機率分布的困惑度
離散機率分布p的困惑度由下式給出
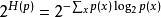 困惑度
困惑度其中H(p) 是該分布的熵,x遍歷事件空間。
隨機變數X的複雜度由其所有可能的取值x定義。
一個特殊的例子是k面均勻骰子的機率分布,它的困惑度恰好是k。一個擁有k困惑度的隨機變數有著和k面均勻骰子一樣多的不確定性,並且可以說該隨機變數有著k個困惑度的取值(k-ways perplexed)。(在有限樣本空間離散隨機變數的機率分布中,均勻分布有著最大的熵)
困惑度有時也被用來衡量一個預測問題的難易程度。但這個方法不總是精確的。例如:在機率分布B(1,P=0.9)中,即取得1的機率是0.9,取得0的機率是0.1。
機率模型的困惑度
用一個機率模型q去估計真實機率分布p,那么可以通過測試集中的樣本來定義這個機率模型的困惑度。
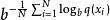 困惑度
困惑度其中測試樣本x1, x2, …, xN是來自於真實機率分布p的觀測值,b通常取2。因此,低的困惑度表示q對p擬合的越好,當模型q看到測試樣本時,它會不會“感到”那么“困惑”。
我們指出,指數部分是交叉熵。
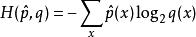 困惑度
困惑度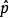 困惑度
困惑度其中表示我們對真實分布下樣本點x出現機率的估計。比如用p(x)=n/N.
每個分詞的困惑度
在自然語言處理中,困惑度是用來衡量語言機率模型優劣的一個方法。一個語言機率模型可以看成是在整過句子或者文段上的機率分布。(譯者:例如每個分詞位置上有一個機率分布,這個機率分布表示了每個詞在這個位置上出現的機率;或者每個句子位置上有一個機率分布,這個機率分布表示了所有可能句子在這個位置上出現的機率)
比如,i這個句子位置上的機率分布的信息熵可能是190,或者說,i這個句子位置上出現的句子平均要用190 bits去編碼,那么這個位置上的機率分布的困惑度就是2^(190)。(譯者:相當於投擲一個2^(190)面篩子的不確定性)通常,我們會考慮句子有不同的長度,所以我們會計算每個分詞上的困惑度。比如,一個測試集上共有1000個單詞,並且可以用7.95個bits給每個單詞編碼,那么我們可以說這個模型上每個詞有2^(7.95)=247 困惑度。相當於在每個詞語位置上都有投擲一個247面骰子的不確定性。
在Brown corpus (1 million words of American English of varying topics and genres) 上報告的最低的困惑度就是247per word,使用的是一個trigram model(三元語法模型)。在一個特定領域的語料中,常常可以得到更低的困惑度 。
要注意的是,這個模型用的是三元語法。直接預測下一個單詞是”the”的正確率是7%。但如果直接套用上面的結果,算出來這個預測是正確的機率是1/247=0.4%,這就錯了。(譯者:不是說算出來就一定是0.4%,而是說這樣算本身是錯的)因為直接預測下一個詞是”the“的話,我們是在使用一元語法,而247是來源於三元語法的。當我們在使用三元語法的時候,會考慮三元語法的統計數據,這樣做出來的預測會不一樣並且通常有更好的正確率。
