、誤操作設定了光路的環回,誤操作更改、保護業務配置數據有誤。應急處理時應優先恢復業務。排除外部設備的問題後,將業務倒換到備用通道,復位單板、單站重啟、重新下發配置等。
(2)乙太網業務常見告警故障的處理方法見表3。
表3 乙太網業務常見告警故障處理
| 告警名稱 | 產生原因 | 處理方法 |
| ETH_LOS | 乙太網連線埠連線丟失,可能原因:乙太網連線埠的電纜或光纖沒有連線好;電纜或光纖故障;本端網元接收光功率過低;單板故障 | 屬於物理層故障類,查看物理連線,連線埠、單板故障;逐一排除 |
| MAC_FCS_EXC | MAC_FCS_EXC 為MAC 層檢測到誤碼越限告警。軟體定時檢測MAC 晶片接收位元組數和誤碼位元組數,計算誤碼是否超過門限,超過設定越限門限發出此報警 | ①檢測是否鏈路出現故障,維護光纖或網線,查看告警是否消除。 ②若告警仍未消除,檢測是否存在DOS 攻擊等,隔離DOS 攻擊源,查看告警是否消除。 ③若告警仍未消除,是否出現配置環路或物理等問題,解除環路,查看告警是否消除 |
續表
| 告警名稱 | 產生原因 | 處理方法 |
| ETH_LINK_DOWN | 乙太網連線錯誤,連線埠協商失敗;可能原因:連線埠模式不一致;電纜光纖連線故障;單板故障 | 對應需要查看和排除連線埠協商問題,主要關注連線埠模式,連線埠速率級別,最後使用替換法檢驗是否是硬體故障 |
| FLOW_OVER | 連線埠接收流量超限告警;可能原因為實際接收的連線埠流量大於設定的連線埠流量限值 | 增加連線埠頻寬 |
丟包類故障常見原因:光功率問題、環境溫度、數據業務連線埠協商故障、時鐘配置錯誤、業務流控配置。可通過查看光功率、RMON、丟包率等性能事件解決。
(3)MPLS保護倒換類告警原因見表4。
表4 MPLS保護倒換類告警原因
| 倒換告警 | 告警信息 | 故障原因 |
| ETH_APS_TYPE_MISMATCH | 保護類型信息不一致 | ①兩端配置的1+1或1:1模式不一致; ②兩端配置的單端或雙端倒換的模式不 一致; ③兩端配置的恢複式或非恢複式的模式不一致 |
| ETH_APS_PATH_MISMATCH | APS工作、保護路徑不一致 | ①保護組兩端設備配置的工作路徑、保護路徑不一致; ②物理鏈路上存在有錯連 |
| ETH_APS_SWITCH_FAIL | 保護倒換失敗 | 倒換失敗 |
| ETH_APS_LOST | APS幀丟失 | ①對方沒有配置保護; ②保護通道業務中斷 |
2.3 乙太網業務丟包類故障的處理方法
業務丟包、錯包的可能原因。
® 連線埠光功率異常或光功率不穩定,這是最常見的丟包原因。
® 時鐘未跟蹤或跟蹤源不穩定,會導致周期性丟包。
® Tunnel下一跳連線埠IP設定錯誤(如設定為本端連線埠,擴容或調整業務時)可能會導致丟包。
® 網路側發生擁塞,由於現網基本是輕載狀態,擁塞可能性較小。
排查業務丟包、錯包的思路:找出與“有問題的業務”走相近鏈路的業務,看是否有類似問題,以此縮小範圍。如圖3所示,如果業務A有丟包,業務B不丟,則問題應該在網元A與網元C之間。
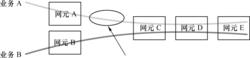 PTN的運行維護
PTN的運行維護圖3 排查業務丟包原因
2.4 OAM/Ping調試法
常用場景:數據業務通斷判斷。
維護中的工作難點主要在於如何能夠快速有效地排除故障。在眾多的故障中,以“業務不通”最為常見。應該如何著手解決呢?將PTN專線業務做成圖6-4所示的分段(PTN網路關於OAM的規劃主要涉及MPLS OAM、乙太網連線埠的OAM),適用於故障定位到單站,主要用於檢查網路連線是否可達,以及分析網路什麼地方發生了故障。
1)OAM排障常用步驟1—Tunnel OAM
 PTN的運行維護
PTN的運行維護圖4 PTN專線業務分段示意
圖4中深色標識部分是維護關鍵區域,因為這一區域的網元多,外部因素多(光纜、光模組、波分設備等),需考慮業務擴容、業務歸屬關係調整。
排障的主要工具:Tunnel OAM。
使用方法:到兩側(接入側、核心側)網元查看Tunnel OAM狀態。
結果分析:
® 兩側Tunnel OAM狀態都是“遠、近端可用”,該區域基本沒有問題。
® Tunnel OAM檢測有任何缺陷上報,根據“LSP缺陷位置”可鎖定故障位置。
® 查MPLS_TUNNEL_LOCV告警。Tunnel鏈路中斷解決措施:需要檢查Tunnel鏈路的連通性,發起LSP Ping確認故障節點/鏈路,並觀察Tunnel鏈路中其他節點的相關告警信息,需啟動OAM功能。
2)排障步驟2—LSP故障位置分析
 PTN的運行維護
PTN的運行維護圖5 LSP故障位置分析
圖5中黑框內的LSP缺陷位置指示了問題網元的LSR ID (GCP NODE ID)。然後在LSP缺陷位置及相鄰網元範圍內進一步排障步驟:
檢查光纖原因。
檢查業務告警:
® ETH_LINK_DOWN,ETH_LOS,R_LOS等鏈路異常告警;
® IN_PWR_ABN等光功率異常告警;
® HARD_BAD、BUS_ERR、BD STATUS等硬體異常告警。
檢查配置:
® 源/宿節點是否正確;
® 相鄰網元的出/入標籤是否一致;
® 下一條連線埠IP是否正確。
其他可能原因:
® 源/宿節點是否正確;
® 相鄰網元的出/入標籤是否一致;
® 下一條連線埠IP是否正確;
® 查看各連線埠收光功率的當前/歷史性能是否過低或過高:有可能連線埠收光功率接近但未超過閾值,導致無告警上報,所以需要查性能。
查看各NNI連線埠的設定,如圖6所示。
 PTN的運行維護
PTN的運行維護圖6 各NNI連線埠的設定
ETH OAM的簡易操作步驟:
兩端網元發起LB測試,用於命令觸發的連通性檢查,對乙太網業務執行不中斷業務環回檢測(LB),可以檢驗業務的連通性情況,以便定位和修復故障。
如圖7所示,只需輸入對端UNI連線埠MAC地址就可以啟動測試了,其他參數可用默認。OAM功能產生的告警概覽見表5。
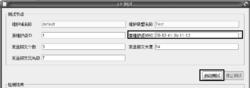 PTN的運行維護
PTN的運行維護圖7 ETH OAM的簡易操作界面
表5 OAM產生的告警概覽
| MELS OAM | MPLS_TUNNEL_LOCV告警 | 含義:Tunnel鏈路中斷。 解決措施:需要檢查Tunnel鏈路的連通性,發起LSP Ping確認故障節點/鏈路,並觀察Tunnel鏈路中其他節點的相關告警信息 |
| MPLS 狀態 | Init(初始)狀態 | Ingress端沒有使能OAM或者Tunnel鏈路中斷 |
| Available(可用)狀態 | Tunnel狀態正常 | |
| Unavailable(不可用)狀態 | Tunnel狀態不可用,需要檢查Tunnel鏈路的連通性,發起LSP Ping確認故障節點/鏈路,並觀察Tunnel鏈路中其他節點的相關告警信息 | |
| ETH OAM | ETH_CFM_LOC告警 | 含義:ETH業務中斷。 解決措施:需要發起ETH LB進行故障確認,發起LT進行故障定位;對於MPLS承載的ETH業務,需要觀察MPLS Tunnel的連通性 |
| ETH_CFM_RDI告警 | 含義:對端檢測到ETH業務的告警後的回告指示。 解決措施:需要在對端進行告警確認和排查操作 | |
| ETH_EFM_DF告警 | 含義:ETH鏈路發現失敗。 解決措施:檢查兩端的ETH Link OAM的配置是否一致,檢查ETH鏈路的連通性 | |
| ETH_EFM_EVENT告警 | 含義:ETH鏈路存在誤碼。 解決措施:對端網元檢測到連線埠有誤碼,需要在對端網元確認其接收鏈路是否正常 |
2.5 環回逐段定位法
常用場景:CES業務、SDH業務出現故障時,在支路或線路環回,定位故障原因到單站。環回操作會導致業務中斷,僅SDH類業務使用。
注意:數據類定位的方法,為避免環回造成的網路風暴,使用ETH OAM功能,維護過程中不使用環回。
SDH接口和PDH接口在維護中使用內環回和外環回。網管中環回界面與SDH近似。
3. PTN例行監控
網路維護工程師在維護PTN時,比MSTP網路更關注RMON性能等數據。
T2000網管的日常維護項目見表6。
表6 網管日常維護項目
| 維護責任人 | 維護地點 | 維護項目 | 周期 |
| 網管操作員 | 網管中心 | 檢查網元和單板狀態 | 每天 |
| 瀏覽全網告警 | 每天 | ||
| 瀏覽異常事件 | 每天 | ||
| 瀏覽當前性能 | 每天 |
續表
| 維護責任人 | 維護地點 | 維護項目 | 周期 |
| 瀏覽RMON統計組性能 | 每天 | ||
| 檢查光接口的光功率 | 每天 | ||
| 瀏覽歷史性能 | 每周 | ||
| 瀏覽RMON歷史性能 | 每周(連線埠流量統計、連線埠丟包、業務流統計) | ||
| 備份T2000的MO數據 | 每周 | ||
| 備份網元資料庫 | 每雙周 |
備份網元資料庫:PTN在面對災難性故障,即出現單主控板失效、資料庫損壞等故障時,快速恢復業務的方法是資料庫下載恢復。在網管資料庫備份工具中,可設定定期任務,自動定期上載網元資料庫到網管電腦中。另外在每次大業務量配置(包括單站配置以及全網配置)修改後,都要進行一次網元資料庫的備份操作,保證備份資料庫最大限度地與網元一致。
備件單板更換:SDH設備的備件單板,需定期拿出來隨現網進行升級更新;而PTN的單板,只要插入到子架中就能夠自動向主控軟體包申請更新自身的單板軟體,節省了備件單板維護的工作。
日常維護過程經驗總結:數據類設備功耗大,往往需要清理防塵網,當其部署在末端基站機房時,需考慮這項工作的維護人力投入—路途遠、工時成本高。杭州移動套用的PTN910/950不需要清理防塵網,建議對末端設備考慮免清理防塵網的設計。
